 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBilingual Adaptation of Monolingual Foundation Models
Jul 13, 2024
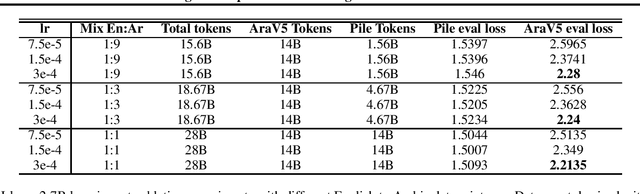


We present an efficient method for adapting a monolingual Large Language Model (LLM) to another language, addressing challenges of catastrophic forgetting and tokenizer limitations. We focus this study on adapting Llama 2 to Arabic. Our two-stage approach begins with expanding the vocabulary and training only the embeddings matrix, followed by full model continual pretraining on a bilingual corpus. By continually pretraining on a mix of Arabic and English corpora, the model retains its proficiency in English while acquiring capabilities in Arabic. Our approach results in significant improvements in Arabic and slight enhancements in English, demonstrating cost-effective cross-lingual transfer. We also perform extensive ablations on embedding initialization techniques, data mix ratios, and learning rates and release a detailed training recipe.
BTLM-3B-8K: 7B Parameter Performance in a 3B Parameter Model
Sep 20, 2023



We introduce the Bittensor Language Model, called "BTLM-3B-8K", a new state-of-the-art 3 billion parameter open-source language model. BTLM-3B-8K was trained on 627B tokens from the SlimPajama dataset with a mixture of 2,048 and 8,192 context lengths. BTLM-3B-8K outperforms all existing 3B parameter models by 2-5.5% across downstream tasks. BTLM-3B-8K is even competitive with some 7B parameter models. Additionally, BTLM-3B-8K provides excellent long context performance, outperforming MPT-7B-8K and XGen-7B-8K on tasks up to 8,192 context length. We trained the model on a cleaned and deduplicated SlimPajama dataset; aggressively tuned the \textmu P hyperparameters and schedule; used ALiBi position embeddings; and adopted the SwiGLU nonlinearity. On Hugging Face, the most popular models have 7B parameters, indicating that users prefer the quality-size ratio of 7B models. Compacting the 7B parameter model to one with 3B parameters, with little performance impact, is an important milestone. BTLM-3B-8K needs only 3GB of memory with 4-bit precision and takes 2.5x less inference compute than 7B models, helping to open up access to a powerful language model on mobile and edge devices. BTLM-3B-8K is available under an Apache 2.0 license on Hugging Face: https://huggingface.co/cerebras/btlm-3b-8k-base.
Cerebras-GPT: Open Compute-Optimal Language Models Trained on the Cerebras Wafer-Scale Cluster
Apr 06, 2023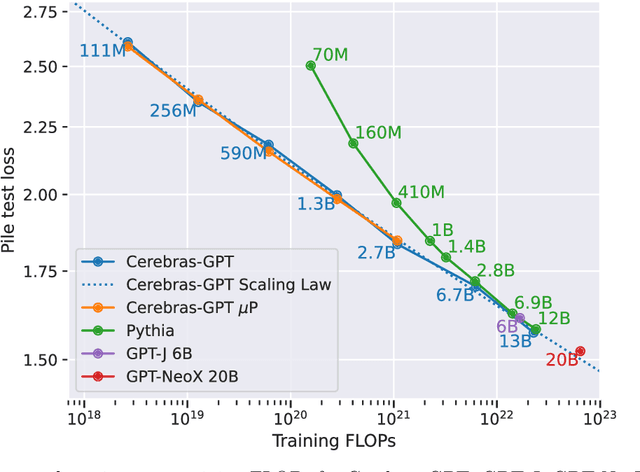
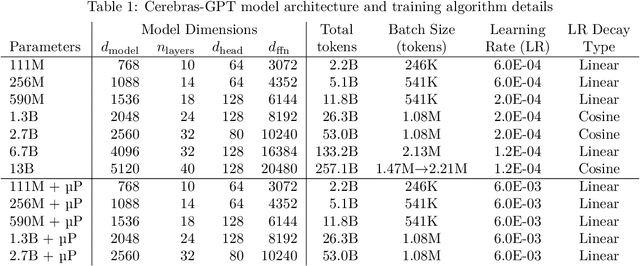
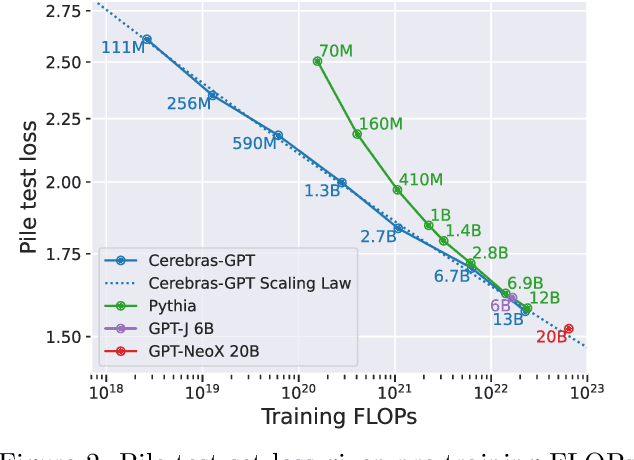
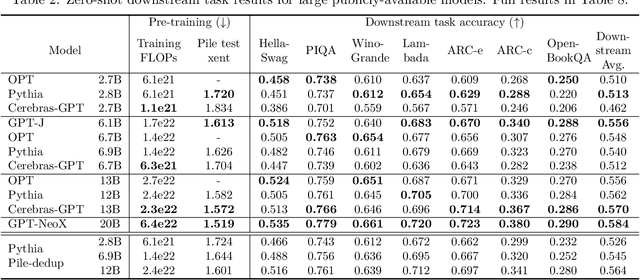
We study recent research advances that improve large language models through efficient pre-training and scaling, and open datasets and tools. We combine these advances to introduce Cerebras-GPT, a family of open compute-optimal language models scaled from 111M to 13B parameters. We train Cerebras-GPT models on the Eleuther Pile dataset following DeepMind Chinchilla scaling rules for efficient pre-training (highest accuracy for a given compute budget). We characterize the predictable power-law scaling and compare Cerebras-GPT with other publicly-available models to show all Cerebras-GPT models have state-of-the-art training efficiency on both pre-training and downstream objectives. We describe our learnings including how Maximal Update Parameterization ($\mu$P) can further improve large model scaling, improving accuracy and hyperparameter predictability at scale. We release our pre-trained models and code, making this paper the first open and reproducible work comparing compute-optimal model scaling to models trained on fixed dataset sizes. Cerebras-GPT models are available on HuggingFace: https://huggingface.co/cerebras.