 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoE-Inference-Bench: Performance Evaluation of Mixture of Expert Large Language and Vision Models
Aug 24, 2025Mixture of Experts (MoE) models have enabled the scaling of Large Language Models (LLMs) and Vision Language Models (VLMs) by achieving massive parameter counts while maintaining computational efficiency. However, MoEs introduce several inference-time challenges, including load imbalance across experts and the additional routing computational overhead. To address these challenges and fully harness the benefits of MoE, a systematic evaluation of hardware acceleration techniques is essential. We present MoE-Inference-Bench, a comprehensive study to evaluate MoE performance across diverse scenarios. We analyze the impact of batch size, sequence length, and critical MoE hyperparameters such as FFN dimensions and number of experts on throughput. We evaluate several optimization techniques on Nvidia H100 GPUs, including pruning, Fused MoE operations, speculative decoding, quantization, and various parallelization strategies. Our evaluation includes MoEs from the Mixtral, DeepSeek, OLMoE and Qwen families. The results reveal performance differences across configurations and provide insights for the efficient deployment of MoEs.
Power Lines: Scaling Laws for Weight Decay and Batch Size in LLM Pre-training
May 19, 2025



Efficient LLM pre-training requires well-tuned hyperparameters (HPs), including learning rate {\eta} and weight decay {\lambda}. We study scaling laws for HPs: formulas for how to scale HPs as we scale model size N, dataset size D, and batch size B. Recent work suggests the AdamW timescale, B/({\eta}{\lambda}D), should remain constant across training settings, and we verify the implication that optimal {\lambda} scales linearly with B, for a fixed N,D. However, as N,D scale, we show the optimal timescale obeys a precise power law in the tokens-per-parameter ratio, D/N. This law thus provides a method to accurately predict {\lambda}opt in advance of large-scale training. We also study scaling laws for optimal batch size Bopt (the B enabling lowest loss at a given N,D) and critical batch size Bcrit (the B beyond which further data parallelism becomes ineffective). In contrast with prior work, we find both Bopt and Bcrit scale as power laws in D, independent of model size, N. Finally, we analyze how these findings inform the real-world selection of Pareto-optimal N and D under dual training time and compute objectives.
Straight to Zero: Why Linearly Decaying the Learning Rate to Zero Works Best for LLMs
Feb 21, 2025LLMs are commonly trained with a learning rate (LR) warmup, followed by cosine decay to 10% of the maximum (10x decay). In a large-scale empirical study, we show that under an optimal peak LR, a simple linear decay-to-zero (D2Z) schedule consistently outperforms other schedules when training at compute-optimal dataset sizes. D2Z is superior across a range of model sizes, batch sizes, datasets, and vocabularies. Benefits increase as dataset size increases. Leveraging a novel interpretation of AdamW as an exponential moving average of weight updates, we show how linear D2Z optimally balances the demands of early training (moving away from initial conditions) and late training (averaging over more updates in order to mitigate gradient noise). In experiments, a 610M-parameter model trained for 80 tokens-per-parameter (TPP) using D2Z achieves lower loss than when trained for 200 TPP using 10x decay, corresponding to an astonishing 60% compute savings. Models such as Llama2-7B, trained for 286 TPP with 10x decay, could likely have saved a majority of compute by training with D2Z.
Position Interpolation Improves ALiBi Extrapolation
Oct 18, 2023Linear position interpolation helps pre-trained models using rotary position embeddings (RoPE) to extrapolate to longer sequence lengths. We propose using linear position interpolation to extend the extrapolation range of models using Attention with Linear Biases (ALiBi). We find position interpolation significantly improves extrapolation capability on upstream language modelling and downstream summarization and retrieval tasks.
BTLM-3B-8K: 7B Parameter Performance in a 3B Parameter Model
Sep 20, 2023



We introduce the Bittensor Language Model, called "BTLM-3B-8K", a new state-of-the-art 3 billion parameter open-source language model. BTLM-3B-8K was trained on 627B tokens from the SlimPajama dataset with a mixture of 2,048 and 8,192 context lengths. BTLM-3B-8K outperforms all existing 3B parameter models by 2-5.5% across downstream tasks. BTLM-3B-8K is even competitive with some 7B parameter models. Additionally, BTLM-3B-8K provides excellent long context performance, outperforming MPT-7B-8K and XGen-7B-8K on tasks up to 8,192 context length. We trained the model on a cleaned and deduplicated SlimPajama dataset; aggressively tuned the \textmu P hyperparameters and schedule; used ALiBi position embeddings; and adopted the SwiGLU nonlinearity. On Hugging Face, the most popular models have 7B parameters, indicating that users prefer the quality-size ratio of 7B models. Compacting the 7B parameter model to one with 3B parameters, with little performance impact, is an important milestone. BTLM-3B-8K needs only 3GB of memory with 4-bit precision and takes 2.5x less inference compute than 7B models, helping to open up access to a powerful language model on mobile and edge devices. BTLM-3B-8K is available under an Apache 2.0 license on Hugging Face: https://huggingface.co/cerebras/btlm-3b-8k-base.
SlimPajama-DC: Understanding Data Combinations for LLM Training
Sep 19, 2023



This paper aims to understand the impacts of various data combinations (e.g., web text, wikipedia, github, books) on the training of large language models using SlimPajama. SlimPajama is a rigorously deduplicated, multi-source dataset, which has been refined and further deduplicated to 627B tokens from the extensive 1.2T tokens RedPajama dataset contributed by Together. We've termed our research as SlimPajama-DC, an empirical analysis designed to uncover fundamental characteristics and best practices associated with employing SlimPajama in the training of large language models. During our research with SlimPajama, two pivotal observations emerged: (1) Global deduplication vs. local deduplication. We analyze and discuss how global (across different sources of datasets) and local (within the single source of dataset) deduplications affect the performance of trained models. (2) Proportions of high-quality/highly-deduplicated multi-source datasets in the combination. To study this, we construct six configurations of SlimPajama dataset and train individual ones using 1.3B Cerebras-GPT model with Alibi and SwiGLU. Our best configuration outperforms the 1.3B model trained on RedPajama using the same number of training tokens by a significant margin. All our 1.3B models are trained on Cerebras 16$\times$ CS-2 cluster with a total of 80 PFLOP/s in bf16 mixed precision. We further extend our discoveries (such as increasing data diversity is crucial after global deduplication) on a 7B model with large batch-size training. Our models and the separate SlimPajama-DC datasets are available at: https://huggingface.co/MBZUAI-LLM and https://huggingface.co/datasets/cerebras/SlimPajama-627B.
Replacing Human Audio with Synthetic Audio for On-device Unspoken Punctuation Prediction
Oct 20, 2020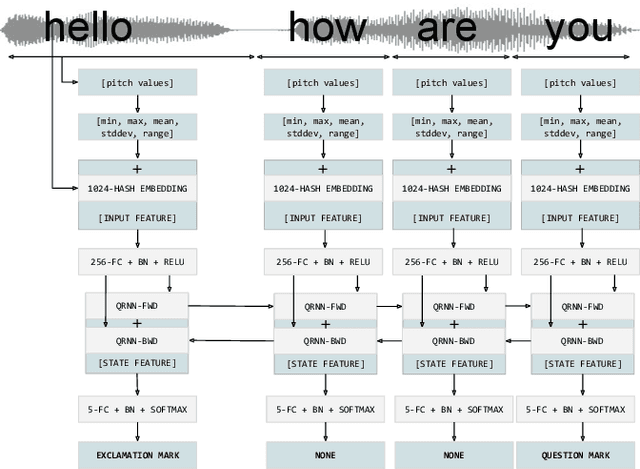

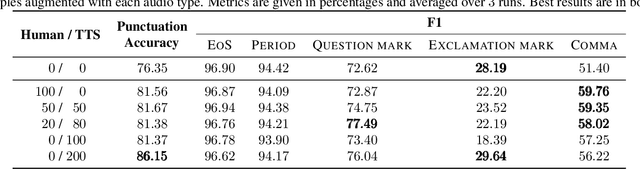

We present a novel multi-modal unspoken punctuation prediction system for the English language which combines acoustic and text features. We demonstrate for the first time, that by relying exclusively on synthetic data generated using a prosody-aware text-to-speech system, we can outperform a model trained with expensive human audio recordings on the unspoken punctuation prediction problem. Our model architecture is well suited for on-device use. This is achieved by leveraging hash-based embeddings of automatic speech recognition text output in conjunction with acoustic features as input to a quasi-recurrent neural network, keeping the model size small and latency low.