 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBTLM-3B-8K: 7B Parameter Performance in a 3B Parameter Model
Sep 20, 2023



We introduce the Bittensor Language Model, called "BTLM-3B-8K", a new state-of-the-art 3 billion parameter open-source language model. BTLM-3B-8K was trained on 627B tokens from the SlimPajama dataset with a mixture of 2,048 and 8,192 context lengths. BTLM-3B-8K outperforms all existing 3B parameter models by 2-5.5% across downstream tasks. BTLM-3B-8K is even competitive with some 7B parameter models. Additionally, BTLM-3B-8K provides excellent long context performance, outperforming MPT-7B-8K and XGen-7B-8K on tasks up to 8,192 context length. We trained the model on a cleaned and deduplicated SlimPajama dataset; aggressively tuned the \textmu P hyperparameters and schedule; used ALiBi position embeddings; and adopted the SwiGLU nonlinearity. On Hugging Face, the most popular models have 7B parameters, indicating that users prefer the quality-size ratio of 7B models. Compacting the 7B parameter model to one with 3B parameters, with little performance impact, is an important milestone. BTLM-3B-8K needs only 3GB of memory with 4-bit precision and takes 2.5x less inference compute than 7B models, helping to open up access to a powerful language model on mobile and edge devices. BTLM-3B-8K is available under an Apache 2.0 license on Hugging Face: https://huggingface.co/cerebras/btlm-3b-8k-base.
Multi stain graph fusion for multimodal integration in pathology
Apr 26, 2022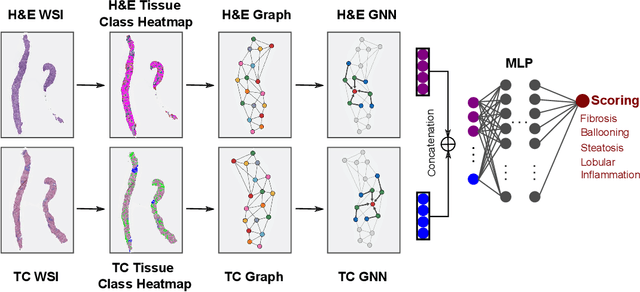
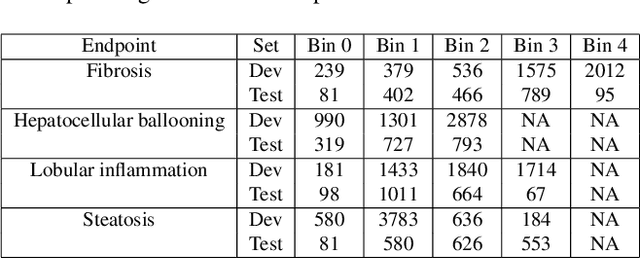
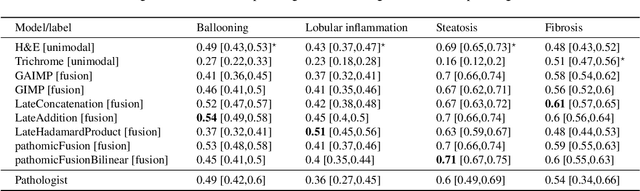
In pathology, tissue samples are assessed using multiple staining techniques to enhance contrast in unique histologic features. In this paper, we introduce a multimodal CNN-GNN based graph fusion approach that leverages complementary information from multiple non-registered histopathology images to predict pathologic scores. We demonstrate this approach in nonalcoholic steatohepatitis (NASH) by predicting CRN fibrosis stage and NAFLD Activity Score (NAS). Primary assessment of NASH typically requires liver biopsy evaluation on two histological stains: Trichrome (TC) and hematoxylin and eosin (H&E). Our multimodal approach learns to extract complementary information from TC and H&E graphs corresponding to each stain while simultaneously learning an optimal policy to combine this information. We report up to 20% improvement in predicting fibrosis stage and NAS component grades over single-stain modeling approaches, measured by computing linearly weighted Cohen's kappa between machine-derived vs. pathologist consensus scores. Broadly, this paper demonstrates the value of leveraging diverse pathology images for improved ML-powered histologic assessment.
Pass-Fail Criteria for Scenario-Based Testing of Automated Driving Systems
May 26, 2020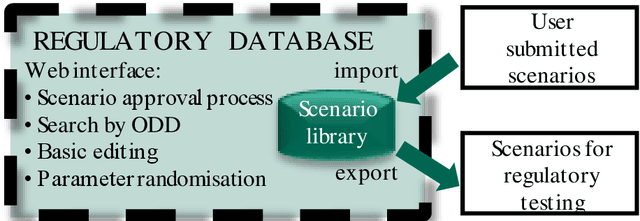

The MUSICC project has created a proof-of-concept scenario database to be used as part of a type approval process for the verification of automated driving systems (ADS). This process must include a highly automated means of evaluating test results, as manual review at the scale required is impractical. This paper sets out a framework for assessing an ADS's behavioural safety in normal operation (i.e. performance of the dynamic driving task without component failures or malicious actions). Five top-level evaluation criteria for ADS performance are identified. Implementing these requires two types of outcome scoring rule: prescriptive (measurable rules which must always be followed) and risk-based (undesirable outcomes which must not occur too often). Scoring rules are defined in a programming language and will be stored as part of the scenario description. Risk-based rules cannot give a pass/fail decision from a single test case. Instead, a framework is defined to reach a decision for each functional scenario (set of test cases with common features). This considers statistical performance across many individual tests. Implications of this framework for hypothesis testing and scenario selection are identified.