 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti stain graph fusion for multimodal integration in pathology
Apr 26, 2022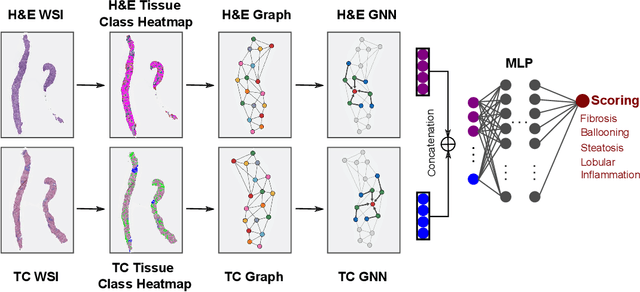
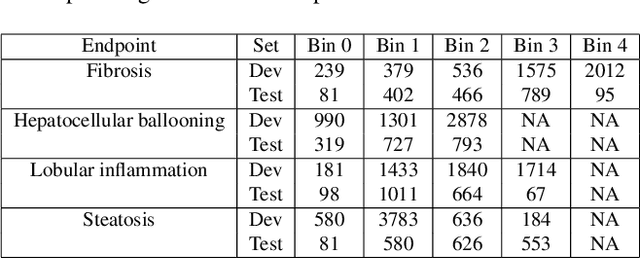
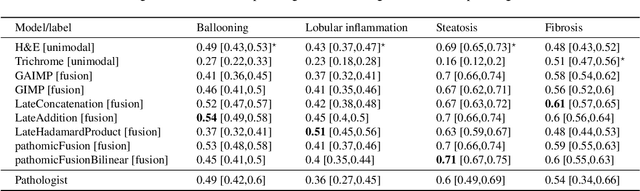
In pathology, tissue samples are assessed using multiple staining techniques to enhance contrast in unique histologic features. In this paper, we introduce a multimodal CNN-GNN based graph fusion approach that leverages complementary information from multiple non-registered histopathology images to predict pathologic scores. We demonstrate this approach in nonalcoholic steatohepatitis (NASH) by predicting CRN fibrosis stage and NAFLD Activity Score (NAS). Primary assessment of NASH typically requires liver biopsy evaluation on two histological stains: Trichrome (TC) and hematoxylin and eosin (H&E). Our multimodal approach learns to extract complementary information from TC and H&E graphs corresponding to each stain while simultaneously learning an optimal policy to combine this information. We report up to 20% improvement in predicting fibrosis stage and NAS component grades over single-stain modeling approaches, measured by computing linearly weighted Cohen's kappa between machine-derived vs. pathologist consensus scores. Broadly, this paper demonstrates the value of leveraging diverse pathology images for improved ML-powered histologic assessment.
Learning Modality-Invariant Representations for Speech and Images
Dec 11, 2017
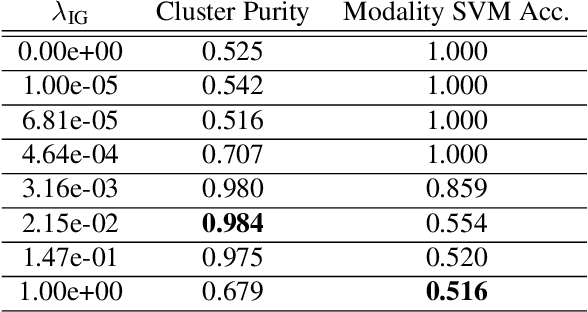
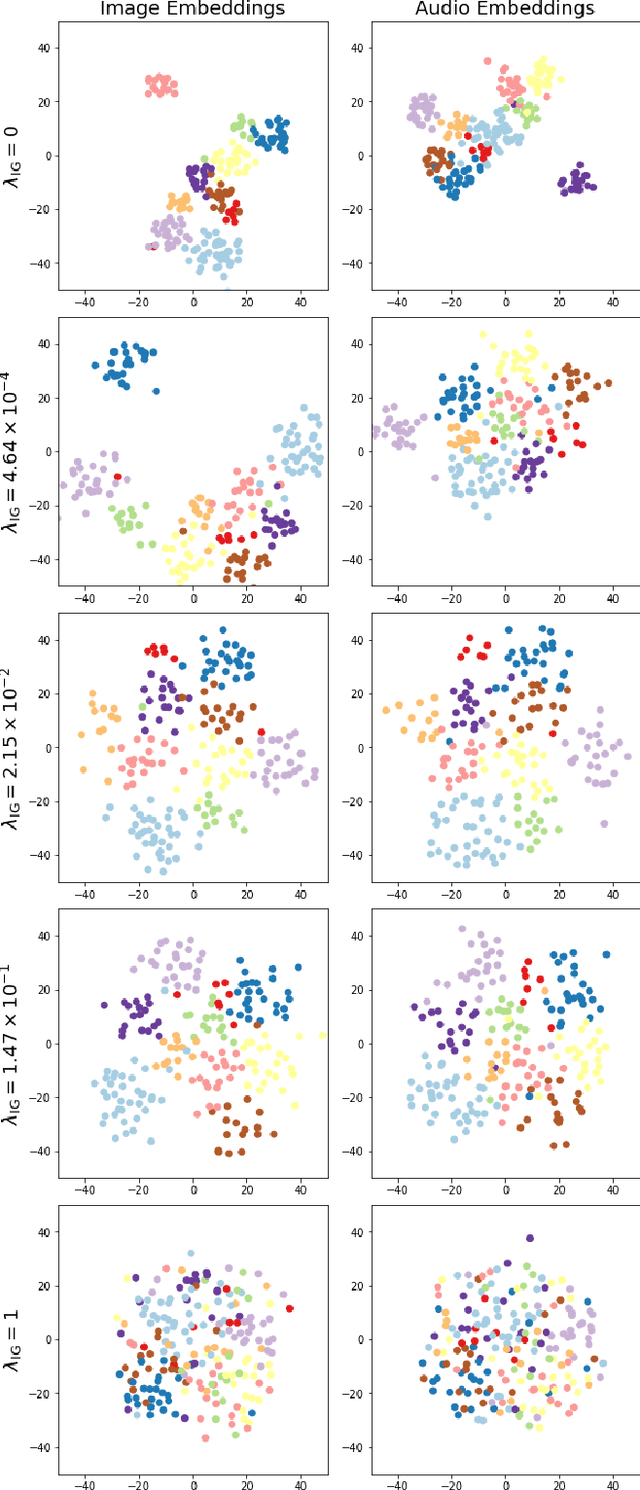
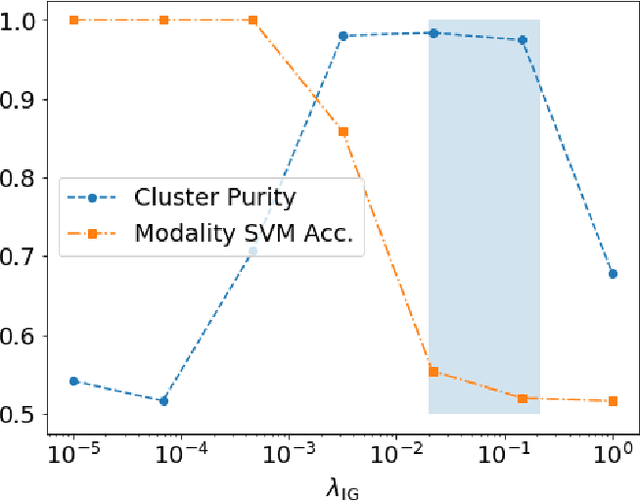
In this paper, we explore the unsupervised learning of a semantic embedding space for co-occurring sensory inputs. Specifically, we focus on the task of learning a semantic vector space for both spoken and handwritten digits using the TIDIGITs and MNIST datasets. Current techniques encode image and audio/textual inputs directly to semantic embeddings. In contrast, our technique maps an input to the mean and log variance vectors of a diagonal Gaussian from which sample semantic embeddings are drawn. In addition to encouraging semantic similarity between co-occurring inputs,our loss function includes a regularization term borrowed from variational autoencoders (VAEs) which drives the posterior distributions over embeddings to be unit Gaussian. We can use this regularization term to filter out modality information while preserving semantic information. We speculate this technique may be more broadly applicable to other areas of cross-modality/domain information retrieval and transfer learning.