 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Open-Ended Information Seeking Goals from Eye Movements in Reading
May 04, 2025When reading, we often have specific information that interests us in a text. For example, you might be reading this paper because you are curious about LLMs for eye movements in reading, the experimental design, or perhaps you only care about the question ``but does it work?''. More broadly, in daily life, people approach texts with any number of text-specific goals that guide their reading behavior. In this work, we ask, for the first time, whether open-ended reading goals can be automatically decoded from eye movements in reading. To address this question, we introduce goal classification and goal reconstruction tasks and evaluation frameworks, and use large-scale eye tracking for reading data in English with hundreds of text-specific information seeking tasks. We develop and compare several discriminative and generative multimodal LLMs that combine eye movements and text for goal classification and goal reconstruction. Our experiments show considerable success on both tasks, suggesting that LLMs can extract valuable information about the readers' text-specific goals from eye movements.
Decoding Reading Goals from Eye Movements
Oct 28, 2024
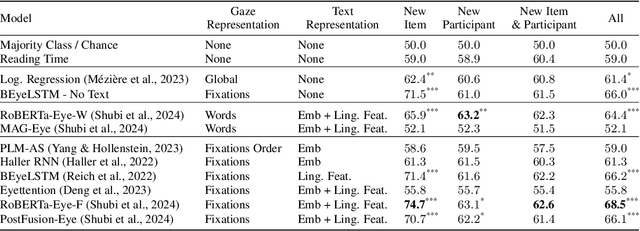
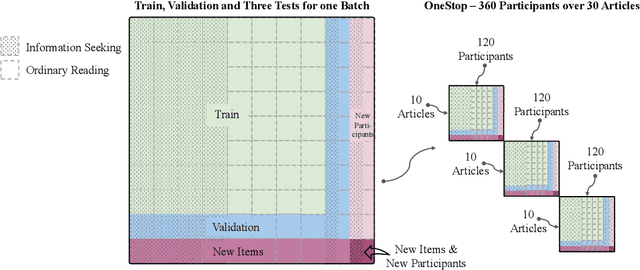
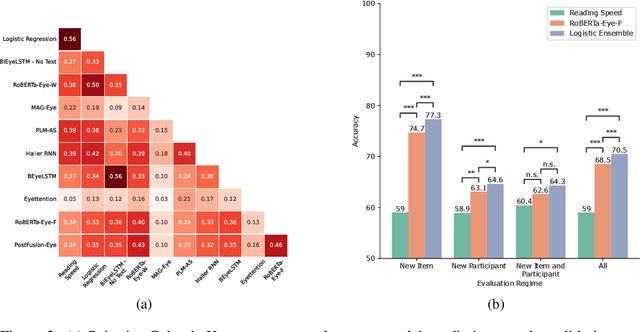
Readers can have different goals with respect to the text they are reading. Can these goals be decoded from the pattern of their eye movements over the text? In this work, we examine for the first time whether it is possible to decode two types of reading goals that are common in daily life: information seeking and ordinary reading. Using large scale eye-tracking data, we apply to this task a wide range of state-of-the-art models for eye movements and text that cover different architectural and data representation strategies, and further introduce a new model ensemble. We systematically evaluate these models at three levels of generalization: new textual item, new participant, and the combination of both. We find that eye movements contain highly valuable signals for this task. We further perform an error analysis which builds on prior empirical findings on differences between ordinary reading and information seeking and leverages rich textual annotations. This analysis reveals key properties of textual items and participant eye movements that contribute to the difficulty of the task.
The Effect of Surprisal on Reading Times in Information Seeking and Repeated Reading
Oct 10, 2024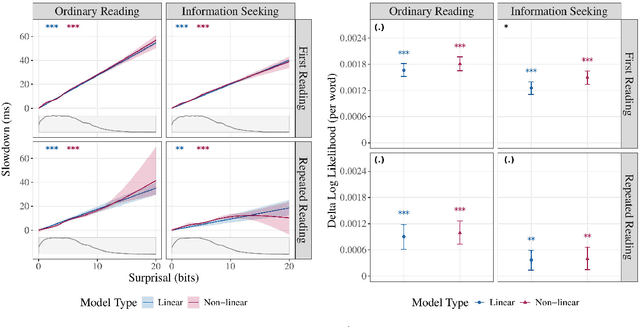
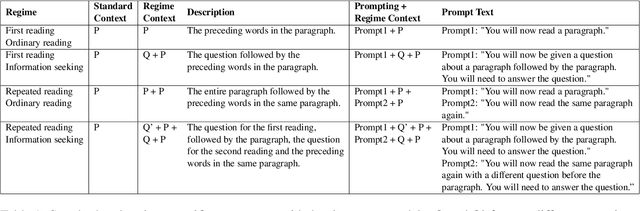
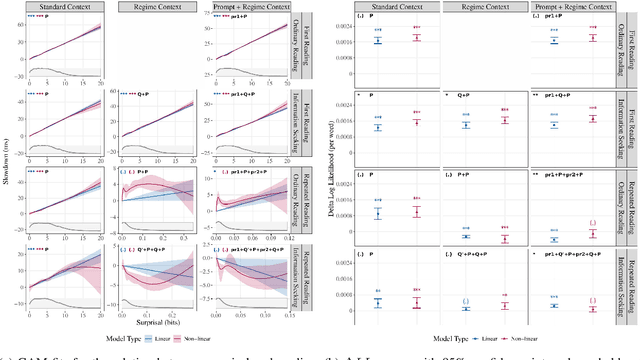
The effect of surprisal on processing difficulty has been a central topic of investigation in psycholinguistics. Here, we use eyetracking data to examine three language processing regimes that are common in daily life but have not been addressed with respect to this question: information seeking, repeated processing, and the combination of the two. Using standard regime-agnostic surprisal estimates we find that the prediction of surprisal theory regarding the presence of a linear effect of surprisal on processing times, extends to these regimes. However, when using surprisal estimates from regime-specific contexts that match the contexts and tasks given to humans, we find that in information seeking, such estimates do not improve the predictive power of processing times compared to standard surprisals. Further, regime-specific contexts yield near zero surprisal estimates with no predictive power for processing times in repeated reading. These findings point to misalignments of task and memory representations between humans and current language models, and question the extent to which such models can be used for estimating cognitively relevant quantities. We further discuss theoretical challenges posed by these results.
Fine-Grained Prediction of Reading Comprehension from Eye Movements
Oct 06, 2024Can human reading comprehension be assessed from eye movements in reading? In this work, we address this longstanding question using large-scale eyetracking data over textual materials that are geared towards behavioral analyses of reading comprehension. We focus on a fine-grained and largely unaddressed task of predicting reading comprehension from eye movements at the level of a single question over a passage. We tackle this task using three new multimodal language models, as well as a battery of prior models from the literature. We evaluate the models' ability to generalize to new textual items, new participants, and the combination of both, in two different reading regimes, ordinary reading and information seeking. The evaluations suggest that although the task is highly challenging, eye movements contain useful signals for fine-grained prediction of reading comprehension. Code and data will be made publicly available.
Predicting Text Readability from Scrolling Interactions
May 13, 2021
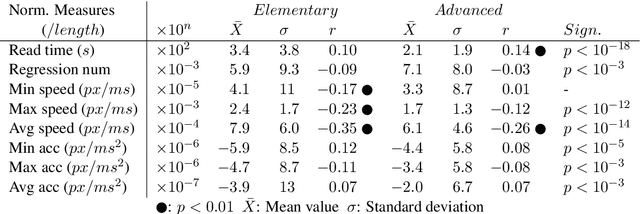


Judging the readability of text has many important applications, for instance when performing text simplification or when sourcing reading material for language learners. In this paper, we present a 518 participant study which investigates how scrolling behaviour relates to the readability of a text. We make our dataset publicly available and show that (1) there are statistically significant differences in the way readers interact with text depending on the text level, (2) such measures can be used to predict the readability of text, and (3) the background of a reader impacts their reading interactions and the factors contributing to text difficulty.
Classifying Syntactic Errors in Learner Language
Oct 27, 2020
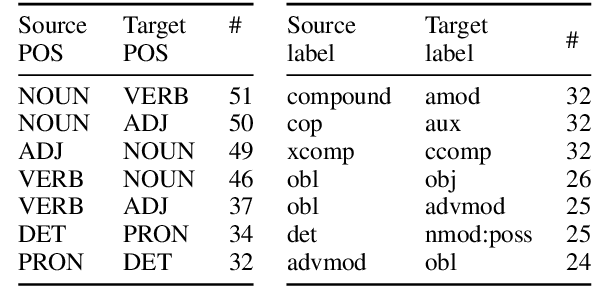
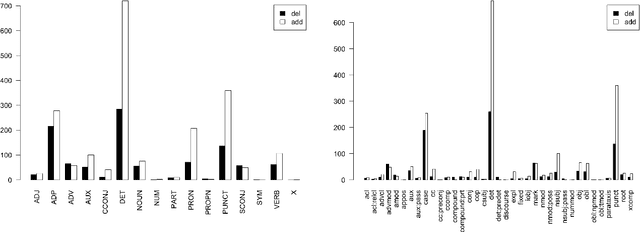
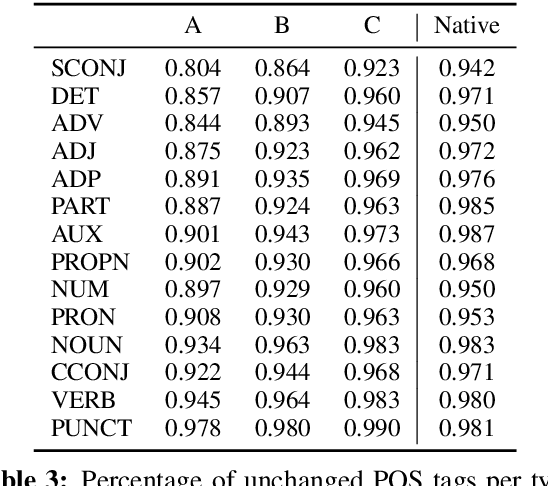
We present a method for classifying syntactic errors in learner language, namely errors whose correction alters the morphosyntactic structure of a sentence. The methodology builds on the established Universal Dependencies syntactic representation scheme, and provides complementary information to other error-classification systems. Unlike existing error classification methods, our method is applicable across languages, which we showcase by producing a detailed picture of syntactic errors in learner English and learner Russian. We further demonstrate the utility of the methodology for analyzing the outputs of leading Grammatical Error Correction (GEC) systems.
Bridging Information-Seeking Human Gaze and Machine Reading Comprehension
Oct 15, 2020
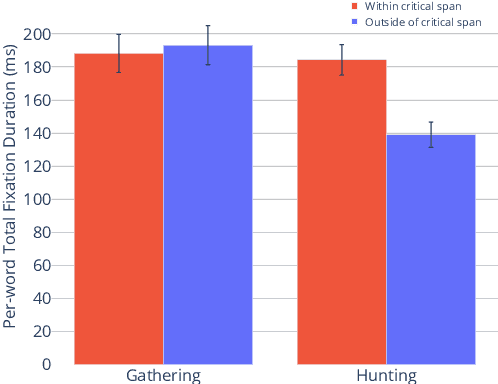
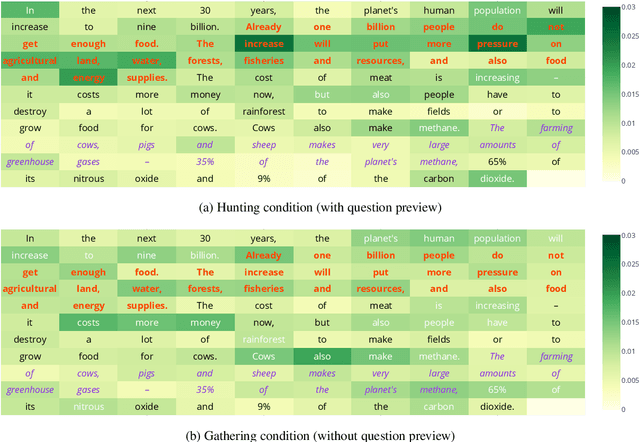
In this work, we analyze how human gaze during reading comprehension is conditioned on the given reading comprehension question, and whether this signal can be beneficial for machine reading comprehension. To this end, we collect a new eye-tracking dataset with a large number of participants engaging in a multiple choice reading comprehension task. Our analysis of this data reveals increased fixation times over parts of the text that are most relevant for answering the question. Motivated by this finding, we propose making automated reading comprehension more human-like by mimicking human information-seeking reading behavior during reading comprehension. We demonstrate that this approach leads to performance gains on multiple choice question answering in English for a state-of-the-art reading comprehension model.
STARC: Structured Annotations for Reading Comprehension
Apr 30, 2020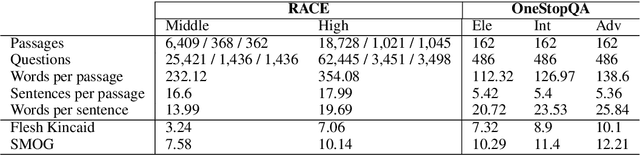

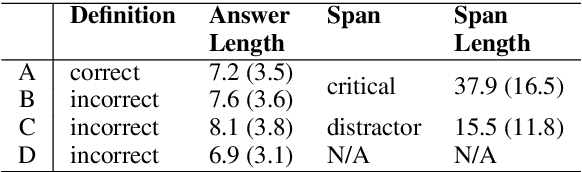

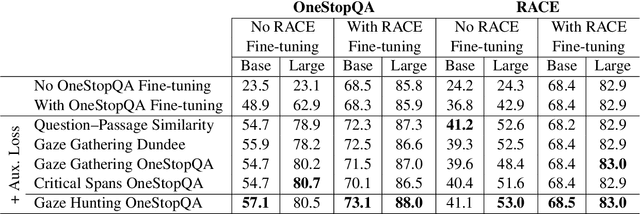
We present STARC (Structured Annotations for Reading Comprehension), a new annotation framework for assessing reading comprehension with multiple choice questions. Our framework introduces a principled structure for the answer choices and ties them to textual span annotations. The framework is implemented in OneStopQA, a new high-quality dataset for evaluation and analysis of reading comprehension in English. We use this dataset to demonstrate that STARC can be leveraged for a key new application for the development of SAT-like reading comprehension materials: automatic annotation quality probing via span ablation experiments. We further show that it enables in-depth analyses and comparisons between machine and human reading comprehension behavior, including error distributions and guessing ability. Our experiments also reveal that the standard multiple choice dataset in NLP, RACE, is limited in its ability to measure reading comprehension. 47% of its questions can be guessed by machines without accessing the passage, and 18% are unanimously judged by humans as not having a unique correct answer. OneStopQA provides an alternative test set for reading comprehension which alleviates these shortcomings and has a substantially higher human ceiling performance.
Modeling Language Variation and Universals: A Survey on Typological Linguistics for Natural Language Processing
Jul 02, 2018Addressing the cross-lingual variation of grammatical structures and meaning categorization is a key challenge for multilingual Natural Language Processing. The lack of resources for the majority of the world's languages makes supervised learning not viable. Moreover, the performance of most algorithms is hampered by language-specific biases and the neglect of informative multilingual data. The discipline of Linguistic Typology provides a principled framework to compare languages systematically and empirically and documents their variation in publicly available databases. These enshrine crucial information to design language-independent algorithms and refine techniques devised to mitigate the above-mentioned issues, including cross-lingual transfer and multilingual joint models, with typological features. In this survey, we demonstrate that typology is beneficial to several NLP applications, involving both semantic and syntactic tasks. Moreover, we outline several techniques to extract features from databases or acquire them automatically: these features can be subsequently integrated into multilingual models to tie parameters together cross-lingually or gear a model towards a specific language. Finally, we advocate for a new typology that accounts for the patterns within individual examples rather than entire languages, and for graded categories rather than discrete ones, in oder to bridge the gap with the contextual and continuous nature of machine learning algorithms.
Assessing Language Proficiency from Eye Movements in Reading
Apr 24, 2018
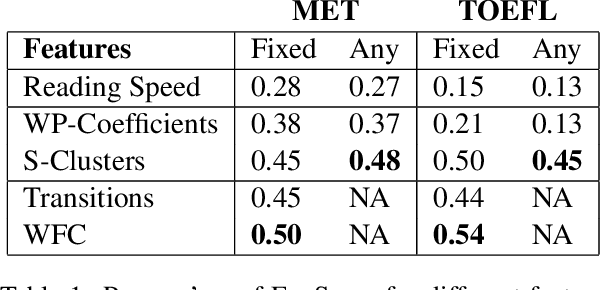
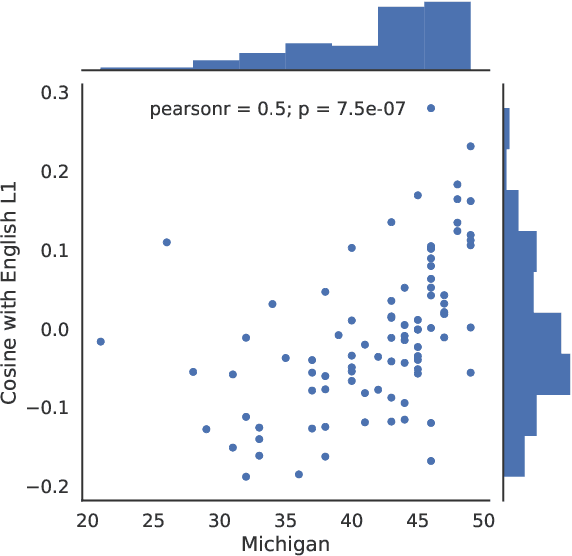
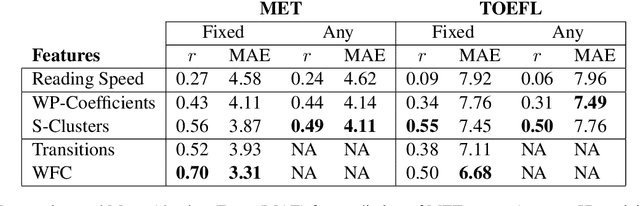
We present a novel approach for determining learners' second language proficiency which utilizes behavioral traces of eye movements during reading. Our approach provides stand-alone eyetracking based English proficiency scores which reflect the extent to which the learner's gaze patterns in reading are similar to those of native English speakers. We show that our scores correlate strongly with standardized English proficiency tests. We also demonstrate that gaze information can be used to accurately predict the outcomes of such tests. Our approach yields the strongest performance when the test taker is presented with a suite of sentences for which we have eyetracking data from other readers. However, it remains effective even using eyetracking with sentences for which eye movement data have not been previously collected. By deriving proficiency as an automatic byproduct of eye movements during ordinary reading, our approach offers a potentially valuable new tool for second language proficiency assessment. More broadly, our results open the door to future methods for inferring reader characteristics from the behavioral traces of reading.