 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Caricature via Semantic Shape Transform
Aug 13, 2020

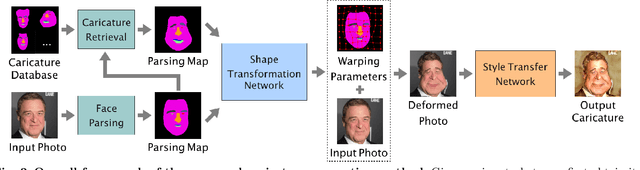
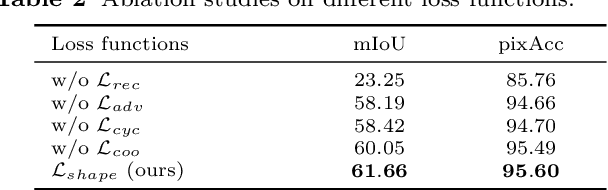
Caricature is an artistic drawing created to abstract or exaggerate facial features of a person. Rendering visually pleasing caricatures is a difficult task that requires professional skills, and thus it is of great interest to design a method to automatically generate such drawings. To deal with large shape changes, we propose an algorithm based on a semantic shape transform to produce diverse and plausible shape exaggerations. Specifically, we predict pixel-wise semantic correspondences and perform image warping on the input photo to achieve dense shape transformation. We show that the proposed framework is able to render visually pleasing shape exaggerations while maintaining their facial structures. In addition, our model allows users to manipulate the shape via the semantic map. We demonstrate the effectiveness of our approach on a large photograph-caricature benchmark dataset with comparisons to the state-of-the-art methods.
Mixup-CAM: Weakly-supervised Semantic Segmentation via Uncertainty Regularization
Aug 03, 2020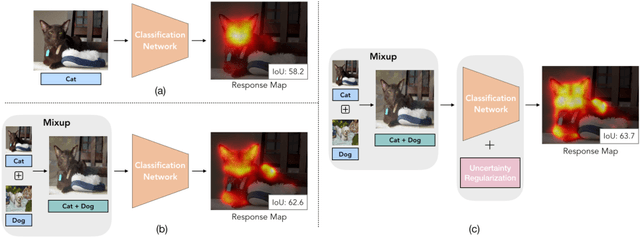
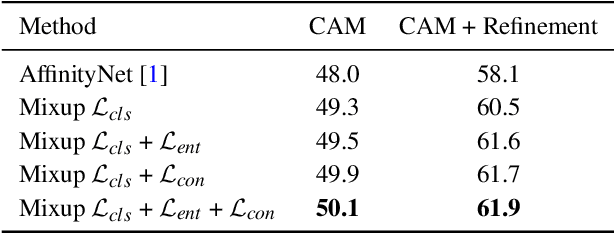
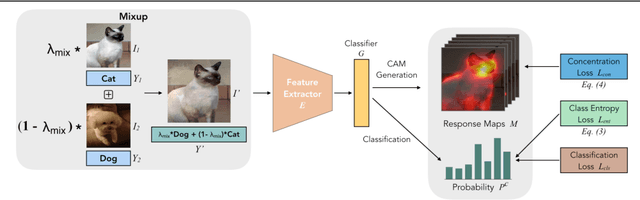
Obtaining object response maps is one important step to achieve weakly-supervised semantic segmentation using image-level labels. However, existing methods rely on the classification task, which could result in a response map only attending on discriminative object regions as the network does not need to see the entire object for optimizing the classification loss. To tackle this issue, we propose a principled and end-to-end train-able framework to allow the network to pay attention to other parts of the object, while producing a more complete and uniform response map. Specifically, we introduce the mixup data augmentation scheme into the classification network and design two uncertainty regularization terms to better interact with the mixup strategy. In experiments, we conduct extensive analysis to demonstrate the proposed method and show favorable performance against state-of-the-art approaches.
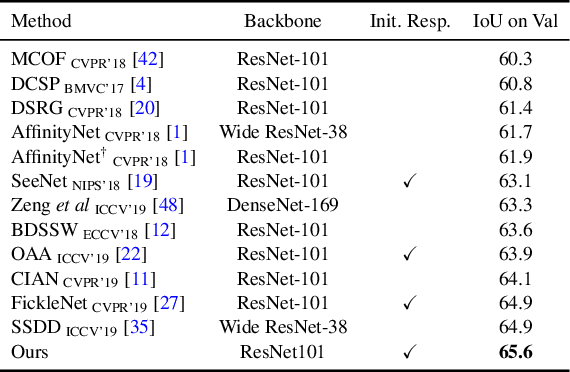
Weakly-Supervised Semantic Segmentation via Sub-category Exploration
Aug 03, 2020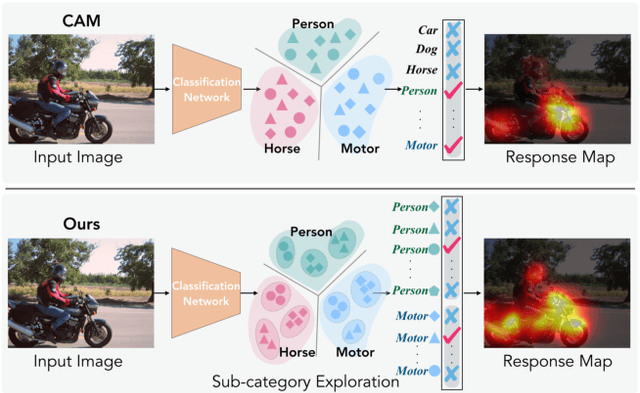
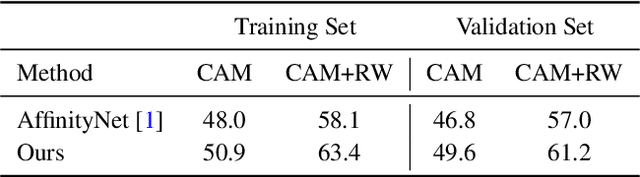
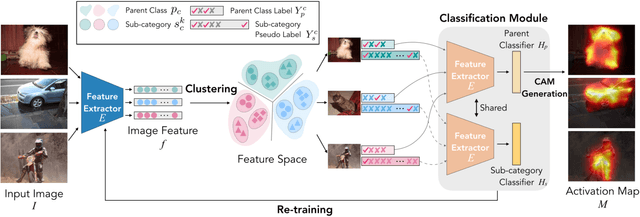
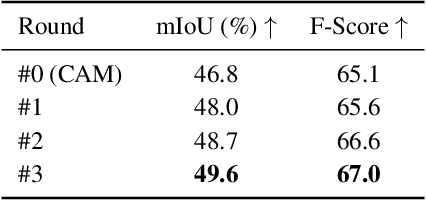
Existing weakly-supervised semantic segmentation methods using image-level annotations typically rely on initial responses to locate object regions. However, such response maps generated by the classification network usually focus on discriminative object parts, due to the fact that the network does not need the entire object for optimizing the objective function. To enforce the network to pay attention to other parts of an object, we propose a simple yet effective approach that introduces a self-supervised task by exploiting the sub-category information. Specifically, we perform clustering on image features to generate pseudo sub-categories labels within each annotated parent class, and construct a sub-category objective to assign the network to a more challenging task. By iteratively clustering image features, the training process does not limit itself to the most discriminative object parts, hence improving the quality of the response maps. We conduct extensive analysis to validate the proposed method and show that our approach performs favorably against the state-of-the-art approaches.