 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Amateur to Master: Infusing Knowledge into LLMs via Automated Curriculum Learning
Oct 30, 2025



Large Language Models (LLMs) excel at general tasks but underperform in specialized domains like economics and psychology, which require deep, principled understanding. To address this, we introduce ACER (Automated Curriculum-Enhanced Regimen) that transforms generalist models into domain experts without sacrificing their broad capabilities. ACER first synthesizes a comprehensive, textbook-style curriculum by generating a table of contents for a subject and then creating question-answer (QA) pairs guided by Bloom's taxonomy. This ensures systematic topic coverage and progressively increasing difficulty. The resulting synthetic corpus is used for continual pretraining with an interleaved curriculum schedule, aligning learning across both content and cognitive dimensions. Experiments with Llama 3.2 (1B and 3B) show significant gains in specialized MMLU subsets. In challenging domains like microeconomics, where baselines struggle, ACER boosts accuracy by 5 percentage points. Across all target domains, we observe a consistent macro-average improvement of 3 percentage points. Notably, ACER not only prevents catastrophic forgetting but also facilitates positive cross-domain knowledge transfer, improving performance on non-target domains by 0.7 points. Beyond MMLU, ACER enhances performance on knowledge-intensive benchmarks like ARC and GPQA by over 2 absolute points, while maintaining stable performance on general reasoning tasks. Our results demonstrate that ACER offers a scalable and effective recipe for closing critical domain gaps in LLMs.
Llama-3-Nanda-10B-Chat: An Open Generative Large Language Model for Hindi
Apr 08, 2025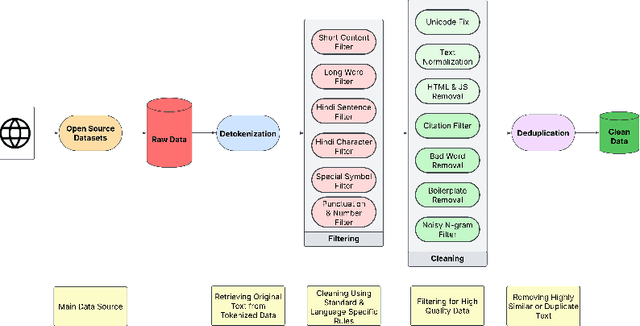

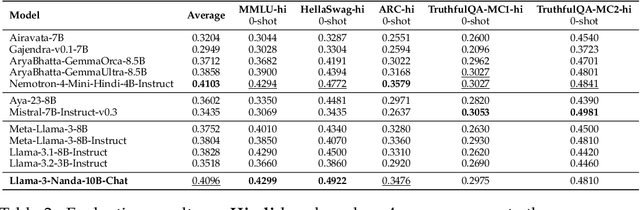

Developing high-quality large language models (LLMs) for moderately resourced languages presents unique challenges in data availability, model adaptation, and evaluation. We introduce Llama-3-Nanda-10B-Chat, or Nanda for short, a state-of-the-art Hindi-centric instruction-tuned generative LLM, designed to push the boundaries of open-source Hindi language models. Built upon Llama-3-8B, Nanda incorporates continuous pre-training with expanded transformer blocks, leveraging the Llama Pro methodology. A key challenge was the limited availability of high-quality Hindi text data; we addressed this through rigorous data curation, augmentation, and strategic bilingual training, balancing Hindi and English corpora to optimize cross-linguistic knowledge transfer. With 10 billion parameters, Nanda stands among the top-performing open-source Hindi and multilingual models of similar scale, demonstrating significant advantages over many existing models. We provide an in-depth discussion of training strategies, fine-tuning techniques, safety alignment, and evaluation metrics, demonstrating how these approaches enabled Nanda to achieve state-of-the-art results. By open-sourcing Nanda, we aim to advance research in Hindi LLMs and support a wide range of real-world applications across academia, industry, and public services.
Llama-3.1-Sherkala-8B-Chat: An Open Large Language Model for Kazakh
Mar 03, 2025Llama-3.1-Sherkala-8B-Chat, or Sherkala-Chat (8B) for short, is a state-of-the-art instruction-tuned open generative large language model (LLM) designed for Kazakh. Sherkala-Chat (8B) aims to enhance the inclusivity of LLM advancements for Kazakh speakers. Adapted from the LLaMA-3.1-8B model, Sherkala-Chat (8B) is trained on 45.3B tokens across Kazakh, English, Russian, and Turkish. With 8 billion parameters, it demonstrates strong knowledge and reasoning abilities in Kazakh, significantly outperforming existing open Kazakh and multilingual models of similar scale while achieving competitive performance in English. We release Sherkala-Chat (8B) as an open-weight instruction-tuned model and provide a detailed overview of its training, fine-tuning, safety alignment, and evaluation, aiming to advance research and support diverse real-world applications.
Bilingual Adaptation of Monolingual Foundation Models
Jul 13, 2024
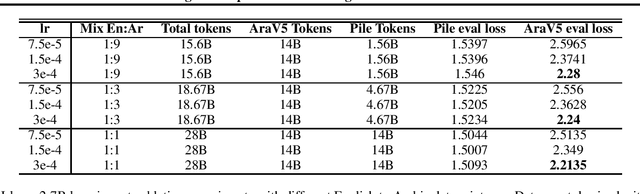


We present an efficient method for adapting a monolingual Large Language Model (LLM) to another language, addressing challenges of catastrophic forgetting and tokenizer limitations. We focus this study on adapting Llama 2 to Arabic. Our two-stage approach begins with expanding the vocabulary and training only the embeddings matrix, followed by full model continual pretraining on a bilingual corpus. By continually pretraining on a mix of Arabic and English corpora, the model retains its proficiency in English while acquiring capabilities in Arabic. Our approach results in significant improvements in Arabic and slight enhancements in English, demonstrating cost-effective cross-lingual transfer. We also perform extensive ablations on embedding initialization techniques, data mix ratios, and learning rates and release a detailed training recipe.