 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNamed Clinical Entity Recognition Benchmark
Oct 07, 2024
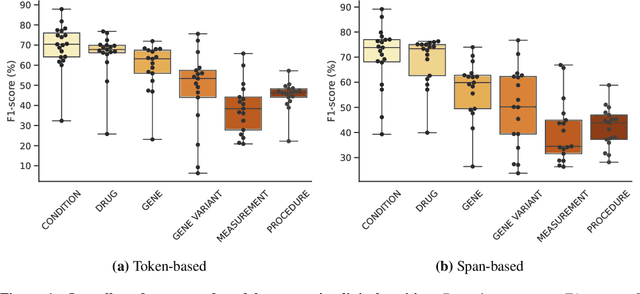

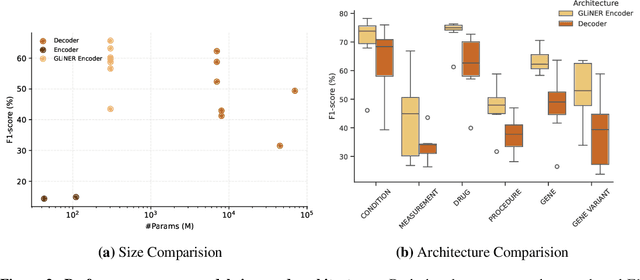
This technical report introduces a Named Clinical Entity Recognition Benchmark for evaluating language models in healthcare, addressing the crucial natural language processing (NLP) task of extracting structured information from clinical narratives to support applications like automated coding, clinical trial cohort identification, and clinical decision support. The leaderboard provides a standardized platform for assessing diverse language models, including encoder and decoder architectures, on their ability to identify and classify clinical entities across multiple medical domains. A curated collection of openly available clinical datasets is utilized, encompassing entities such as diseases, symptoms, medications, procedures, and laboratory measurements. Importantly, these entities are standardized according to the Observational Medical Outcomes Partnership (OMOP) Common Data Model, ensuring consistency and interoperability across different healthcare systems and datasets, and a comprehensive evaluation of model performance. Performance of models is primarily assessed using the F1-score, and it is complemented by various assessment modes to provide comprehensive insights into model performance. The report also includes a brief analysis of models evaluated to date, highlighting observed trends and limitations. By establishing this benchmarking framework, the leaderboard aims to promote transparency, facilitate comparative analyses, and drive innovation in clinical entity recognition tasks, addressing the need for robust evaluation methods in healthcare NLP.