 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Multiword Expression Type Helps Lexical Complexity Assessment
Paper and Code
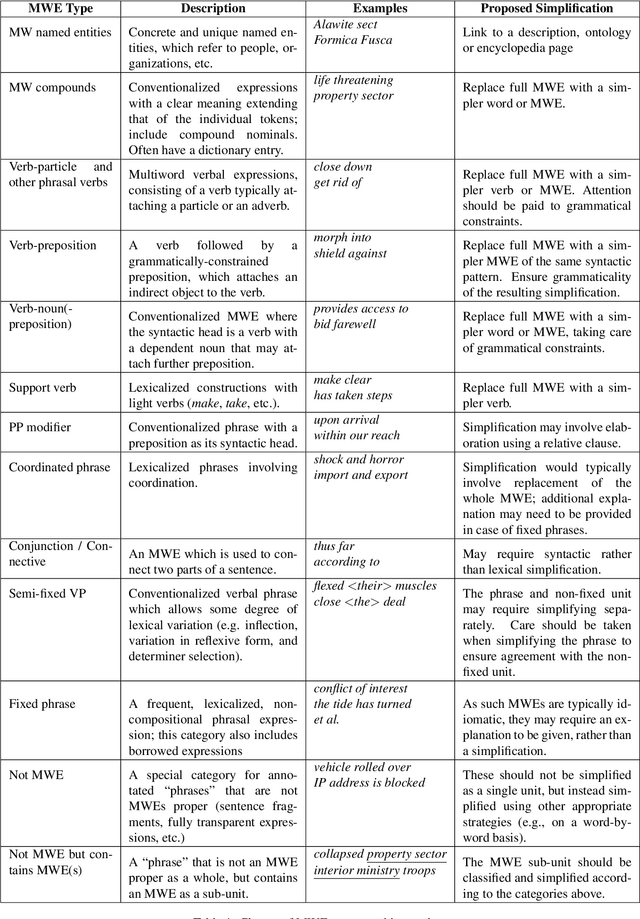



Multiword expressions (MWEs) represent lexemes that should be treated as single lexical units due to their idiosyncratic nature. Multiple NLP applications have been shown to benefit from MWE identification, however the research on lexical complexity of MWEs is still an under-explored area. In this work, we re-annotate the Complex Word Identification Shared Task 2018 dataset of Yimam et al. (2017), which provides complexity scores for a range of lexemes, with the types of MWEs. We release the MWE-annotated dataset with this paper, and we believe this dataset represents a valuable resource for the text simplification community. In addition, we investigate which types of expressions are most problematic for native and non-native readers. Finally, we show that a lexical complexity assessment system benefits from the information about MWE types.