 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Learning for Fine-grained Image Search
Paper and Code
Jul 06, 2018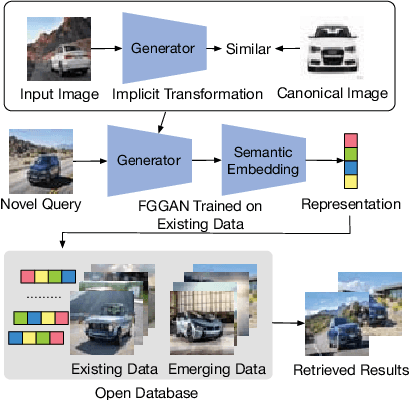



Fine-grained image search is still a challenging problem due to the difficulty in capturing subtle differences regardless of pose variations of objects from fine-grained categories. In practice, a dynamic inventory with new fine-grained categories adds another dimension to this challenge. In this work, we propose an end-to-end network, called FGGAN, that learns discriminative representations by implicitly learning a geometric transformation from multi-view images for fine-grained image search. We integrate a generative adversarial network (GAN) that can automatically handle complex view and pose variations by converting them to a canonical view without any predefined transformations. Moreover, in an open-set scenario, our network is able to better match images from unseen and unknown fine-grained categories. Extensive experiments on two public datasets and a newly collected dataset have demonstrated the outstanding robust performance of the proposed FGGAN in both closed-set and open-set scenarios, providing as much as 10% relative improvement compared to baselines.