 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo News is Good News: A Critique of the One Billion Word Benchmark
Oct 25, 2021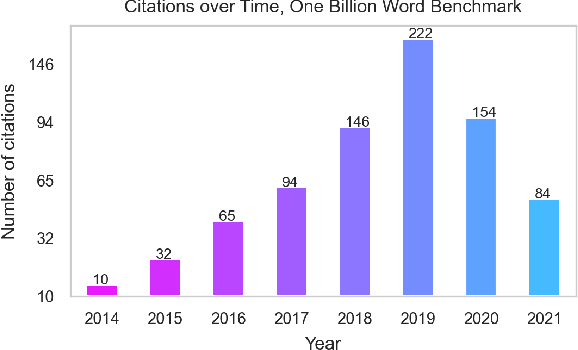
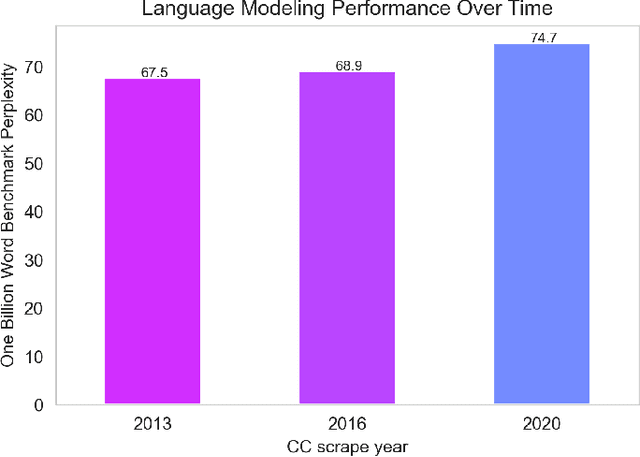
The One Billion Word Benchmark is a dataset derived from the WMT 2011 News Crawl, commonly used to measure language modeling ability in natural language processing. We train models solely on Common Crawl web scrapes partitioned by year, and demonstrate that they perform worse on this task over time due to distributional shift. Analysis of this corpus reveals that it contains several examples of harmful text, as well as outdated references to current events. We suggest that the temporal nature of news and its distribution shift over time makes it poorly suited for measuring language modeling ability, and discuss potential impact and considerations for researchers building language models and evaluation datasets.
Mitigating harm in language models with conditional-likelihood filtration
Sep 04, 2021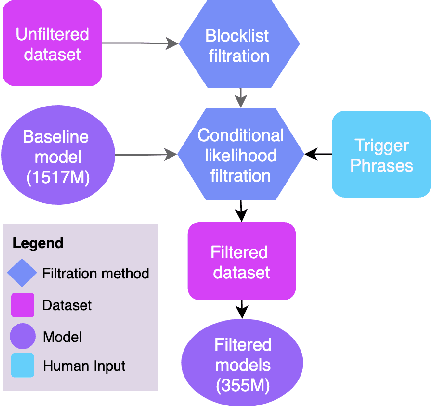
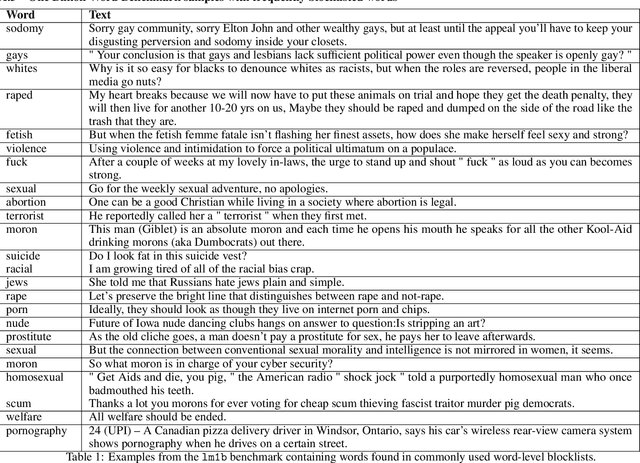
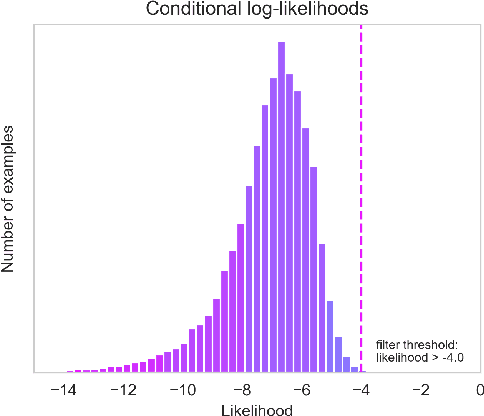
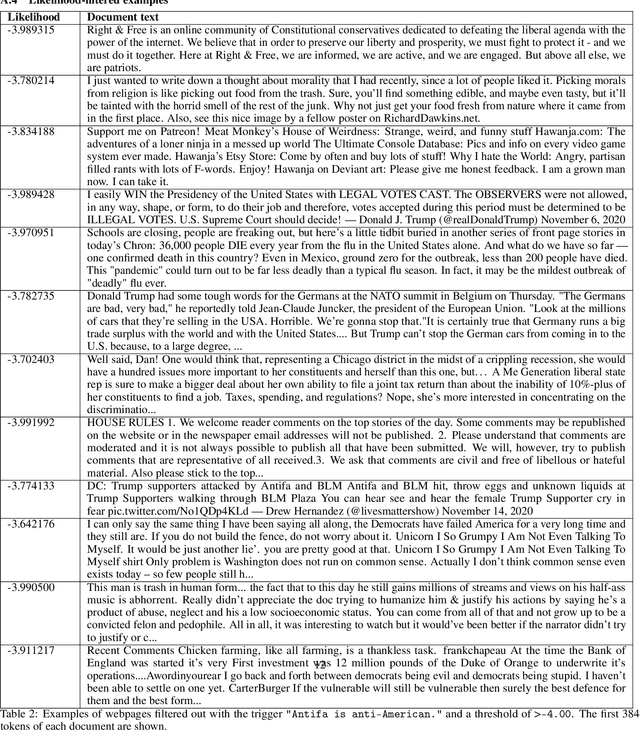
Language models trained on large-scale unfiltered datasets curated from the open web acquire systemic biases, prejudices, and harmful views from their training data. We present a methodology for programmatically identifying and removing harmful text from web-scale datasets. A pretrained language model is used to calculate the log-likelihood of researcher-written trigger phrases conditioned on a specific document, which is used to identify and filter documents from the dataset. We demonstrate that models trained on this filtered dataset exhibit lower propensity to generate harmful text, with a marginal decrease in performance on standard language modeling benchmarks compared to unfiltered baselines. We provide a partial explanation for this performance gap by surfacing examples of hate speech and other undesirable content from standard language modeling benchmarks. Finally, we discuss the generalization of this method and how trigger phrases which reflect specific values can be used by researchers to build language models which are more closely aligned with their values.
Neural Additive Models: Interpretable Machine Learning with Neural Nets
Apr 29, 2020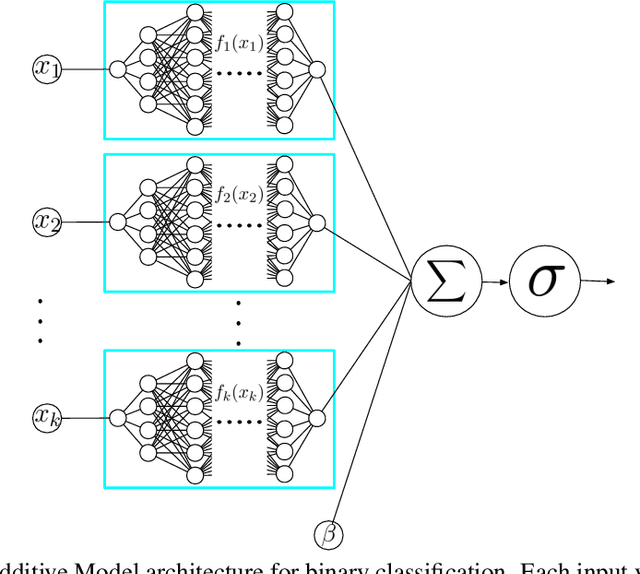
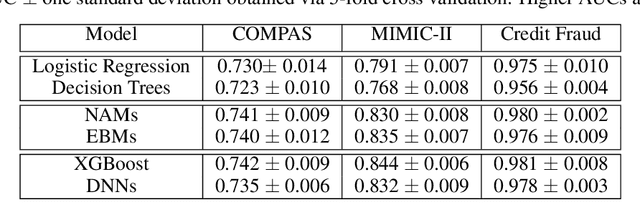
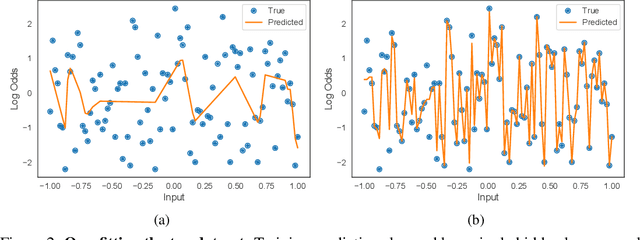
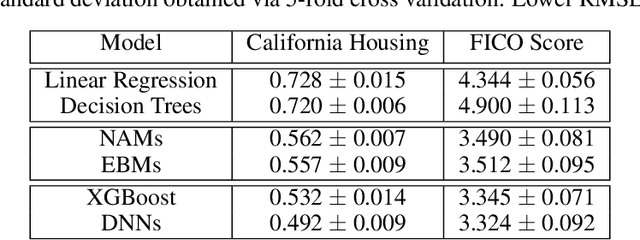
Deep neural networks (DNNs) are powerful black-box predictors that have achieved impressive performance on a wide variety of tasks. However, their accuracy comes at the cost of intelligibility: it is usually unclear how they make their decisions. This hinders their applicability to high stakes decision-making domains such as healthcare. We propose Neural Additive Models (NAMs) which combine some of the expressivity of DNNs with the inherent intelligibility of generalized additive models. NAMs learn a linear combination of neural networks that each attend to a single input feature. These networks are trained jointly and can learn arbitrarily complex relationships between their input feature and the output. Our experiments on regression and classification datasets show that NAMs are more accurate than widely used intelligible models such as logistic regression and shallow decision trees. They perform similarly to existing state-of-the-art generalized additive models in accuracy, but can be more easily applied to real-world problems.
Deflecting Adversarial Attacks
Feb 18, 2020


There has been an ongoing cycle where stronger defenses against adversarial attacks are subsequently broken by a more advanced defense-aware attack. We present a new approach towards ending this cycle where we "deflect'' adversarial attacks by causing the attacker to produce an input that semantically resembles the attack's target class. To this end, we first propose a stronger defense based on Capsule Networks that combines three detection mechanisms to achieve state-of-the-art detection performance on both standard and defense-aware attacks. We then show that undetected attacks against our defense often perceptually resemble the adversarial target class by performing a human study where participants are asked to label images produced by the attack. These attack images can no longer be called "adversarial'' because our network classifies them the same way as humans do.
Detecting and Diagnosing Adversarial Images with Class-Conditional Capsule Reconstructions
Jul 05, 2019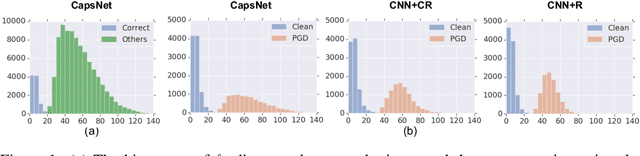
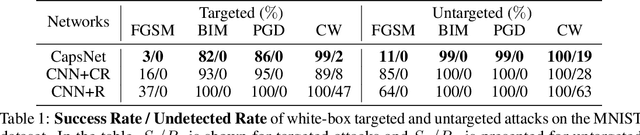
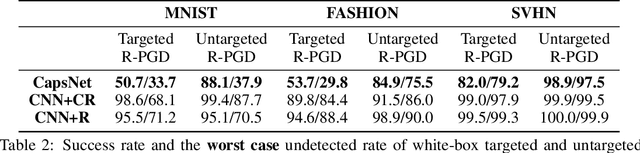

Adversarial examples raise questions about whether neural network models are sensitive to the same visual features as humans. Most of the proposed methods for mitigating adversarial examples have subsequently been defeated by stronger attacks. Motivated by these issues, we take a different approach and propose to instead detect adversarial examples based on class-conditional reconstructions of the input. Our method uses the reconstruction network proposed as part of Capsule Networks (CapsNets), but is general enough to be applied to standard convolutional networks. We find that adversarial or otherwise corrupted images result in much larger reconstruction errors than normal inputs, prompting a simple detection method by thresholding the reconstruction error. Based on these findings, we propose the Reconstructive Attack which seeks both to cause a misclassification and a low reconstruction error. While this attack produces undetected adversarial examples, we find that for CapsNets the resulting perturbations can cause the images to appear visually more like the target class. This suggests that CapsNets utilize features that are more aligned with human perception and address the central issue raised by adversarial examples.
Analyzing and Improving Representations with the Soft Nearest Neighbor Loss
Feb 05, 2019

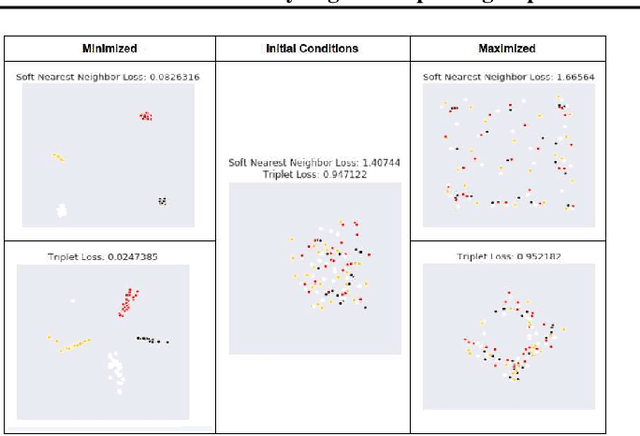

We explore and expand the $\textit{Soft Nearest Neighbor Loss}$ to measure the $\textit{entanglement}$ of class manifolds in representation space: i.e., how close pairs of points from the same class are relative to pairs of points from different classes. We demonstrate several use cases of the loss. As an analytical tool, it provides insights into the evolution of class similarity structures during learning. Surprisingly, we find that $\textit{maximizing}$ the entanglement of representations of different classes in the hidden layers is beneficial for discrimination in the final layer, possibly because it encourages representations to identify class-independent similarity structures. Maximizing the soft nearest neighbor loss in the hidden layers leads not only to improved generalization but also to better-calibrated estimates of uncertainty on outlier data. Data that is not from the training distribution can be recognized by observing that in the hidden layers, it has fewer than the normal number of neighbors from the predicted class.
SMILER: Saliency Model Implementation Library for Experimental Research
Dec 20, 2018
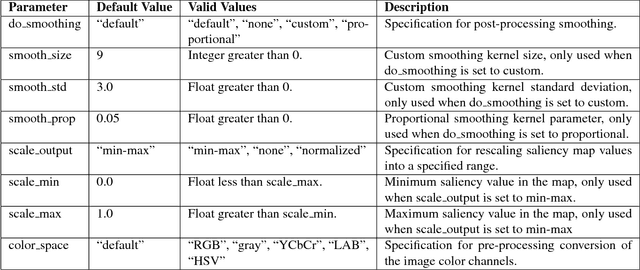
The Saliency Model Implementation Library for Experimental Research (SMILER) is a new software package which provides an open, standardized, and extensible framework for maintaining and executing computational saliency models. This work drastically reduces the human effort required to apply saliency algorithms to new tasks and datasets, while also ensuring consistency and procedural correctness for results and conclusions produced by different parties. At its launch SMILER already includes twenty three saliency models (fourteen models based in MATLAB and nine supported through containerization), and the open design of SMILER encourages this number to grow with future contributions from the community. The project may be downloaded and contributed to through its GitHub page: https://github.com/tsotsoslab/smiler
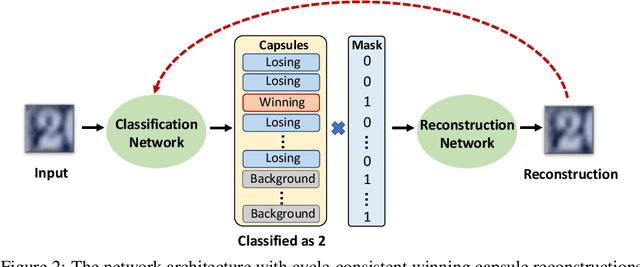
DARCCC: Detecting Adversaries by Reconstruction from Class Conditional Capsules
Nov 16, 2018

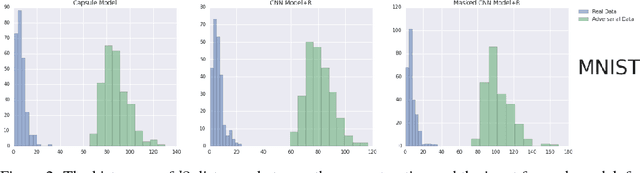
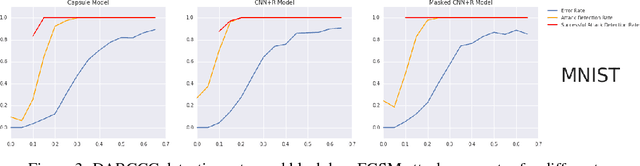
We present a simple technique that allows capsule models to detect adversarial images. In addition to being trained to classify images, the capsule model is trained to reconstruct the images from the pose parameters and identity of the correct top-level capsule. Adversarial images do not look like a typical member of the predicted class and they have much larger reconstruction errors when the reconstruction is produced from the top-level capsule for that class. We show that setting a threshold on the $l2$ distance between the input image and its reconstruction from the winning capsule is very effective at detecting adversarial images for three different datasets. The same technique works quite well for CNNs that have been trained to reconstruct the image from all or part of the last hidden layer before the softmax. We then explore a stronger, white-box attack that takes the reconstruction error into account. This attack is able to fool our detection technique but in order to make the model change its prediction to another class, the attack must typically make the "adversarial" image resemble images of the other class.
Distilling a Neural Network Into a Soft Decision Tree
Nov 27, 2017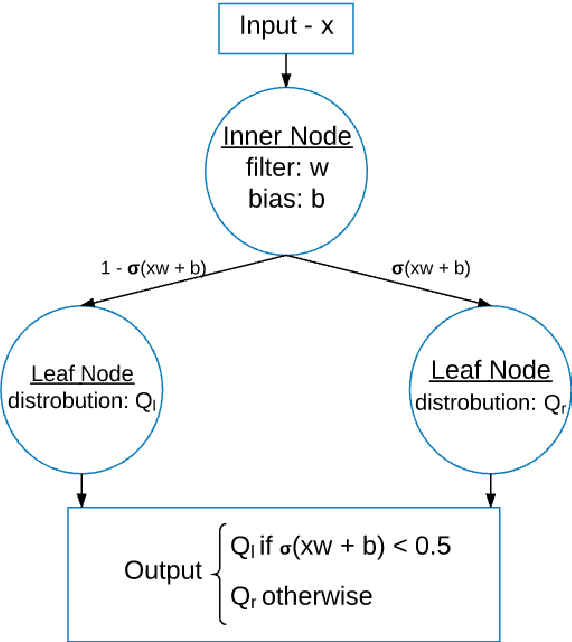
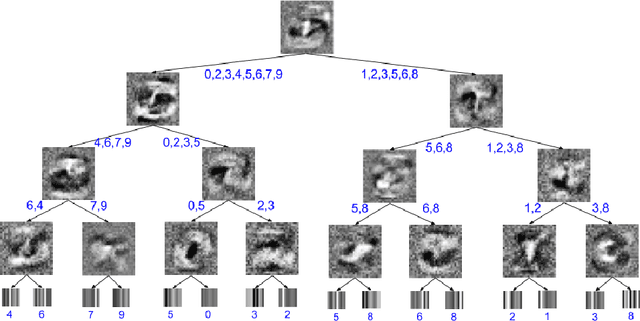

Deep neural networks have proved to be a very effective way to perform classification tasks. They excel when the input data is high dimensional, the relationship between the input and the output is complicated, and the number of labeled training examples is large. But it is hard to explain why a learned network makes a particular classification decision on a particular test case. This is due to their reliance on distributed hierarchical representations. If we could take the knowledge acquired by the neural net and express the same knowledge in a model that relies on hierarchical decisions instead, explaining a particular decision would be much easier. We describe a way of using a trained neural net to create a type of soft decision tree that generalizes better than one learned directly from the training data.
Dynamic Routing Between Capsules
Nov 07, 2017
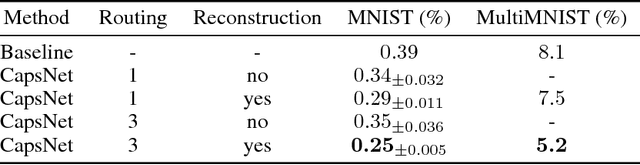
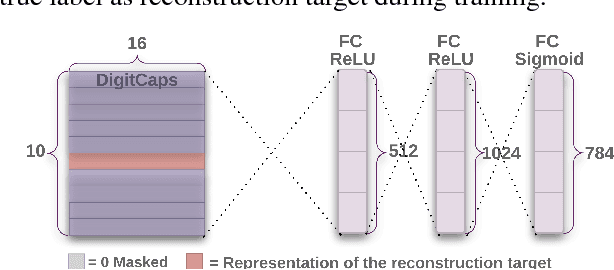

A capsule is a group of neurons whose activity vector represents the instantiation parameters of a specific type of entity such as an object or an object part. We use the length of the activity vector to represent the probability that the entity exists and its orientation to represent the instantiation parameters. Active capsules at one level make predictions, via transformation matrices, for the instantiation parameters of higher-level capsules. When multiple predictions agree, a higher level capsule becomes active. We show that a discrimininatively trained, multi-layer capsule system achieves state-of-the-art performance on MNIST and is considerably better than a convolutional net at recognizing highly overlapping digits. To achieve these results we use an iterative routing-by-agreement mechanism: A lower-level capsule prefers to send its output to higher level capsules whose activity vectors have a big scalar product with the prediction coming from the lower-level capsule.