 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLlama-3.1-Sherkala-8B-Chat: An Open Large Language Model for Kazakh
Mar 03, 2025Llama-3.1-Sherkala-8B-Chat, or Sherkala-Chat (8B) for short, is a state-of-the-art instruction-tuned open generative large language model (LLM) designed for Kazakh. Sherkala-Chat (8B) aims to enhance the inclusivity of LLM advancements for Kazakh speakers. Adapted from the LLaMA-3.1-8B model, Sherkala-Chat (8B) is trained on 45.3B tokens across Kazakh, English, Russian, and Turkish. With 8 billion parameters, it demonstrates strong knowledge and reasoning abilities in Kazakh, significantly outperforming existing open Kazakh and multilingual models of similar scale while achieving competitive performance in English. We release Sherkala-Chat (8B) as an open-weight instruction-tuned model and provide a detailed overview of its training, fine-tuning, safety alignment, and evaluation, aiming to advance research and support diverse real-world applications.
Foundational Large Language Models for Materials Research
Dec 12, 2024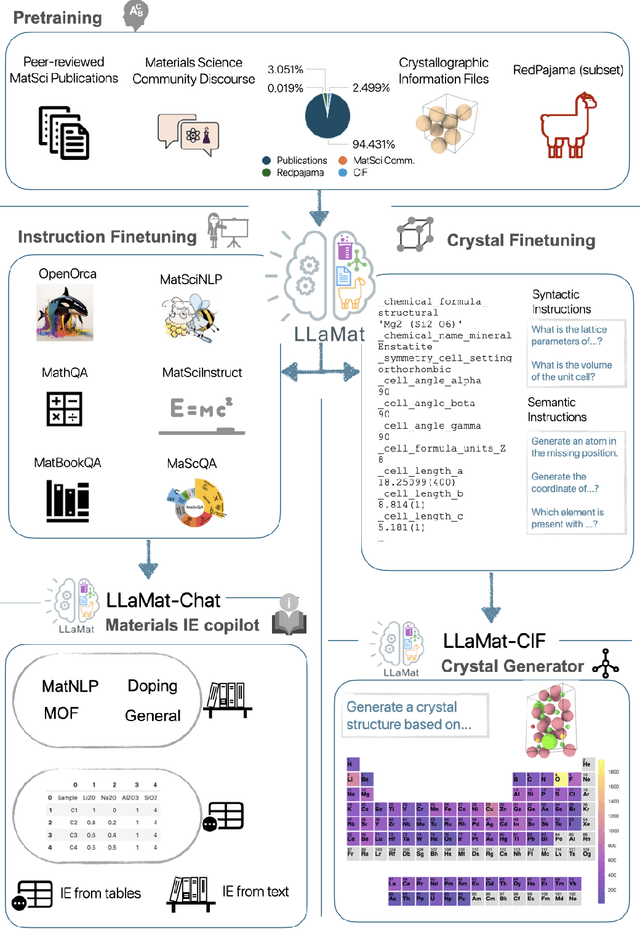
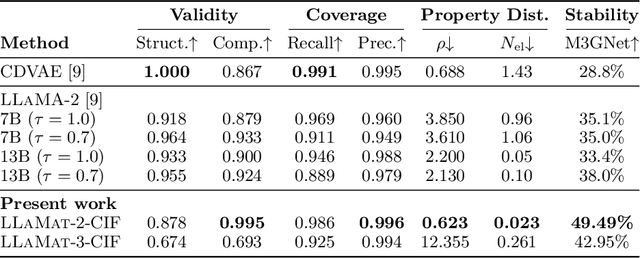
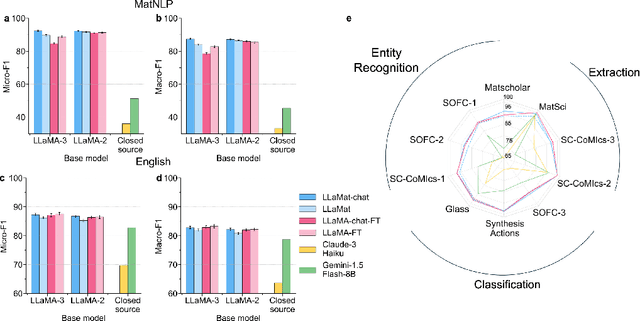
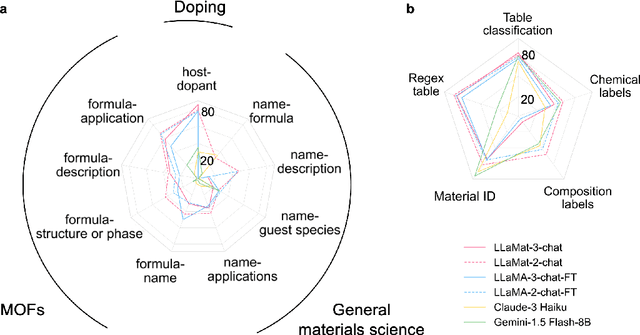
Materials discovery and development are critical for addressing global challenges. Yet, the exponential growth in materials science literature comprising vast amounts of textual data has created significant bottlenecks in knowledge extraction, synthesis, and scientific reasoning. Large Language Models (LLMs) offer unprecedented opportunities to accelerate materials research through automated analysis and prediction. Still, their effective deployment requires domain-specific adaptation for understanding and solving domain-relevant tasks. Here, we present LLaMat, a family of foundational models for materials science developed through continued pretraining of LLaMA models on an extensive corpus of materials literature and crystallographic data. Through systematic evaluation, we demonstrate that LLaMat excels in materials-specific NLP and structured information extraction while maintaining general linguistic capabilities. The specialized LLaMat-CIF variant demonstrates unprecedented capabilities in crystal structure generation, predicting stable crystals with high coverage across the periodic table. Intriguingly, despite LLaMA-3's superior performance in comparison to LLaMA-2, we observe that LLaMat-2 demonstrates unexpectedly enhanced domain-specific performance across diverse materials science tasks, including structured information extraction from text and tables, more particularly in crystal structure generation, a potential adaptation rigidity in overtrained LLMs. Altogether, the present work demonstrates the effectiveness of domain adaptation towards developing practically deployable LLM copilots for materials research. Beyond materials science, our findings reveal important considerations for domain adaptation of LLMs, such as model selection, training methodology, and domain-specific performance, which may influence the development of specialized scientific AI systems.
Bilingual Adaptation of Monolingual Foundation Models
Jul 13, 2024
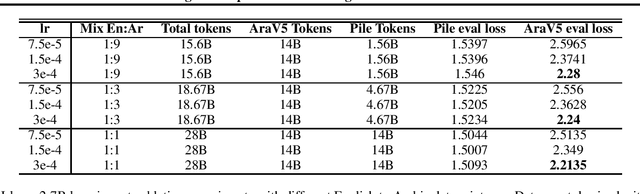


We present an efficient method for adapting a monolingual Large Language Model (LLM) to another language, addressing challenges of catastrophic forgetting and tokenizer limitations. We focus this study on adapting Llama 2 to Arabic. Our two-stage approach begins with expanding the vocabulary and training only the embeddings matrix, followed by full model continual pretraining on a bilingual corpus. By continually pretraining on a mix of Arabic and English corpora, the model retains its proficiency in English while acquiring capabilities in Arabic. Our approach results in significant improvements in Arabic and slight enhancements in English, demonstrating cost-effective cross-lingual transfer. We also perform extensive ablations on embedding initialization techniques, data mix ratios, and learning rates and release a detailed training recipe.
Origins of ECG and Evolution of Automated DSP Techniques: A Review
May 19, 2021Over the years researchers have studied the evolution of Electrocardiogram (ECG) and the complex classification of cardiovascular diseases. This review focuses on the evolution of the ECG, and covers the most recent signal processing schemes with milestones over last 150 years in a systematic manner. Development phases of ECG, ECG leads, portable ECG monitors, Signal Processing Schemes and the Complex Transformations are discussed. It also provides recommendations for the inclusion of certain important points based on the review.
Exploring Alternatives to Softmax Function
Nov 23, 2020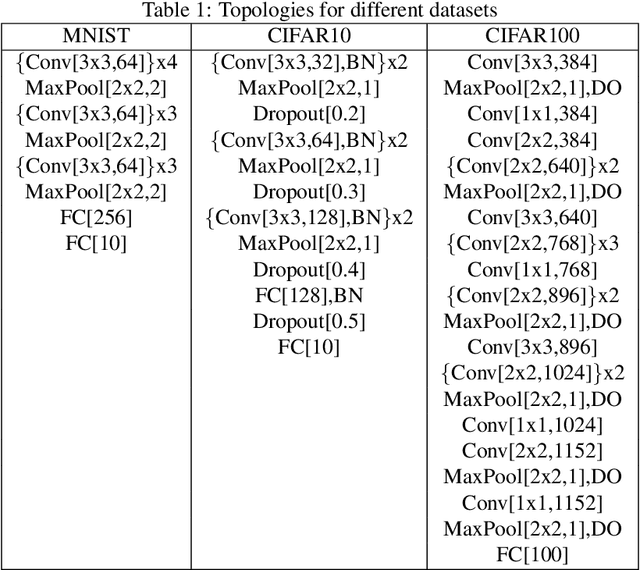
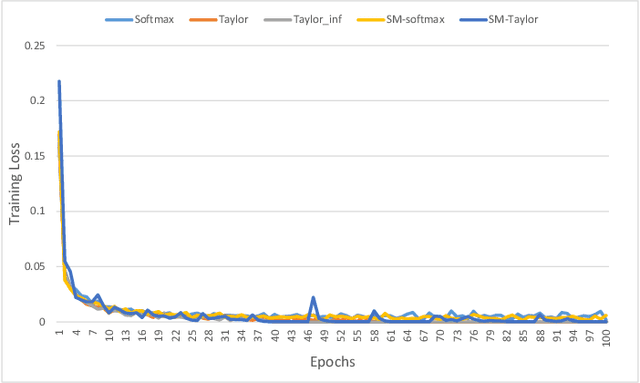

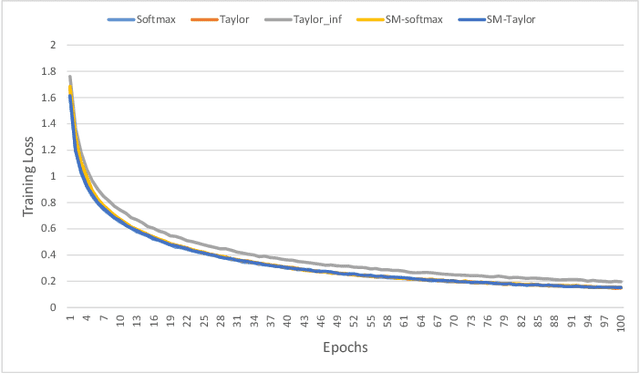
Softmax function is widely used in artificial neural networks for multiclass classification, multilabel classification, attention mechanisms, etc. However, its efficacy is often questioned in literature. The log-softmax loss has been shown to belong to a more generic class of loss functions, called spherical family, and its member log-Taylor softmax loss is arguably the best alternative in this class. In another approach which tries to enhance the discriminative nature of the softmax function, soft-margin softmax (SM-softmax) has been proposed to be the most suitable alternative. In this work, we investigate Taylor softmax, SM-softmax and our proposed SM-Taylor softmax, an amalgamation of the earlier two functions, as alternatives to softmax function. Furthermore, we explore the effect of expanding Taylor softmax up to ten terms (original work proposed expanding only to two terms) along with the ramifications of considering Taylor softmax to be a finite or infinite series during backpropagation. Our experiments for the image classification task on different datasets reveal that there is always a configuration of the SM-Taylor softmax function that outperforms the normal softmax function and its other alternatives.
Analytical Equations based Prediction Approach for PM2.5 using Artificial Neural Network
Feb 26, 2020



Particulate matter pollution is one of the deadliest types of air pollution worldwide due to its significant impacts on the global environment and human health. Particulate Matter (PM2.5) is one of the important particulate pollutants to measure the Air Quality Index (AQI). The conventional instruments used by the air quality monitoring stations to monitor PM2.5 are costly, bulkier, time-consuming, and power-hungry. Furthermore, due to limited data availability and non-scalability, these stations cannot provide high spatial and temporal resolution in real-time. To overcome the disadvantages of existing methodology this article presents analytical equations based prediction approach for PM2.5 using an Artificial Neural Network (ANN). Since the derived analytical equations for the prediction can be computed using a Wireless Sensor Node (WSN) or low-cost processing tool, it demonstrates the usefulness of the proposed approach. Moreover, the study related to correlation among the PM2.5 and other pollutants is performed to select the appropriate predictors. The large authenticate data set of Central Pollution Control Board (CPCB) online station, India is used for the proposed approach. The RMSE and coefficient of determination (R2) obtained for the proposed prediction approach using eight predictors are 1.7973 ug/m3 and 0.9986 respectively. While the proposed approach results show RMSE of 7.5372 ug/m3 and R2 of 0.9708 using three predictors. Therefore, the results demonstrate that the proposed approach is one of the promising approaches for monitoring PM2.5 without power-hungry gas sensors and bulkier analyzers.
An optimal scheduling architecture for accelerating batch algorithms on Neural Network processor architectures
Feb 14, 2020In neural network topologies, algorithms are running on batches of data tensors. The batches of data are typically scheduled onto the computing cores which execute in parallel. For the algorithms running on batches of data, an optimal batch scheduling architecture is very much needed by suitably utilizing hardware resources - thereby resulting in significant reduction training and inference time. In this paper, we propose to accelerate the batch algorithms for neural networks through a scheduling architecture enabling optimal compute power utilization. The proposed optimal scheduling architecture can be built into HW or can be implemented in SW alone which can be leveraged for accelerating batch algorithms. The results demonstrate that the proposed architecture speeds up the batch algorithms compared to the previous solutions. The proposed idea applies to any HPC architecture meant for neural networks.