 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePower Lines: Scaling Laws for Weight Decay and Batch Size in LLM Pre-training
May 19, 2025



Efficient LLM pre-training requires well-tuned hyperparameters (HPs), including learning rate {\eta} and weight decay {\lambda}. We study scaling laws for HPs: formulas for how to scale HPs as we scale model size N, dataset size D, and batch size B. Recent work suggests the AdamW timescale, B/({\eta}{\lambda}D), should remain constant across training settings, and we verify the implication that optimal {\lambda} scales linearly with B, for a fixed N,D. However, as N,D scale, we show the optimal timescale obeys a precise power law in the tokens-per-parameter ratio, D/N. This law thus provides a method to accurately predict {\lambda}opt in advance of large-scale training. We also study scaling laws for optimal batch size Bopt (the B enabling lowest loss at a given N,D) and critical batch size Bcrit (the B beyond which further data parallelism becomes ineffective). In contrast with prior work, we find both Bopt and Bcrit scale as power laws in D, independent of model size, N. Finally, we analyze how these findings inform the real-world selection of Pareto-optimal N and D under dual training time and compute objectives.
Don't be lazy: CompleteP enables compute-efficient deep transformers
May 02, 2025We study compute efficiency of LLM training when using different parameterizations, i.e., rules for adjusting model and optimizer hyperparameters (HPs) as model size changes. Some parameterizations fail to transfer optimal base HPs (such as learning rate) across changes in model depth, requiring practitioners to either re-tune these HPs as they scale up (expensive), or accept sub-optimal training when re-tuning is prohibitive. Even when they achieve HP transfer, we develop theory to show parameterizations may still exist in the lazy learning regime where layers learn only features close to their linearization, preventing effective use of depth and nonlinearity. Finally, we identify and adopt the unique parameterization we call CompleteP that achieves both depth-wise HP transfer and non-lazy learning in all layers. CompleteP enables a wider range of model width/depth ratios to remain compute-efficient, unlocking shapes better suited for different hardware settings and operational contexts. Moreover, CompleteP enables 12-34\% compute efficiency improvements over the prior state-of-the-art.
Straight to Zero: Why Linearly Decaying the Learning Rate to Zero Works Best for LLMs
Feb 21, 2025LLMs are commonly trained with a learning rate (LR) warmup, followed by cosine decay to 10% of the maximum (10x decay). In a large-scale empirical study, we show that under an optimal peak LR, a simple linear decay-to-zero (D2Z) schedule consistently outperforms other schedules when training at compute-optimal dataset sizes. D2Z is superior across a range of model sizes, batch sizes, datasets, and vocabularies. Benefits increase as dataset size increases. Leveraging a novel interpretation of AdamW as an exponential moving average of weight updates, we show how linear D2Z optimally balances the demands of early training (moving away from initial conditions) and late training (averaging over more updates in order to mitigate gradient noise). In experiments, a 610M-parameter model trained for 80 tokens-per-parameter (TPP) using D2Z achieves lower loss than when trained for 200 TPP using 10x decay, corresponding to an astonishing 60% compute savings. Models such as Llama2-7B, trained for 286 TPP with 10x decay, could likely have saved a majority of compute by training with D2Z.
Sparse maximal update parameterization: A holistic approach to sparse training dynamics
May 24, 2024



Several challenges make it difficult for sparse neural networks to compete with dense models. First, setting a large fraction of weights to zero impairs forward and gradient signal propagation. Second, sparse studies often need to test multiple sparsity levels, while also introducing new hyperparameters (HPs), leading to prohibitive tuning costs. Indeed, the standard practice is to re-use the learning HPs originally crafted for dense models. Unfortunately, we show sparse and dense networks do not share the same optimal HPs. Without stable dynamics and effective training recipes, it is costly to test sparsity at scale, which is key to surpassing dense networks and making the business case for sparsity acceleration in hardware. A holistic approach is needed to tackle these challenges and we propose S$\mu$Par as one such approach. S$\mu$Par ensures activations, gradients, and weight updates all scale independently of sparsity level. Further, by reparameterizing the HPs, S$\mu$Par enables the same HP values to be optimal as we vary both sparsity level and model width. HPs can be tuned on small dense networks and transferred to large sparse models, greatly reducing tuning costs. On large-scale language modeling, S$\mu$Par training improves loss by up to 8.2% over the common approach of using the dense model standard parameterization.
Position Interpolation Improves ALiBi Extrapolation
Oct 18, 2023Linear position interpolation helps pre-trained models using rotary position embeddings (RoPE) to extrapolate to longer sequence lengths. We propose using linear position interpolation to extend the extrapolation range of models using Attention with Linear Biases (ALiBi). We find position interpolation significantly improves extrapolation capability on upstream language modelling and downstream summarization and retrieval tasks.
BTLM-3B-8K: 7B Parameter Performance in a 3B Parameter Model
Sep 20, 2023



We introduce the Bittensor Language Model, called "BTLM-3B-8K", a new state-of-the-art 3 billion parameter open-source language model. BTLM-3B-8K was trained on 627B tokens from the SlimPajama dataset with a mixture of 2,048 and 8,192 context lengths. BTLM-3B-8K outperforms all existing 3B parameter models by 2-5.5% across downstream tasks. BTLM-3B-8K is even competitive with some 7B parameter models. Additionally, BTLM-3B-8K provides excellent long context performance, outperforming MPT-7B-8K and XGen-7B-8K on tasks up to 8,192 context length. We trained the model on a cleaned and deduplicated SlimPajama dataset; aggressively tuned the \textmu P hyperparameters and schedule; used ALiBi position embeddings; and adopted the SwiGLU nonlinearity. On Hugging Face, the most popular models have 7B parameters, indicating that users prefer the quality-size ratio of 7B models. Compacting the 7B parameter model to one with 3B parameters, with little performance impact, is an important milestone. BTLM-3B-8K needs only 3GB of memory with 4-bit precision and takes 2.5x less inference compute than 7B models, helping to open up access to a powerful language model on mobile and edge devices. BTLM-3B-8K is available under an Apache 2.0 license on Hugging Face: https://huggingface.co/cerebras/btlm-3b-8k-base.
Cerebras-GPT: Open Compute-Optimal Language Models Trained on the Cerebras Wafer-Scale Cluster
Apr 06, 2023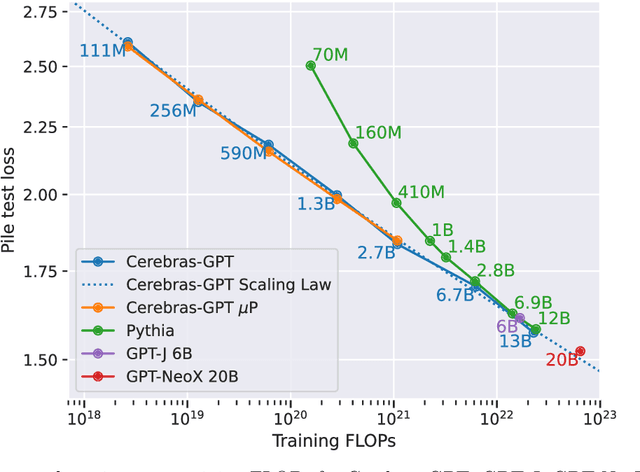
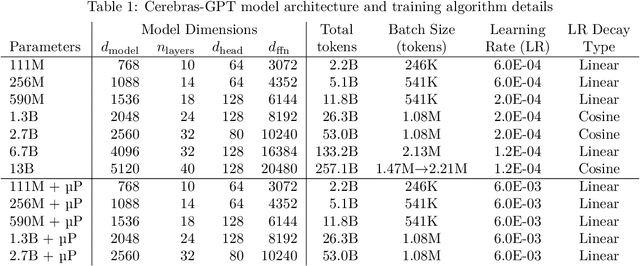
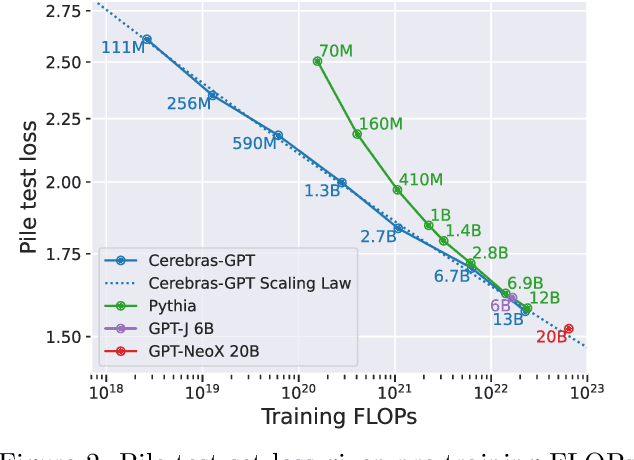
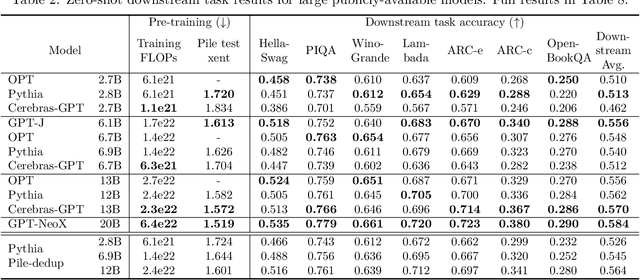
We study recent research advances that improve large language models through efficient pre-training and scaling, and open datasets and tools. We combine these advances to introduce Cerebras-GPT, a family of open compute-optimal language models scaled from 111M to 13B parameters. We train Cerebras-GPT models on the Eleuther Pile dataset following DeepMind Chinchilla scaling rules for efficient pre-training (highest accuracy for a given compute budget). We characterize the predictable power-law scaling and compare Cerebras-GPT with other publicly-available models to show all Cerebras-GPT models have state-of-the-art training efficiency on both pre-training and downstream objectives. We describe our learnings including how Maximal Update Parameterization ($\mu$P) can further improve large model scaling, improving accuracy and hyperparameter predictability at scale. We release our pre-trained models and code, making this paper the first open and reproducible work comparing compute-optimal model scaling to models trained on fixed dataset sizes. Cerebras-GPT models are available on HuggingFace: https://huggingface.co/cerebras.