 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Voxtral Realtime
Feb 11, 2026We introduce Voxtral Realtime, a natively streaming automatic speech recognition model that matches offline transcription quality at sub-second latency. Unlike approaches that adapt offline models through chunking or sliding windows, Voxtral Realtime is trained end-to-end for streaming, with explicit alignment between audio and text streams. Our architecture builds on the Delayed Streams Modeling framework, introducing a new causal audio encoder and Ada RMS-Norm for improved delay conditioning. We scale pretraining to a large-scale dataset spanning 13 languages. At a delay of 480ms, Voxtral Realtime achieves performance on par with Whisper, the most widely deployed offline transcription system. We release the model weights under the Apache 2.0 license.
Ministral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
Voxtral
Jul 17, 2025We present Voxtral Mini and Voxtral Small, two multimodal audio chat models. Voxtral is trained to comprehend both spoken audio and text documents, achieving state-of-the-art performance across a diverse range of audio benchmarks, while preserving strong text capabilities. Voxtral Small outperforms a number of closed-source models, while being small enough to run locally. A 32K context window enables the model to handle audio files up to 40 minutes in duration and long multi-turn conversations. We also contribute three benchmarks for evaluating speech understanding models on knowledge and trivia. Both Voxtral models are released under Apache 2.0 license.
Magistral
Jun 12, 2025



We introduce Magistral, Mistral's first reasoning model and our own scalable reinforcement learning (RL) pipeline. Instead of relying on existing implementations and RL traces distilled from prior models, we follow a ground up approach, relying solely on our own models and infrastructure. Notably, we demonstrate a stack that enabled us to explore the limits of pure RL training of LLMs, present a simple method to force the reasoning language of the model, and show that RL on text data alone maintains most of the initial checkpoint's capabilities. We find that RL on text maintains or improves multimodal understanding, instruction following and function calling. We present Magistral Medium, trained for reasoning on top of Mistral Medium 3 with RL alone, and we open-source Magistral Small (Apache 2.0) which further includes cold-start data from Magistral Medium.
Dissociating Artificial Intelligence from Artificial Consciousness
Dec 05, 2024Developments in machine learning and computing power suggest that artificial general intelligence is within reach. This raises the question of artificial consciousness: if a computer were to be functionally equivalent to a human, being able to do all we do, would it experience sights, sounds, and thoughts, as we do when we are conscious? Answering this question in a principled manner can only be done on the basis of a theory of consciousness that is grounded in phenomenology and that states the necessary and sufficient conditions for any system, evolved or engineered, to support subjective experience. Here we employ Integrated Information Theory (IIT), which provides principled tools to determine whether a system is conscious, to what degree, and the content of its experience. We consider pairs of systems constituted of simple Boolean units, one of which -- a basic stored-program computer -- simulates the other with full functional equivalence. By applying the principles of IIT, we demonstrate that (i) two systems can be functionally equivalent without being phenomenally equivalent, and (ii) that this conclusion is not dependent on the simulated system's function. We further demonstrate that, according to IIT, it is possible for a digital computer to simulate our behavior, possibly even by simulating the neurons in our brain, without replicating our experience. This contrasts sharply with computational functionalism, the thesis that performing computations of the right kind is necessary and sufficient for consciousness.
Crystal: Illuminating LLM Abilities on Language and Code
Nov 06, 2024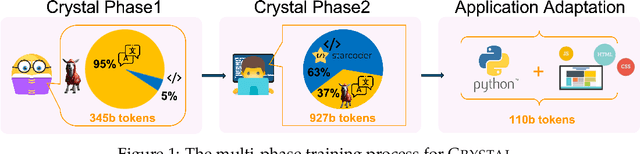
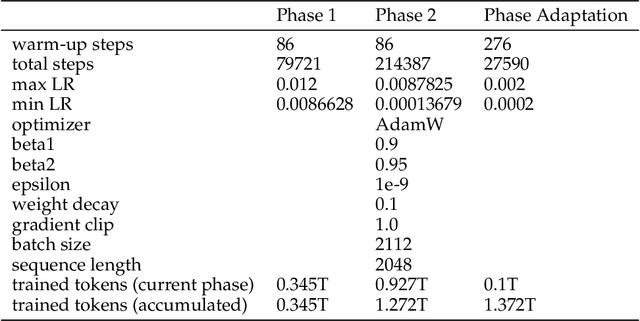
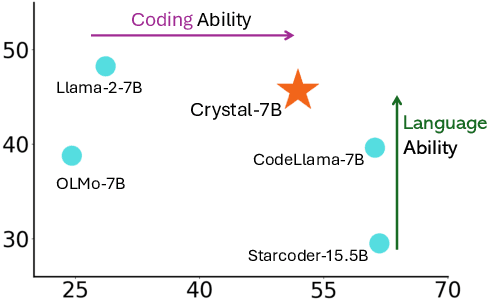
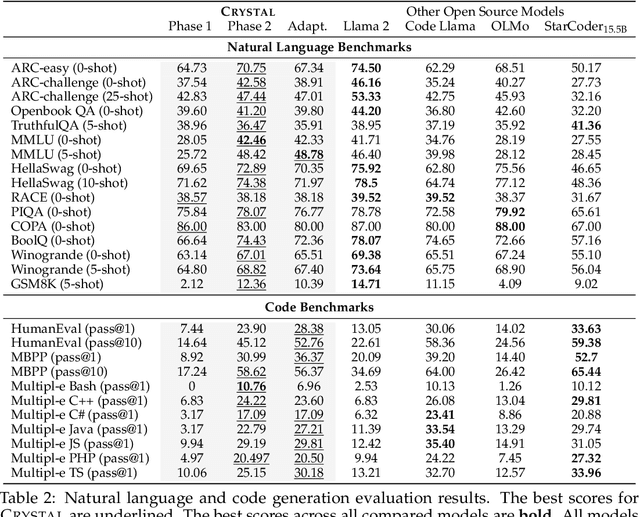
Large Language Models (LLMs) specializing in code generation (which are also often referred to as code LLMs), e.g., StarCoder and Code Llama, play increasingly critical roles in various software development scenarios. It is also crucial for code LLMs to possess both code generation and natural language abilities for many specific applications, such as code snippet retrieval using natural language or code explanations. The intricate interaction between acquiring language and coding skills complicates the development of strong code LLMs. Furthermore, there is a lack of thorough prior studies on the LLM pretraining strategy that mixes code and natural language. In this work, we propose a pretraining strategy to enhance the integration of natural language and coding capabilities within a single LLM. Specifically, it includes two phases of training with appropriately adjusted code/language ratios. The resulting model, Crystal, demonstrates remarkable capabilities in both domains. Specifically, it has natural language and coding performance comparable to that of Llama 2 and Code Llama, respectively. Crystal exhibits better data efficiency, using 1.4 trillion tokens compared to the more than 2 trillion tokens used by Llama 2 and Code Llama. We verify our pretraining strategy by analyzing the training process and observe consistent improvements in most benchmarks. We also adopted a typical application adaptation phase with a code-centric data mixture, only to find that it did not lead to enhanced performance or training efficiency, underlining the importance of a carefully designed data recipe. To foster research within the community, we commit to open-sourcing every detail of the pretraining, including our training datasets, code, loggings and 136 checkpoints throughout the training.
Pixtral 12B
Oct 09, 2024



We introduce Pixtral-12B, a 12--billion-parameter multimodal language model. Pixtral-12B is trained to understand both natural images and documents, achieving leading performance on various multimodal benchmarks, surpassing a number of larger models. Unlike many open-source models, Pixtral is also a cutting-edge text model for its size, and does not compromise on natural language performance to excel in multimodal tasks. Pixtral uses a new vision encoder trained from scratch, which allows it to ingest images at their natural resolution and aspect ratio. This gives users flexibility on the number of tokens used to process an image. Pixtral is also able to process any number of images in its long context window of 128K tokens. Pixtral 12B substanially outperforms other open models of similar sizes (Llama-3.2 11B \& Qwen-2-VL 7B). It also outperforms much larger open models like Llama-3.2 90B while being 7x smaller. We further contribute an open-source benchmark, MM-MT-Bench, for evaluating vision-language models in practical scenarios, and provide detailed analysis and code for standardized evaluation protocols for multimodal LLMs. Pixtral-12B is released under Apache 2.0 license.
Cerebras-GPT: Open Compute-Optimal Language Models Trained on the Cerebras Wafer-Scale Cluster
Apr 06, 2023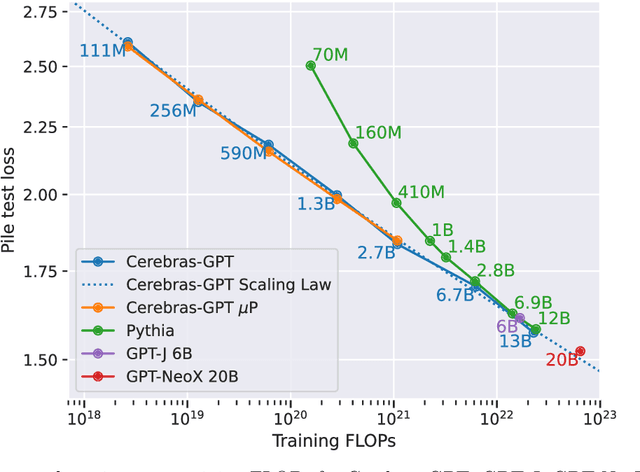
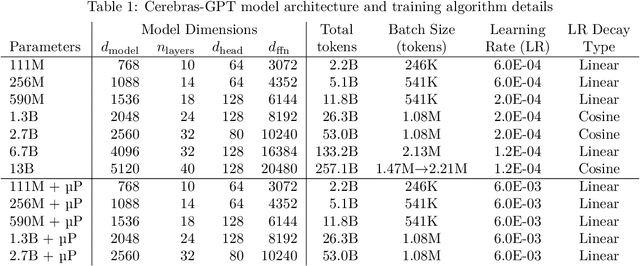
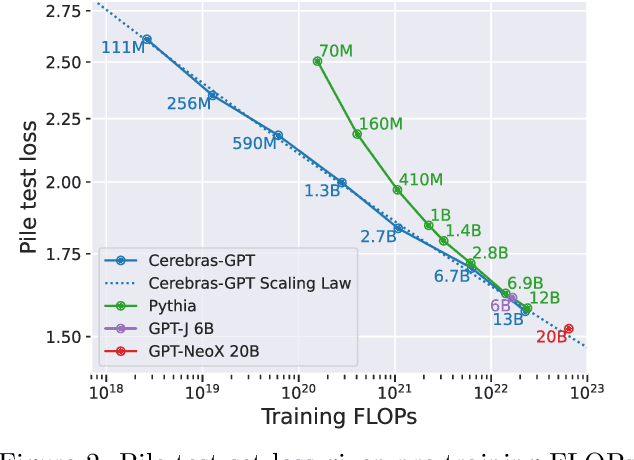
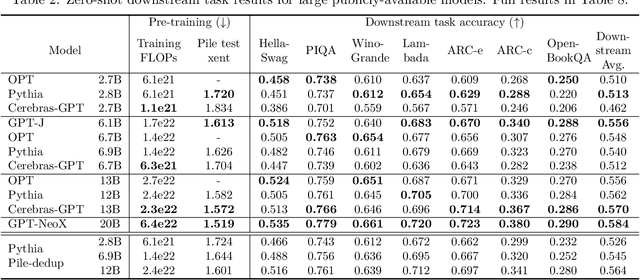
We study recent research advances that improve large language models through efficient pre-training and scaling, and open datasets and tools. We combine these advances to introduce Cerebras-GPT, a family of open compute-optimal language models scaled from 111M to 13B parameters. We train Cerebras-GPT models on the Eleuther Pile dataset following DeepMind Chinchilla scaling rules for efficient pre-training (highest accuracy for a given compute budget). We characterize the predictable power-law scaling and compare Cerebras-GPT with other publicly-available models to show all Cerebras-GPT models have state-of-the-art training efficiency on both pre-training and downstream objectives. We describe our learnings including how Maximal Update Parameterization ($\mu$P) can further improve large model scaling, improving accuracy and hyperparameter predictability at scale. We release our pre-trained models and code, making this paper the first open and reproducible work comparing compute-optimal model scaling to models trained on fixed dataset sizes. Cerebras-GPT models are available on HuggingFace: https://huggingface.co/cerebras.
SPDF: Sparse Pre-training and Dense Fine-tuning for Large Language Models
Mar 18, 2023

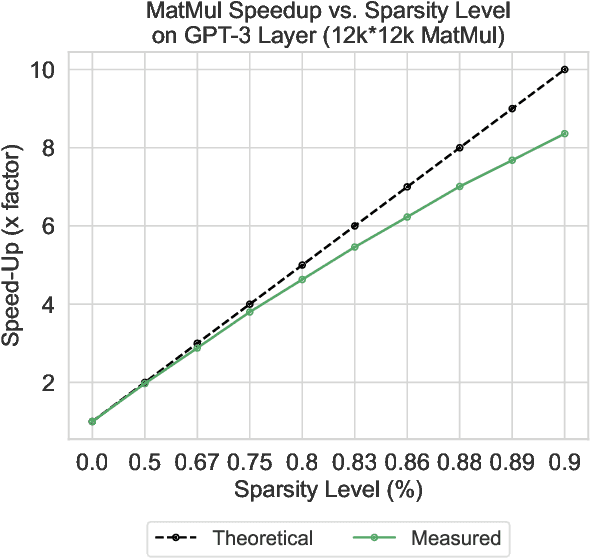
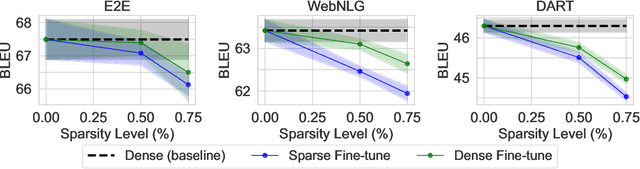
The pre-training and fine-tuning paradigm has contributed to a number of breakthroughs in Natural Language Processing (NLP). Instead of directly training on a downstream task, language models are first pre-trained on large datasets with cross-domain knowledge (e.g., Pile, MassiveText, etc.) and then fine-tuned on task-specific data (e.g., natural language generation, text summarization, etc.). Scaling the model and dataset size has helped improve the performance of LLMs, but unfortunately, this also leads to highly prohibitive computational costs. Pre-training LLMs often require orders of magnitude more FLOPs than fine-tuning and the model capacity often remains the same between the two phases. To achieve training efficiency w.r.t training FLOPs, we propose to decouple the model capacity between the two phases and introduce Sparse Pre-training and Dense Fine-tuning (SPDF). In this work, we show the benefits of using unstructured weight sparsity to train only a subset of weights during pre-training (Sparse Pre-training) and then recover the representational capacity by allowing the zeroed weights to learn (Dense Fine-tuning). We demonstrate that we can induce up to 75% sparsity into a 1.3B parameter GPT-3 XL model resulting in a 2.5x reduction in pre-training FLOPs, without a significant loss in accuracy on the downstream tasks relative to the dense baseline. By rigorously evaluating multiple downstream tasks, we also establish a relationship between sparsity, task complexity, and dataset size. Our work presents a promising direction to train large GPT models at a fraction of the training FLOPs using weight sparsity while retaining the benefits of pre-trained textual representations for downstream tasks.