 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLive Music Models
Aug 06, 2025We introduce a new class of generative models for music called live music models that produce a continuous stream of music in real-time with synchronized user control. We release Magenta RealTime, an open-weights live music model that can be steered using text or audio prompts to control acoustic style. On automatic metrics of music quality, Magenta RealTime outperforms other open-weights music generation models, despite using fewer parameters and offering first-of-its-kind live generation capabilities. We also release Lyria RealTime, an API-based model with extended controls, offering access to our most powerful model with wide prompt coverage. These models demonstrate a new paradigm for AI-assisted music creation that emphasizes human-in-the-loop interaction for live music performance.
Towards Better Evaluation of Instruction-Following: A Case-Study in Summarization
Oct 20, 2023Despite recent advances, evaluating how well large language models (LLMs) follow user instructions remains an open problem. While evaluation methods of language models have seen a rise in prompt-based approaches, limited work on the correctness of these methods has been conducted. In this work, we perform a meta-evaluation of a variety of metrics to quantify how accurately they measure the instruction-following abilities of LLMs. Our investigation is performed on grounded query-based summarization by collecting a new short-form, real-world dataset riSum, containing 300 document-instruction pairs with 3 answers each. All 900 answers are rated by 3 human annotators. Using riSum, we analyze the agreement between evaluation methods and human judgment. Finally, we propose new LLM-based reference-free evaluation methods that improve upon established baselines and perform on par with costly reference-based metrics that require high-quality summaries.
Replacing Human Audio with Synthetic Audio for On-device Unspoken Punctuation Prediction
Oct 20, 2020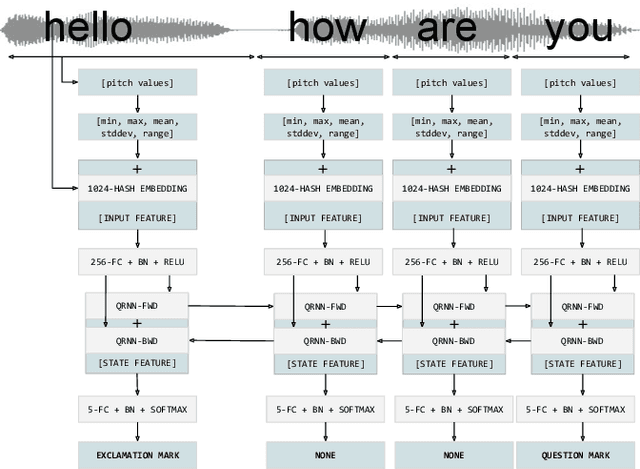

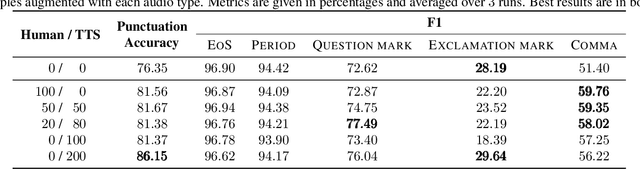

We present a novel multi-modal unspoken punctuation prediction system for the English language which combines acoustic and text features. We demonstrate for the first time, that by relying exclusively on synthetic data generated using a prosody-aware text-to-speech system, we can outperform a model trained with expensive human audio recordings on the unspoken punctuation prediction problem. Our model architecture is well suited for on-device use. This is achieved by leveraging hash-based embeddings of automatic speech recognition text output in conjunction with acoustic features as input to a quasi-recurrent neural network, keeping the model size small and latency low.
Mixed-curvature Variational Autoencoders
Nov 19, 2019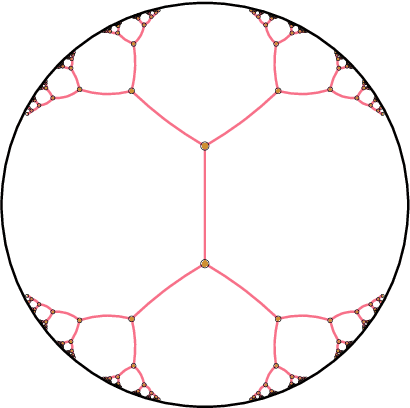
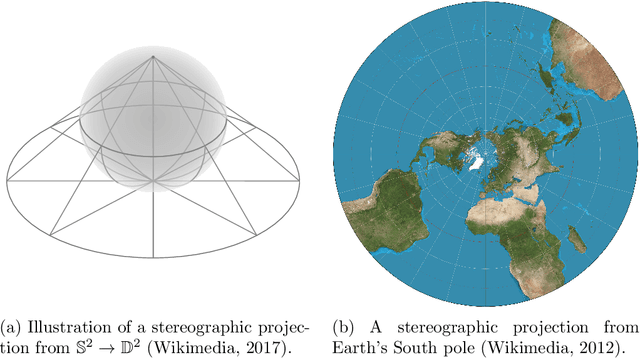
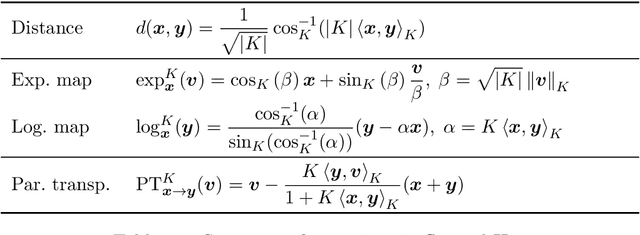

It has been shown that using geometric spaces with non-zero curvature instead of plain Euclidean spaces with zero curvature improves performance on a range of Machine Learning tasks for learning representations. Recent work has leveraged these geometries to learn latent variable models like Variational Autoencoders (VAEs) in spherical and hyperbolic spaces with constant curvature. While these approaches work well on particular kinds of data that they were designed for e.g. tree-like data for a hyperbolic VAE, there exists no generic approach unifying all three models. We develop a Mixed-curvature Variational Autoencoder, an efficient way to train a VAE whose latent space is a product of constant curvature Riemannian manifolds, where the per-component curvature can be learned. This generalizes the Euclidean VAE to curved latent spaces, as the model essentially reduces to the Euclidean VAE if curvatures of all latent space components go to 0.
Adversarial Augmentation for Enhancing Classification of Mammography Images
Feb 20, 2019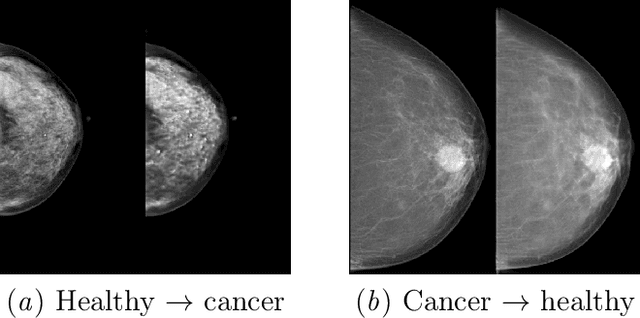
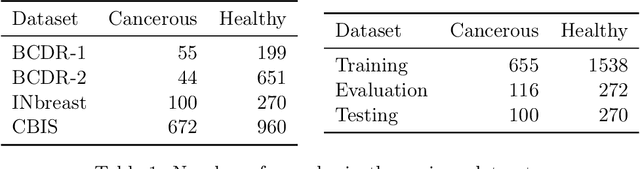
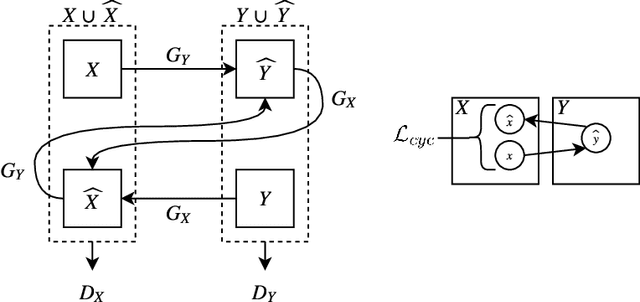

Supervised deep learning relies on the assumption that enough training data is available, which presents a problem for its application to several fields, like medical imaging. On the example of a binary image classification task (breast cancer recognition), we show that pretraining a generative model for meaningful image augmentation helps enhance the performance of the resulting classifier. By augmenting the data, performance on downstream classification tasks could be improved even with a relatively small training set. We show that this "adversarial augmentation" yields promising results compared to classical image augmentation on the example of breast cancer classification.
Injecting and removing malignant features in mammography with CycleGAN: Investigation of an automated adversarial attack using neural networks
Nov 19, 2018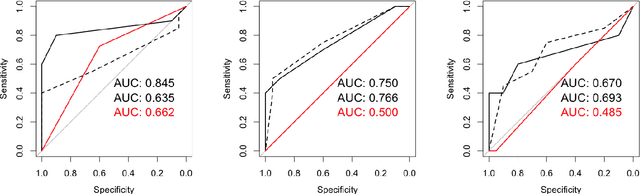
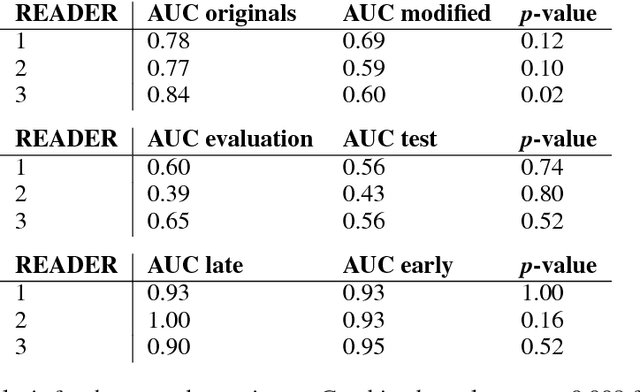

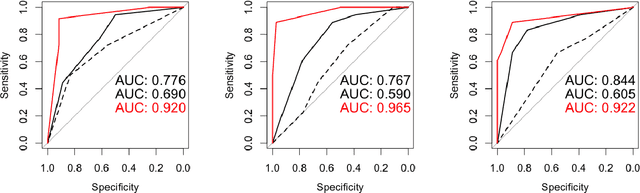
$\textbf{Purpose}$ To train a cycle-consistent generative adversarial network (CycleGAN) on mammographic data to inject or remove features of malignancy, and to determine whether these AI-mediated attacks can be detected by radiologists. $\textbf{Material and Methods}$ From the two publicly available datasets, BCDR and INbreast, we selected images from cancer patients and healthy controls. An internal dataset served as test data, withheld during training. We ran two experiments training CycleGAN on low and higher resolution images ($256 \times 256$ px and $512 \times 408$ px). Three radiologists read the images and rated the likelihood of malignancy on a scale from 1-5 and the likelihood of the image being manipulated. The readout was evaluated by ROC analysis (Area under the ROC curve = AUC). $\textbf{Results}$ At the lower resolution, only one radiologist exhibited markedly lower detection of cancer (AUC=0.85 vs 0.63, p=0.06), while the other two were unaffected (0.67 vs. 0.69 and 0.75 vs. 0.77, p=0.55). Only one radiologist could discriminate between original and modified images slightly better than guessing/chance (0.66, p=0.008). At the higher resolution, all radiologists showed significantly lower detection rate of cancer in the modified images (0.77-0.84 vs. 0.59-0.69, p=0.008), however, they were now able to reliably detect modified images due to better visibility of artifacts (0.92, 0.92 and 0.97). $\textbf{Conclusion}$ A CycleGAN can implicitly learn malignant features and inject or remove them so that a substantial proportion of small mammographic images would consequently be misdiagnosed. At higher resolutions, however, the method is currently limited and has a clear trade-off between manipulation of images and introduction of artifacts.