 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.
Measuring The Impact Of Programming Language Distribution
Feb 03, 2023



Current benchmarks for evaluating neural code models focus on only a small subset of programming languages, excluding many popular languages such as Go or Rust. To ameliorate this issue, we present the BabelCode framework for execution-based evaluation of any benchmark in any language. BabelCode enables new investigations into the qualitative performance of models' memory, runtime, and individual test case results. Additionally, we present a new code translation dataset called Translating Python Programming Puzzles (TP3) from the Python Programming Puzzles (Schuster et al. 2021) benchmark that involves translating expert-level python functions to any language. With both BabelCode and the TP3 benchmark, we investigate if balancing the distributions of 14 languages in a training dataset improves a large language model's performance on low-resource languages. Training a model on a balanced corpus results in, on average, 12.34% higher $pass@k$ across all tasks and languages compared to the baseline. We find that this strategy achieves 66.48% better $pass@k$ on low-resource languages at the cost of only a 12.94% decrease to high-resource languages. In our three translation tasks, this strategy yields, on average, 30.77% better low-resource $pass@k$ while having 19.58% worse high-resource $pass@k$.
No News is Good News: A Critique of the One Billion Word Benchmark
Oct 25, 2021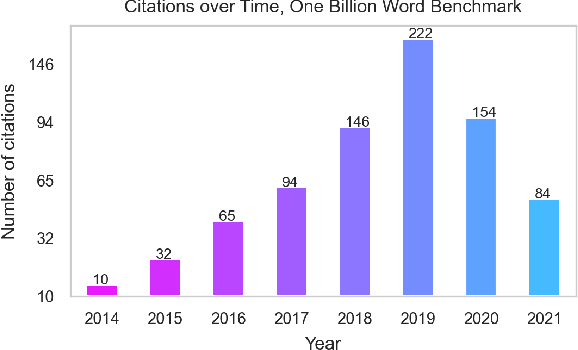
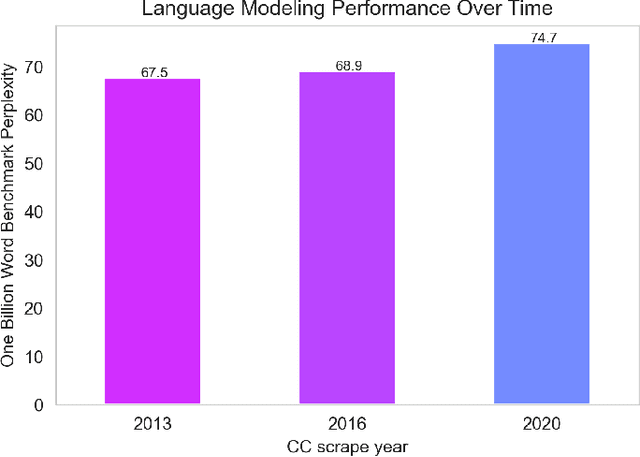
The One Billion Word Benchmark is a dataset derived from the WMT 2011 News Crawl, commonly used to measure language modeling ability in natural language processing. We train models solely on Common Crawl web scrapes partitioned by year, and demonstrate that they perform worse on this task over time due to distributional shift. Analysis of this corpus reveals that it contains several examples of harmful text, as well as outdated references to current events. We suggest that the temporal nature of news and its distribution shift over time makes it poorly suited for measuring language modeling ability, and discuss potential impact and considerations for researchers building language models and evaluation datasets.