 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteraction Dynamics as a Reward Signal for LLMs
Nov 11, 2025The alignment of Large Language Models (LLMs) for multi-turn conversations typically relies on reward signals derived from the content of the text. This approach, however, overlooks a rich, complementary source of signal: the dynamics of the interaction itself. This paper introduces TRACE (Trajectory-based Reward for Agent Collaboration Estimation), a novel reward signal derived from the geometric properties of a dialogue's embedding trajectory--a concept we term 'conversational geometry'. Our central finding is that a reward model trained only on these structural signals achieves a pairwise accuracy (68.20%) comparable to a powerful LLM baseline that analyzes the full transcript (70.04%). Furthermore, a hybrid model combining interaction dynamics with textual analysis achieves the highest performance (80.17%), demonstrating their complementary nature. This work provides strong evidence that for interactive settings, how an agent communicates is as powerful a predictor of success as what it says, offering a new, privacy-preserving framework that not only aligns agents but also serves as a diagnostic tool for understanding the distinct interaction patterns that drive successful collaboration.
Generative Data Refinement: Just Ask for Better Data
Sep 10, 2025



For a fixed parameter size, the capabilities of large models are primarily determined by the quality and quantity of its training data. Consequently, training datasets now grow faster than the rate at which new data is indexed on the web, leading to projected data exhaustion over the next decade. Much more data exists as user-generated content that is not publicly indexed, but incorporating such data comes with considerable risks, such as leaking private information and other undesirable content. We introduce a framework, Generative Data Refinement (GDR), for using pretrained generative models to transform a dataset with undesirable content into a refined dataset that is more suitable for training. Our experiments show that GDR can outperform industry-grade solutions for dataset anonymization, as well as enable direct detoxification of highly unsafe datasets. Moreover, we show that by generating synthetic data that is conditioned on each example in the real dataset, GDR's refined outputs naturally match the diversity of web scale datasets, and thereby avoid the often challenging task of generating diverse synthetic data via model prompting. The simplicity and effectiveness of GDR make it a powerful tool for scaling up the total stock of training data for frontier models.
Writing as a testbed for open ended agents
Mar 25, 2025Open-ended tasks are particularly challenging for LLMs due to the vast solution space, demanding both expansive exploration and adaptable strategies, especially when success lacks a clear, objective definition. Writing, with its vast solution space and subjective evaluation criteria, provides a compelling testbed for studying such problems. In this paper, we investigate the potential of LLMs to act as collaborative co-writers, capable of suggesting and implementing text improvements autonomously. We analyse three prominent LLMs - Gemini 1.5 Pro, Claude 3.5 Sonnet, and GPT-4o - focusing on how their action diversity, human alignment, and iterative improvement capabilities impact overall performance. This work establishes a framework for benchmarking autonomous writing agents and, more broadly, highlights fundamental challenges and potential solutions for building systems capable of excelling in diverse open-ended domains.
Social Learning: Towards Collaborative Learning with Large Language Models
Dec 18, 2023



We introduce the framework of "social learning" in the context of large language models (LLMs), whereby models share knowledge with each other in a privacy-aware manner using natural language. We present and evaluate two approaches for knowledge transfer between LLMs. In the first scenario, we allow the model to generate abstract prompts aiming to teach the task. In our second approach, models transfer knowledge by generating synthetic examples. We evaluate these methods across diverse datasets and quantify memorization as a proxy for privacy loss. These techniques inspired by social learning yield promising results with low memorization of the original data. In particular, we show that performance using these methods is comparable to results with the use of original labels and prompts. Our work demonstrates the viability of social learning for LLMs, establishes baseline approaches and highlights several unexplored areas for future work.
The Impact of Preference Agreement in Reinforcement Learning from Human Feedback: A Case Study in Summarization
Nov 02, 2023


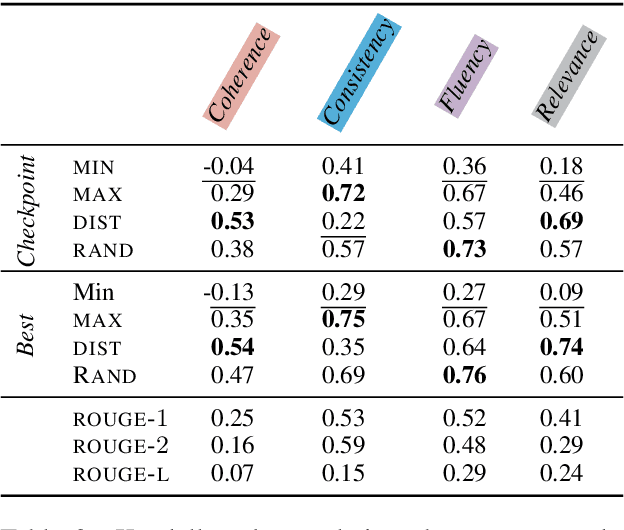
Reinforcement Learning from Human Feedback (RLHF) can be used to capture complex and nuanced properties of text generation quality. As a result, the task of text summarization has been identified as a good candidate for this process. In this paper, we explore how preference agreement impacts the efficacy of RLHF for summarization. We show that sampling human preferences to include a range of annotator agreement results in (1) higher accuracy reward models and (2) alters the characteristics of quality captured. We additionally show improvements in downstream generation when using a reward model trained with a range of preference agreements. Our contributions have implications for the design of synthetic datasets as well as the importance of considering quality differentials in comparison-based data.
Towards Better Evaluation of Instruction-Following: A Case-Study in Summarization
Oct 20, 2023Despite recent advances, evaluating how well large language models (LLMs) follow user instructions remains an open problem. While evaluation methods of language models have seen a rise in prompt-based approaches, limited work on the correctness of these methods has been conducted. In this work, we perform a meta-evaluation of a variety of metrics to quantify how accurately they measure the instruction-following abilities of LLMs. Our investigation is performed on grounded query-based summarization by collecting a new short-form, real-world dataset riSum, containing 300 document-instruction pairs with 3 answers each. All 900 answers are rated by 3 human annotators. Using riSum, we analyze the agreement between evaluation methods and human judgment. Finally, we propose new LLM-based reference-free evaluation methods that improve upon established baselines and perform on par with costly reference-based metrics that require high-quality summaries.
One Size Does Not Fit All: The Case for Personalised Word Complexity Models
May 05, 2022

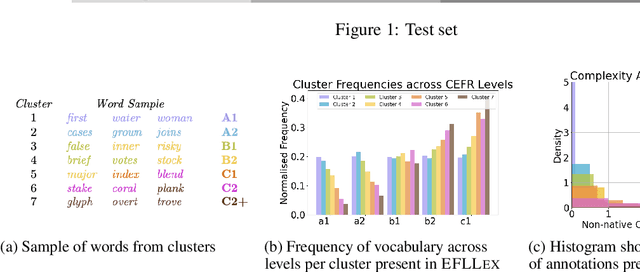

Complex Word Identification (CWI) aims to detect words within a text that a reader may find difficult to understand. It has been shown that CWI systems can improve text simplification, readability prediction and vocabulary acquisition modelling. However, the difficulty of a word is a highly idiosyncratic notion that depends on a reader's first language, proficiency and reading experience. In this paper, we show that personal models are best when predicting word complexity for individual readers. We use a novel active learning framework that allows models to be tailored to individuals and release a dataset of complexity annotations and models as a benchmark for further research.
On the Ethical Considerations of Text Simplification
Apr 20, 2022
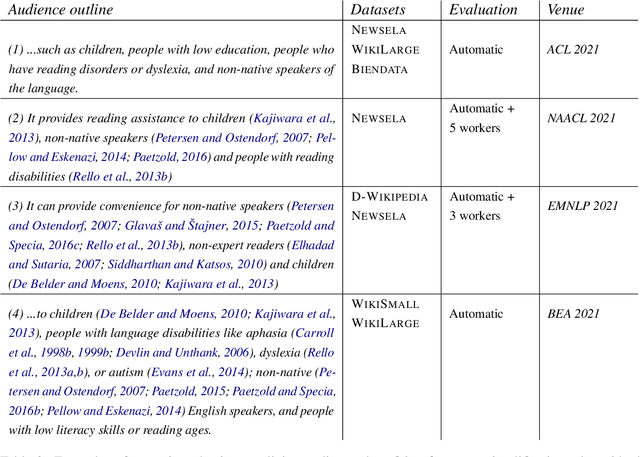
This paper outlines the ethical implications of text simplification within the framework of assistive systems. We argue that a distinction should be made between the technologies that perform text simplification and the realisation of these in assistive technologies. When using the latter as a motivation for research, it is important that the subsequent ethical implications be carefully considered. We provide guidelines for the framing of text simplification independently of assistive systems, as well as suggesting directions for future research and discussion based on the concerns raised.
Predicting Text Readability from Scrolling Interactions
May 13, 2021
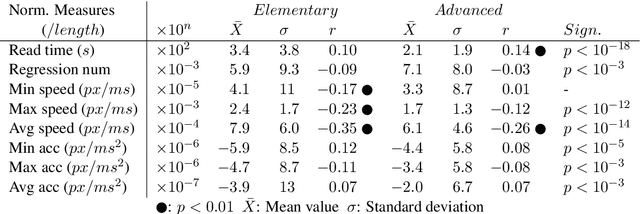


Judging the readability of text has many important applications, for instance when performing text simplification or when sourcing reading material for language learners. In this paper, we present a 518 participant study which investigates how scrolling behaviour relates to the readability of a text. We make our dataset publicly available and show that (1) there are statistically significant differences in the way readers interact with text depending on the text level, (2) such measures can be used to predict the readability of text, and (3) the background of a reader impacts their reading interactions and the factors contributing to text difficulty.
Detecting Multiword Expression Type Helps Lexical Complexity Assessment
May 12, 2020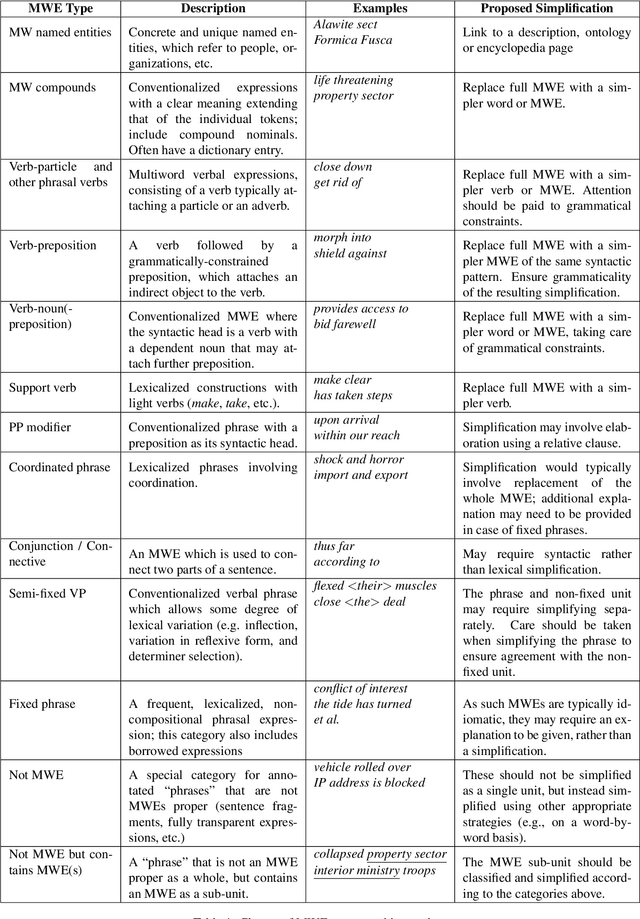



Multiword expressions (MWEs) represent lexemes that should be treated as single lexical units due to their idiosyncratic nature. Multiple NLP applications have been shown to benefit from MWE identification, however the research on lexical complexity of MWEs is still an under-explored area. In this work, we re-annotate the Complex Word Identification Shared Task 2018 dataset of Yimam et al. (2017), which provides complexity scores for a range of lexemes, with the types of MWEs. We release the MWE-annotated dataset with this paper, and we believe this dataset represents a valuable resource for the text simplification community. In addition, we investigate which types of expressions are most problematic for native and non-native readers. Finally, we show that a lexical complexity assessment system benefits from the information about MWE types.