 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuran-MD: A Fine-Grained Multilingual Multimodal Dataset of the Quran
Jan 25, 2026We present Quran MD, a comprehensive multimodal dataset of the Quran that integrates textual, linguistic, and audio dimensions at the verse and word levels. For each verse (ayah), the dataset provides its original Arabic text, English translation, and phonetic transliteration. To capture the rich oral tradition of Quranic recitation, we include verse-level audio from 32 distinct reciters, reflecting diverse recitation styles and dialectical nuances. At the word level, each token is paired with its corresponding Arabic script, English translation, transliteration, and an aligned audio recording, allowing fine-grained analysis of pronunciation, phonology, and semantic context. This dataset supports various applications, including natural language processing, speech recognition, text-to-speech synthesis, linguistic analysis, and digital Islamic studies. Bridging text and audio modalities across multiple reciters, this dataset provides a unique resource to advance computational approaches to Quranic recitation and study. Beyond enabling tasks such as ASR, tajweed detection, and Quranic TTS, it lays the foundation for multimodal embeddings, semantic retrieval, style transfer, and personalized tutoring systems that can support both research and community applications. The dataset is available at https://huggingface.co/datasets/Buraaq/quran-audio-text-dataset
Named Clinical Entity Recognition Benchmark
Oct 07, 2024
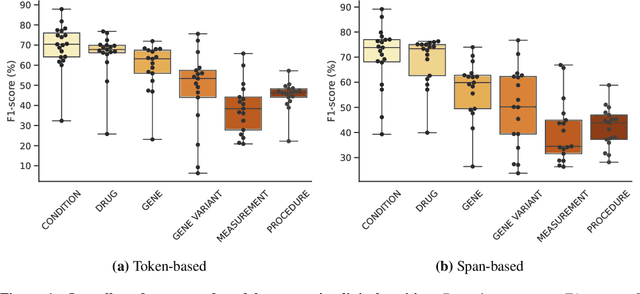

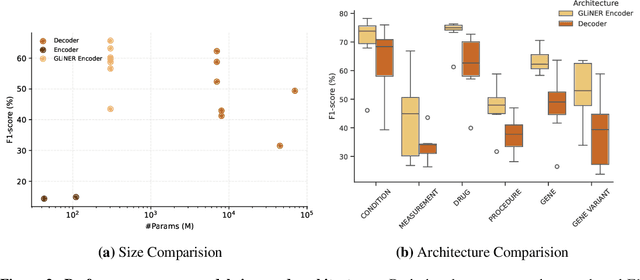
This technical report introduces a Named Clinical Entity Recognition Benchmark for evaluating language models in healthcare, addressing the crucial natural language processing (NLP) task of extracting structured information from clinical narratives to support applications like automated coding, clinical trial cohort identification, and clinical decision support. The leaderboard provides a standardized platform for assessing diverse language models, including encoder and decoder architectures, on their ability to identify and classify clinical entities across multiple medical domains. A curated collection of openly available clinical datasets is utilized, encompassing entities such as diseases, symptoms, medications, procedures, and laboratory measurements. Importantly, these entities are standardized according to the Observational Medical Outcomes Partnership (OMOP) Common Data Model, ensuring consistency and interoperability across different healthcare systems and datasets, and a comprehensive evaluation of model performance. Performance of models is primarily assessed using the F1-score, and it is complemented by various assessment modes to provide comprehensive insights into model performance. The report also includes a brief analysis of models evaluated to date, highlighting observed trends and limitations. By establishing this benchmarking framework, the leaderboard aims to promote transparency, facilitate comparative analyses, and drive innovation in clinical entity recognition tasks, addressing the need for robust evaluation methods in healthcare NLP.
Med42 -- Evaluating Fine-Tuning Strategies for Medical LLMs: Full-Parameter vs. Parameter-Efficient Approaches
Apr 23, 2024



This study presents a comprehensive analysis and comparison of two predominant fine-tuning methodologies - full-parameter fine-tuning and parameter-efficient tuning - within the context of medical Large Language Models (LLMs). We developed and refined a series of LLMs, based on the Llama-2 architecture, specifically designed to enhance medical knowledge retrieval, reasoning, and question-answering capabilities. Our experiments systematically evaluate the effectiveness of these tuning strategies across various well-known medical benchmarks. Notably, our medical LLM Med42 showed an accuracy level of 72% on the US Medical Licensing Examination (USMLE) datasets, setting a new standard in performance for openly available medical LLMs. Through this comparative analysis, we aim to identify the most effective and efficient method for fine-tuning LLMs in the medical domain, thereby contributing significantly to the advancement of AI-driven healthcare applications.
Detecting Propaganda Techniques in Code-Switched Social Media Text
May 23, 2023
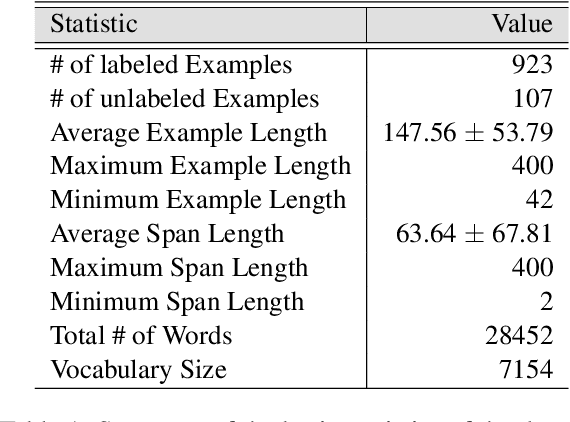
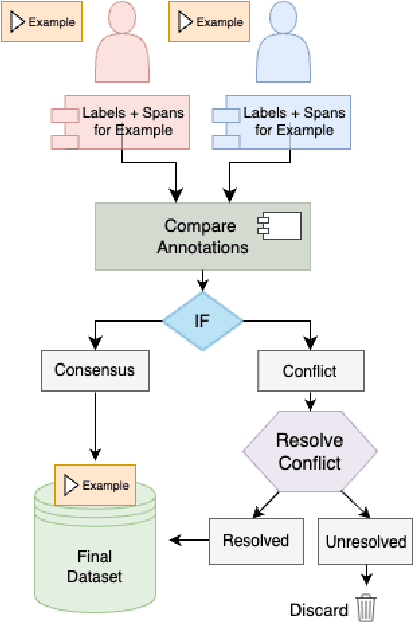
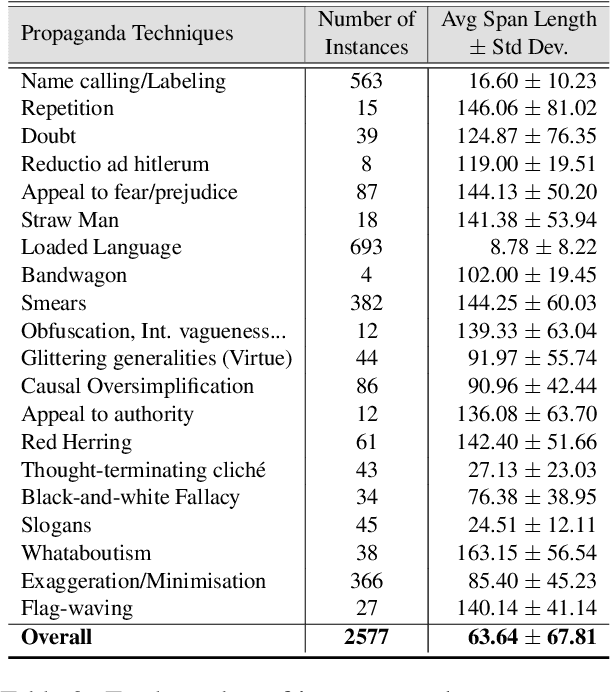
Propaganda is a form of communication intended to influence the opinions and the mindset of the public to promote a particular agenda. With the rise of social media, propaganda has spread rapidly, leading to the need for automatic propaganda detection systems. Most work on propaganda detection has focused on high-resource languages, such as English, and little effort has been made to detect propaganda for low-resource languages. Yet, it is common to find a mix of multiple languages in social media communication, a phenomenon known as code-switching. Code-switching combines different languages within the same text, which poses a challenge for automatic systems. With this in mind, here we propose the novel task of detecting propaganda techniques in code-switched text. To support this task, we create a corpus of 1,030 texts code-switching between English and Roman Urdu, annotated with 20 propaganda techniques, which we make publicly available. We perform a number of experiments contrasting different experimental setups, and we find that it is important to model the multilinguality directly (rather than using translation) as well as to use the right fine-tuning strategy. The code and the dataset are publicly available at https://github.com/mbzuai-nlp/propaganda-codeswitched-text