 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePower Lines: Scaling Laws for Weight Decay and Batch Size in LLM Pre-training
May 19, 2025



Efficient LLM pre-training requires well-tuned hyperparameters (HPs), including learning rate {\eta} and weight decay {\lambda}. We study scaling laws for HPs: formulas for how to scale HPs as we scale model size N, dataset size D, and batch size B. Recent work suggests the AdamW timescale, B/({\eta}{\lambda}D), should remain constant across training settings, and we verify the implication that optimal {\lambda} scales linearly with B, for a fixed N,D. However, as N,D scale, we show the optimal timescale obeys a precise power law in the tokens-per-parameter ratio, D/N. This law thus provides a method to accurately predict {\lambda}opt in advance of large-scale training. We also study scaling laws for optimal batch size Bopt (the B enabling lowest loss at a given N,D) and critical batch size Bcrit (the B beyond which further data parallelism becomes ineffective). In contrast with prior work, we find both Bopt and Bcrit scale as power laws in D, independent of model size, N. Finally, we analyze how these findings inform the real-world selection of Pareto-optimal N and D under dual training time and compute objectives.
Llama-3-Nanda-10B-Chat: An Open Generative Large Language Model for Hindi
Apr 08, 2025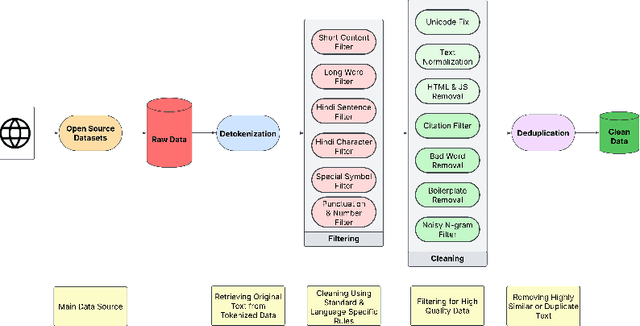

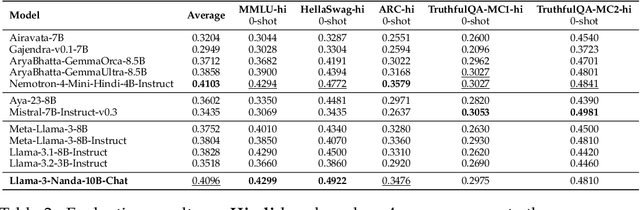

Developing high-quality large language models (LLMs) for moderately resourced languages presents unique challenges in data availability, model adaptation, and evaluation. We introduce Llama-3-Nanda-10B-Chat, or Nanda for short, a state-of-the-art Hindi-centric instruction-tuned generative LLM, designed to push the boundaries of open-source Hindi language models. Built upon Llama-3-8B, Nanda incorporates continuous pre-training with expanded transformer blocks, leveraging the Llama Pro methodology. A key challenge was the limited availability of high-quality Hindi text data; we addressed this through rigorous data curation, augmentation, and strategic bilingual training, balancing Hindi and English corpora to optimize cross-linguistic knowledge transfer. With 10 billion parameters, Nanda stands among the top-performing open-source Hindi and multilingual models of similar scale, demonstrating significant advantages over many existing models. We provide an in-depth discussion of training strategies, fine-tuning techniques, safety alignment, and evaluation metrics, demonstrating how these approaches enabled Nanda to achieve state-of-the-art results. By open-sourcing Nanda, we aim to advance research in Hindi LLMs and support a wide range of real-world applications across academia, industry, and public services.
Llama-3.1-Sherkala-8B-Chat: An Open Large Language Model for Kazakh
Mar 03, 2025Llama-3.1-Sherkala-8B-Chat, or Sherkala-Chat (8B) for short, is a state-of-the-art instruction-tuned open generative large language model (LLM) designed for Kazakh. Sherkala-Chat (8B) aims to enhance the inclusivity of LLM advancements for Kazakh speakers. Adapted from the LLaMA-3.1-8B model, Sherkala-Chat (8B) is trained on 45.3B tokens across Kazakh, English, Russian, and Turkish. With 8 billion parameters, it demonstrates strong knowledge and reasoning abilities in Kazakh, significantly outperforming existing open Kazakh and multilingual models of similar scale while achieving competitive performance in English. We release Sherkala-Chat (8B) as an open-weight instruction-tuned model and provide a detailed overview of its training, fine-tuning, safety alignment, and evaluation, aiming to advance research and support diverse real-world applications.
Straight to Zero: Why Linearly Decaying the Learning Rate to Zero Works Best for LLMs
Feb 21, 2025LLMs are commonly trained with a learning rate (LR) warmup, followed by cosine decay to 10% of the maximum (10x decay). In a large-scale empirical study, we show that under an optimal peak LR, a simple linear decay-to-zero (D2Z) schedule consistently outperforms other schedules when training at compute-optimal dataset sizes. D2Z is superior across a range of model sizes, batch sizes, datasets, and vocabularies. Benefits increase as dataset size increases. Leveraging a novel interpretation of AdamW as an exponential moving average of weight updates, we show how linear D2Z optimally balances the demands of early training (moving away from initial conditions) and late training (averaging over more updates in order to mitigate gradient noise). In experiments, a 610M-parameter model trained for 80 tokens-per-parameter (TPP) using D2Z achieves lower loss than when trained for 200 TPP using 10x decay, corresponding to an astonishing 60% compute savings. Models such as Llama2-7B, trained for 286 TPP with 10x decay, could likely have saved a majority of compute by training with D2Z.
Bilingual Adaptation of Monolingual Foundation Models
Jul 13, 2024
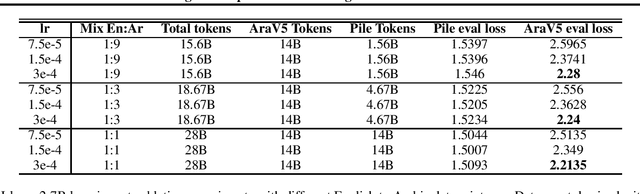


We present an efficient method for adapting a monolingual Large Language Model (LLM) to another language, addressing challenges of catastrophic forgetting and tokenizer limitations. We focus this study on adapting Llama 2 to Arabic. Our two-stage approach begins with expanding the vocabulary and training only the embeddings matrix, followed by full model continual pretraining on a bilingual corpus. By continually pretraining on a mix of Arabic and English corpora, the model retains its proficiency in English while acquiring capabilities in Arabic. Our approach results in significant improvements in Arabic and slight enhancements in English, demonstrating cost-effective cross-lingual transfer. We also perform extensive ablations on embedding initialization techniques, data mix ratios, and learning rates and release a detailed training recipe.
Med42 -- Evaluating Fine-Tuning Strategies for Medical LLMs: Full-Parameter vs. Parameter-Efficient Approaches
Apr 23, 2024



This study presents a comprehensive analysis and comparison of two predominant fine-tuning methodologies - full-parameter fine-tuning and parameter-efficient tuning - within the context of medical Large Language Models (LLMs). We developed and refined a series of LLMs, based on the Llama-2 architecture, specifically designed to enhance medical knowledge retrieval, reasoning, and question-answering capabilities. Our experiments systematically evaluate the effectiveness of these tuning strategies across various well-known medical benchmarks. Notably, our medical LLM Med42 showed an accuracy level of 72% on the US Medical Licensing Examination (USMLE) datasets, setting a new standard in performance for openly available medical LLMs. Through this comparative analysis, we aim to identify the most effective and efficient method for fine-tuning LLMs in the medical domain, thereby contributing significantly to the advancement of AI-driven healthcare applications.
Improving Resnet-9 Generalization Trained on Small Datasets
Sep 07, 2023This paper presents our proposed approach that won the first prize at the ICLR competition on Hardware Aware Efficient Training. The challenge is to achieve the highest possible accuracy in an image classification task in less than 10 minutes. The training is done on a small dataset of 5000 images picked randomly from CIFAR-10 dataset. The evaluation is performed by the competition organizers on a secret dataset with 1000 images of the same size. Our approach includes applying a series of technique for improving the generalization of ResNet-9 including: sharpness aware optimization, label smoothing, gradient centralization, input patch whitening as well as metalearning based training. Our experiments show that the ResNet-9 can achieve the accuracy of 88% while trained only on a 10% subset of CIFAR-10 dataset in less than 10 minuets
Cerebras-GPT: Open Compute-Optimal Language Models Trained on the Cerebras Wafer-Scale Cluster
Apr 06, 2023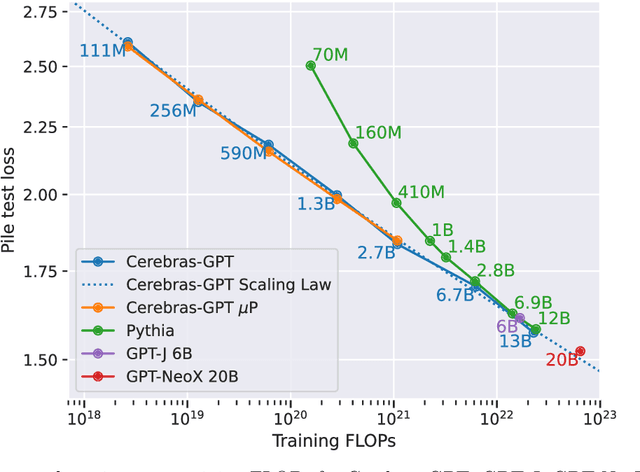
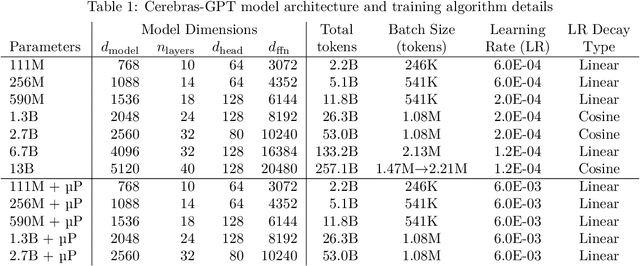
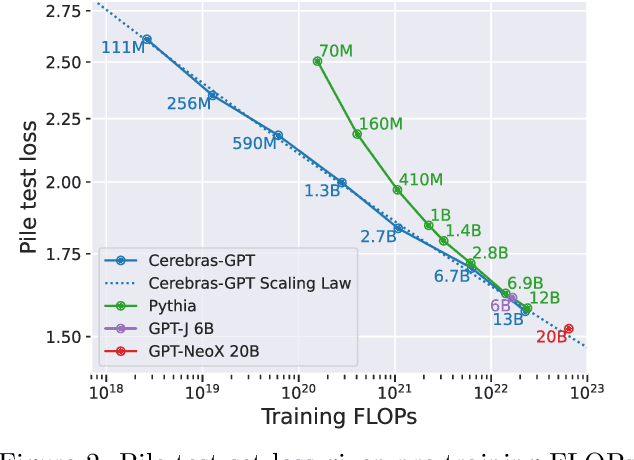
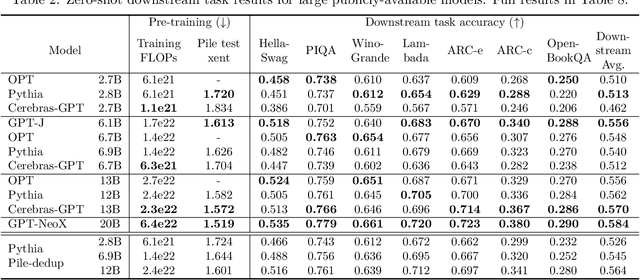
We study recent research advances that improve large language models through efficient pre-training and scaling, and open datasets and tools. We combine these advances to introduce Cerebras-GPT, a family of open compute-optimal language models scaled from 111M to 13B parameters. We train Cerebras-GPT models on the Eleuther Pile dataset following DeepMind Chinchilla scaling rules for efficient pre-training (highest accuracy for a given compute budget). We characterize the predictable power-law scaling and compare Cerebras-GPT with other publicly-available models to show all Cerebras-GPT models have state-of-the-art training efficiency on both pre-training and downstream objectives. We describe our learnings including how Maximal Update Parameterization ($\mu$P) can further improve large model scaling, improving accuracy and hyperparameter predictability at scale. We release our pre-trained models and code, making this paper the first open and reproducible work comparing compute-optimal model scaling to models trained on fixed dataset sizes. Cerebras-GPT models are available on HuggingFace: https://huggingface.co/cerebras.