 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring The Impact Of Programming Language Distribution
Feb 03, 2023



Current benchmarks for evaluating neural code models focus on only a small subset of programming languages, excluding many popular languages such as Go or Rust. To ameliorate this issue, we present the BabelCode framework for execution-based evaluation of any benchmark in any language. BabelCode enables new investigations into the qualitative performance of models' memory, runtime, and individual test case results. Additionally, we present a new code translation dataset called Translating Python Programming Puzzles (TP3) from the Python Programming Puzzles (Schuster et al. 2021) benchmark that involves translating expert-level python functions to any language. With both BabelCode and the TP3 benchmark, we investigate if balancing the distributions of 14 languages in a training dataset improves a large language model's performance on low-resource languages. Training a model on a balanced corpus results in, on average, 12.34% higher $pass@k$ across all tasks and languages compared to the baseline. We find that this strategy achieves 66.48% better $pass@k$ on low-resource languages at the cost of only a 12.94% decrease to high-resource languages. In our three translation tasks, this strategy yields, on average, 30.77% better low-resource $pass@k$ while having 19.58% worse high-resource $pass@k$.
Pareto-Optimal Quantized ResNet Is Mostly 4-bit
May 07, 2021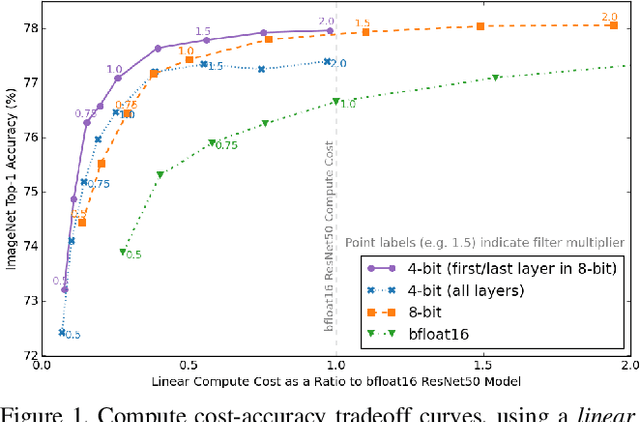


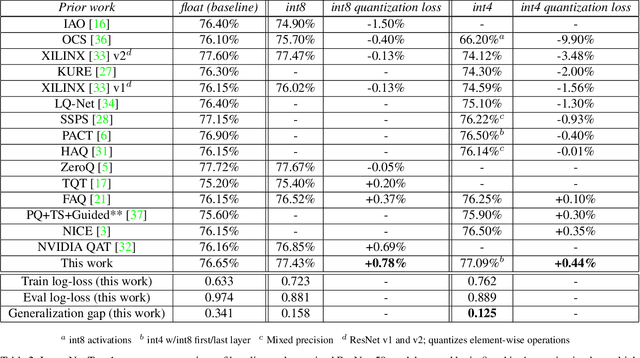
Quantization has become a popular technique to compress neural networks and reduce compute cost, but most prior work focuses on studying quantization without changing the network size. Many real-world applications of neural networks have compute cost and memory budgets, which can be traded off with model quality by changing the number of parameters. In this work, we use ResNet as a case study to systematically investigate the effects of quantization on inference compute cost-quality tradeoff curves. Our results suggest that for each bfloat16 ResNet model, there are quantized models with lower cost and higher accuracy; in other words, the bfloat16 compute cost-quality tradeoff curve is Pareto-dominated by the 4-bit and 8-bit curves, with models primarily quantized to 4-bit yielding the best Pareto curve. Furthermore, we achieve state-of-the-art results on ImageNet for 4-bit ResNet-50 with quantization-aware training, obtaining a top-1 eval accuracy of 77.09%. We demonstrate the regularizing effect of quantization by measuring the generalization gap. The quantization method we used is optimized for practicality: It requires little tuning and is designed with hardware capabilities in mind. Our work motivates further research into optimal numeric formats for quantization, as well as the development of machine learning accelerators supporting these formats. As part of this work, we contribute a quantization library written in JAX, which is open-sourced at https://github.com/google-research/google-research/tree/master/aqt.
Bridging Information-Seeking Human Gaze and Machine Reading Comprehension
Oct 15, 2020
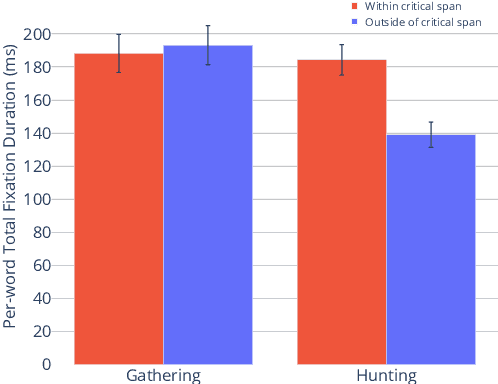
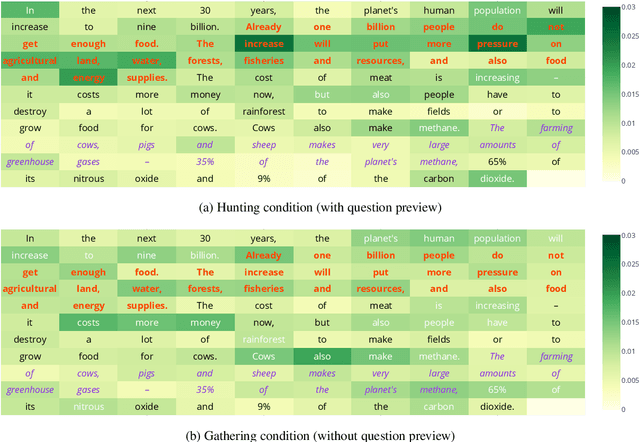
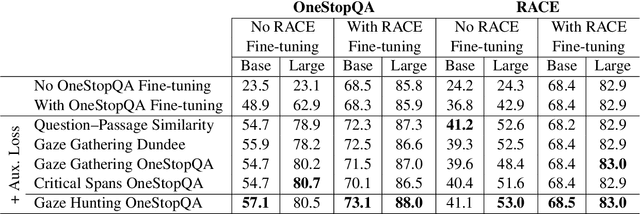
In this work, we analyze how human gaze during reading comprehension is conditioned on the given reading comprehension question, and whether this signal can be beneficial for machine reading comprehension. To this end, we collect a new eye-tracking dataset with a large number of participants engaging in a multiple choice reading comprehension task. Our analysis of this data reveals increased fixation times over parts of the text that are most relevant for answering the question. Motivated by this finding, we propose making automated reading comprehension more human-like by mimicking human information-seeking reading behavior during reading comprehension. We demonstrate that this approach leads to performance gains on multiple choice question answering in English for a state-of-the-art reading comprehension model.
STARC: Structured Annotations for Reading Comprehension
Apr 30, 2020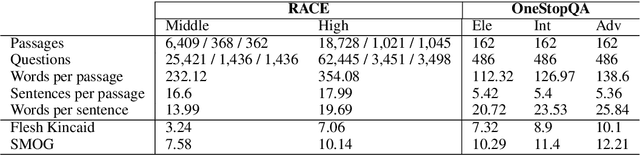

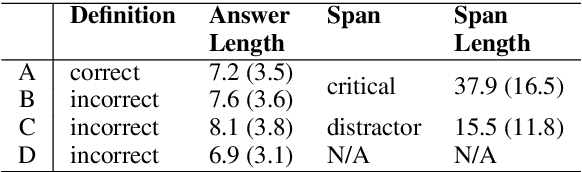

We present STARC (Structured Annotations for Reading Comprehension), a new annotation framework for assessing reading comprehension with multiple choice questions. Our framework introduces a principled structure for the answer choices and ties them to textual span annotations. The framework is implemented in OneStopQA, a new high-quality dataset for evaluation and analysis of reading comprehension in English. We use this dataset to demonstrate that STARC can be leveraged for a key new application for the development of SAT-like reading comprehension materials: automatic annotation quality probing via span ablation experiments. We further show that it enables in-depth analyses and comparisons between machine and human reading comprehension behavior, including error distributions and guessing ability. Our experiments also reveal that the standard multiple choice dataset in NLP, RACE, is limited in its ability to measure reading comprehension. 47% of its questions can be guessed by machines without accessing the passage, and 18% are unanimously judged by humans as not having a unique correct answer. OneStopQA provides an alternative test set for reading comprehension which alleviates these shortcomings and has a substantially higher human ceiling performance.
What's Cookin'? Interpreting Cooking Videos using Text, Speech and Vision
Mar 13, 2015
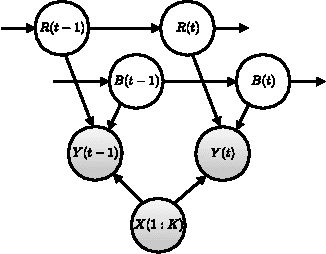
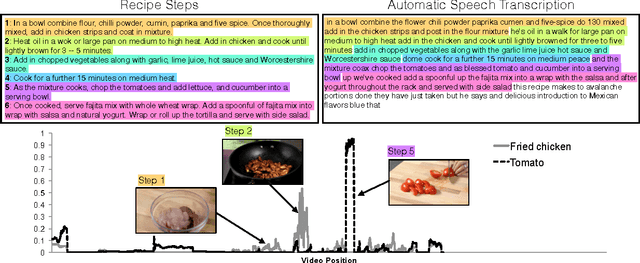
We present a novel method for aligning a sequence of instructions to a video of someone carrying out a task. In particular, we focus on the cooking domain, where the instructions correspond to the recipe. Our technique relies on an HMM to align the recipe steps to the (automatically generated) speech transcript. We then refine this alignment using a state-of-the-art visual food detector, based on a deep convolutional neural network. We show that our technique outperforms simpler techniques based on keyword spotting. It also enables interesting applications, such as automatically illustrating recipes with keyframes, and searching within a video for events of interest.
ClusterCluster: Parallel Markov Chain Monte Carlo for Dirichlet Process Mixtures
Apr 08, 2013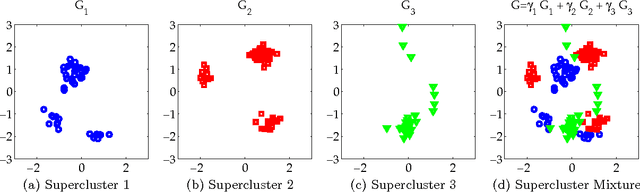

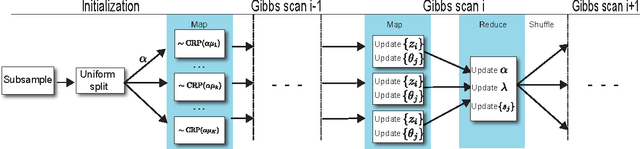
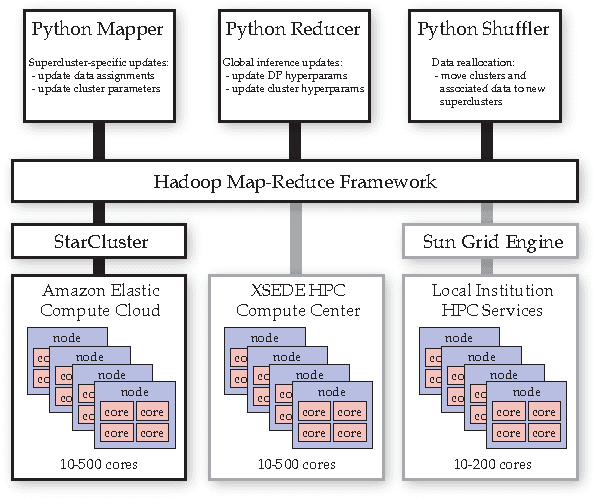
The Dirichlet process (DP) is a fundamental mathematical tool for Bayesian nonparametric modeling, and is widely used in tasks such as density estimation, natural language processing, and time series modeling. Although MCMC inference methods for the DP often provide a gold standard in terms asymptotic accuracy, they can be computationally expensive and are not obviously parallelizable. We propose a reparameterization of the Dirichlet process that induces conditional independencies between the atoms that form the random measure. This conditional independence enables many of the Markov chain transition operators for DP inference to be simulated in parallel across multiple cores. Applied to mixture modeling, our approach enables the Dirichlet process to simultaneously learn clusters that describe the data and superclusters that define the granularity of parallelization. Unlike previous approaches, our technique does not require alteration of the model and leaves the true posterior distribution invariant. It also naturally lends itself to a distributed software implementation in terms of Map-Reduce, which we test in cluster configurations of over 50 machines and 100 cores. We present experiments exploring the parallel efficiency and convergence properties of our approach on both synthetic and real-world data, including runs on 1MM data vectors in 256 dimensions.