 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslate-R1: Cost-Aware Translation Tool Use via Reinforcement Learning
Jun 05, 2026The performance gap across languages in LLMs is well documented, and closing it natively requires pretraining or fine-tuning on corpora that, for most languages, do not exist. Translation offers an alternative: converting an input into the model's dominant language unlocks its full capabilities at once. Applying translation to every input, however, is wasteful for languages the model already handles, while leaving the choice to the model fails in the opposite way, as LLMs are overconfident and skip the tool even when they cannot understand the input. Prior work resolves this with language-specific rules, domain heuristics, language identifiers, or external routers, each requiring manual engineering. We instead learn a single policy that decides when to translate from reward alone, developing language- and domain-adaptive introspection that assesses its own comprehension and invokes translation only when it cannot solve a task natively. Using data built by our answer-preserving translation pipeline, we continue RL on the post-trained Qwen3-4B across 22 languages in 3 resource tiers (High, Low, XLow) and 5 domains, and introduce confidence-gated GSPO for cost-sensitive tool use. The gated policy lifts reward over the baseline by +4.6 on High, +23.5 on Low, and +17.5 on XLow. Against an unconstrained policy that almost always translates, it preserves full reward at 63% of the cost and is Pareto-optimal across 87% of the cost-sensitivity range. Additionally, to simulate behavior on a completely unseen language, we create 2 synthetic languages, where our gated policy improves +18.7 over the overconfident baseline that underutilizes the tool even on these incomprehensible inputs. The policy transfers zero-shot to 9 held-out languages, and we analyze how tool use emerges over training, per language and per domain.
Expert Upcycling: Shifting the Compute-Efficient Frontier of Mixture-of-Experts
Apr 21, 2026Mixture-of-Experts (MoE) has become the dominant architecture for scaling large language models: frontier models routinely decouple total parameters from per-token computation through sparse expert routing. Scaling laws show that under fixed active computation, model quality scales predictably with total parameters, and MoEs realize this by increasing expert count. However, training large MoEs is expensive, as memory requirements and inter-device communication both scale with total parameter count. We propose expert upcycling, a method for progressively expanding MoE capacity by increasing the number of experts during continued pre-training (CPT). Given a trained E-expert model, the upcycling operator constructs an mE-expert model through expert duplication and router extension while holding top-K routing fixed, preserving per-token inference cost. Duplication provides a warm initialization: the expanded model inherits the source checkpoint's learned representations, starting from a substantially lower loss than random initialization. Subsequent CPT then breaks the symmetry among duplicated experts to drive specialization. We formalize the upcycling operator and develop a theoretical framework decomposing the quality gap into a capacity term and an initialization term. We further introduce utility-based expert selection, which uses gradient-based importance scores to guide non-uniform duplication, more than tripling gap closure when CPT is limited. In our 7B-13B total parameter experiments, the upcycled model matches the fixed-size baseline on validation loss while saving 32% of GPU hours. Comprehensive ablations across model scales, activation ratios, MoE architectures, and training budgets yield a practical recipe for deploying expert upcycling, establishing it as a principled, compute-efficient alternative to training large MoE models from scratch.
Performance Prediction of Hub-Based Swarms
Aug 09, 2024A hub-based colony consists of multiple agents who share a common nest site called the hub. Agents perform tasks away from the hub like foraging for food or gathering information about future nest sites. Modeling hub-based colonies is challenging because the size of the collective state space grows rapidly as the number of agents grows. This paper presents a graph-based representation of the colony that can be combined with graph-based encoders to create low-dimensional representations of collective state that can scale to many agents for a best-of-N colony problem. We demonstrate how the information in the low-dimensional embedding can be used with two experiments. First, we show how the information in the tensor can be used to cluster collective states by the probability of choosing the best site for a very small problem. Second, we show how structured collective trajectories emerge when a graph encoder is used to learn the low-dimensional embedding, and these trajectories have information that can be used to predict swarm performance.
Multi stain graph fusion for multimodal integration in pathology
Apr 26, 2022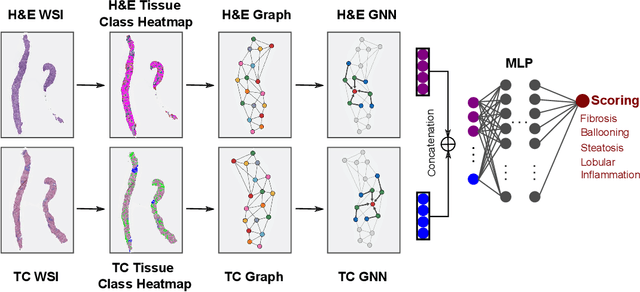
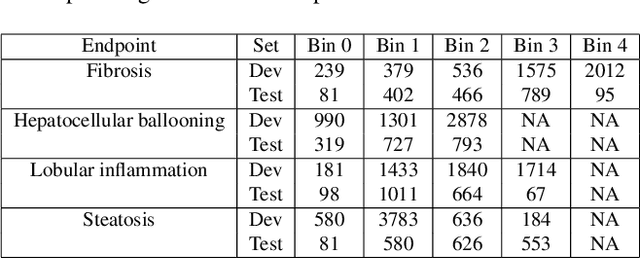
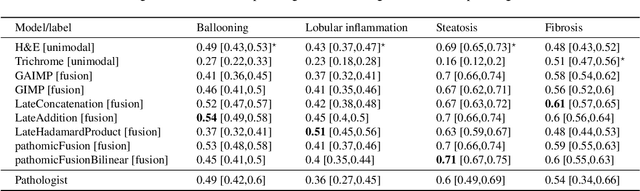
In pathology, tissue samples are assessed using multiple staining techniques to enhance contrast in unique histologic features. In this paper, we introduce a multimodal CNN-GNN based graph fusion approach that leverages complementary information from multiple non-registered histopathology images to predict pathologic scores. We demonstrate this approach in nonalcoholic steatohepatitis (NASH) by predicting CRN fibrosis stage and NAFLD Activity Score (NAS). Primary assessment of NASH typically requires liver biopsy evaluation on two histological stains: Trichrome (TC) and hematoxylin and eosin (H&E). Our multimodal approach learns to extract complementary information from TC and H&E graphs corresponding to each stain while simultaneously learning an optimal policy to combine this information. We report up to 20% improvement in predicting fibrosis stage and NAS component grades over single-stain modeling approaches, measured by computing linearly weighted Cohen's kappa between machine-derived vs. pathologist consensus scores. Broadly, this paper demonstrates the value of leveraging diverse pathology images for improved ML-powered histologic assessment.
Probabilistic Neighbourhood Component Analysis: Sample Efficient Uncertainty Estimation in Deep Learning
Jul 18, 2020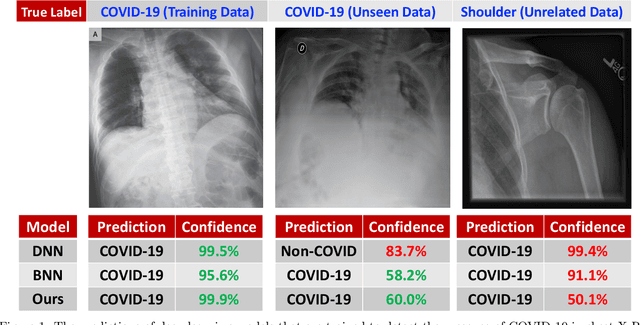

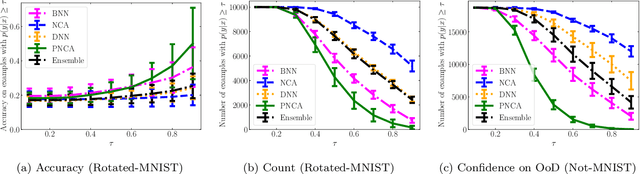
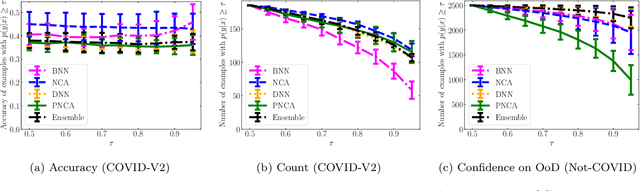
While Deep Neural Networks (DNNs) achieve state-of-the-art accuracy in various applications, they often fall short in accurately estimating their predictive uncertainty and, in turn, fail to recognize when these predictions may be wrong. Several uncertainty-aware models, such as Bayesian Neural Network (BNNs) and Deep Ensembles have been proposed in the literature for quantifying predictive uncertainty. However, research in this area has been largely confined to the big data regime. In this work, we show that the uncertainty estimation capability of state-of-the-art BNNs and Deep Ensemble models degrades significantly when the amount of training data is small. To address the issue of accurate uncertainty estimation in the small-data regime, we propose a probabilistic generalization of the popular sample-efficient non-parametric kNN approach. Our approach enables deep kNN classifier to accurately quantify underlying uncertainties in its prediction. We demonstrate the usefulness of the proposed approach by achieving superior uncertainty quantification as compared to state-of-the-art on a real-world application of COVID-19 diagnosis from chest X-Rays. Our code is available at https://github.com/ankurmallick/sample-efficient-uq
Deep Probabilistic Kernels for Sample-Efficient Learning
Oct 13, 2019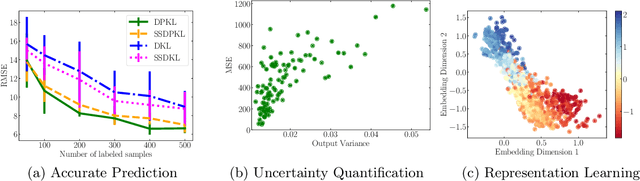
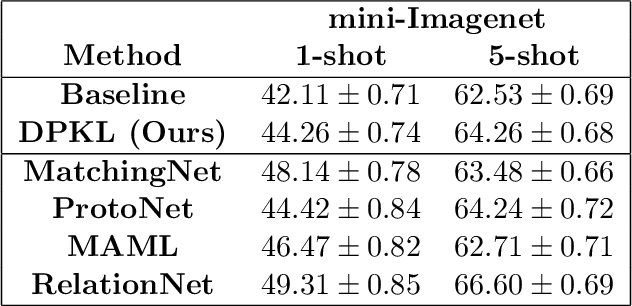
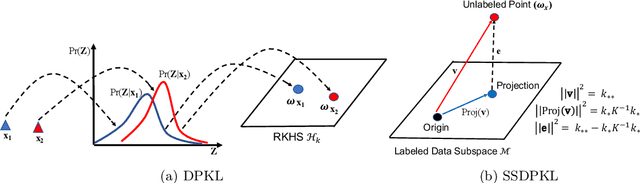
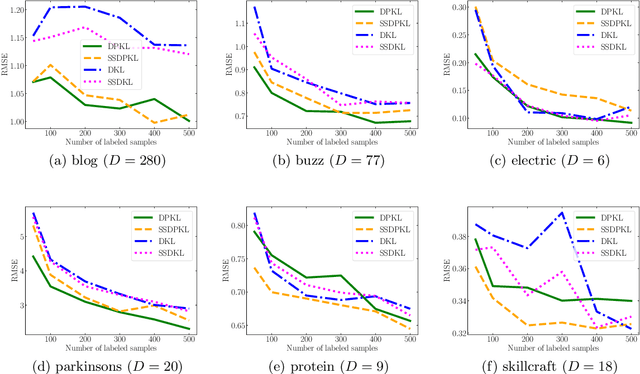
Gaussian Processes (GPs) with an appropriate kernel are known to provide accurate predictions and uncertainty estimates even with very small amounts of labeled data. However, GPs are generally unable to learn a good representation that can encode intricate structures in high dimensional data. The representation power of GPs depends heavily on kernel functions used to quantify the similarity between data points. Traditional GP kernels are not very effective at capturing similarity between high dimensional data points, while methods that use deep neural networks to learn a kernel are not sample-efficient. To overcome these drawbacks, we propose deep probabilistic kernels which use a probabilistic neural network to map high-dimensional data to a probability distribution in a low dimensional subspace, and leverage the rich work on kernels between distributions to capture the similarity between these distributions. Experiments on a variety of datasets show that building a GP using this covariance kernel solves the conflicting problems of representation learning and sample efficiency. Our model can be extended beyond GPs to other small-data paradigms such as few-shot classification where we show competitive performance with state-of-the-art models on the mini-Imagenet dataset.