 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards the Success Rate of One: Real-time Unconstrained Salient Object Detection
Paper and Code
Aug 02, 2017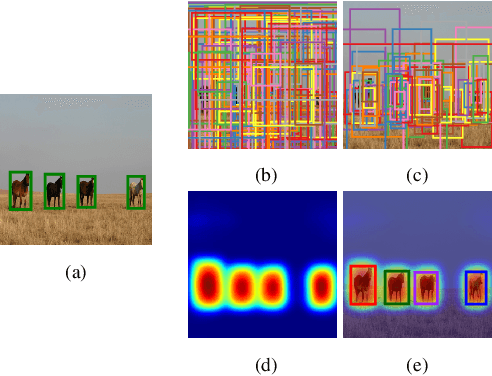
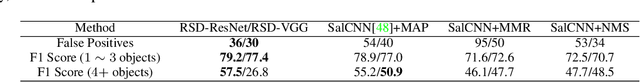


In this work, we propose an efficient and effective approach for unconstrained salient object detection in images using deep convolutional neural networks. Instead of generating thousands of candidate bounding boxes and refining them, our network directly learns to generate the saliency map containing the exact number of salient objects. During training, we convert the ground-truth rectangular boxes to Gaussian distributions that better capture the ROI regarding individual salient objects. During inference, the network predicts Gaussian distributions centered at salient objects with an appropriate covariance, from which bounding boxes are easily inferred. Notably, our network performs saliency map prediction without pixel-level annotations, salient object detection without object proposals, and salient object subitizing simultaneously, all in a single pass within a unified framework. Extensive experiments show that our approach outperforms existing methods on various datasets by a large margin, and achieves more than 100 fps with VGG16 network on a single GPU during inference.