 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdge Detection for Satellite Images without Deep Networks
May 26, 2021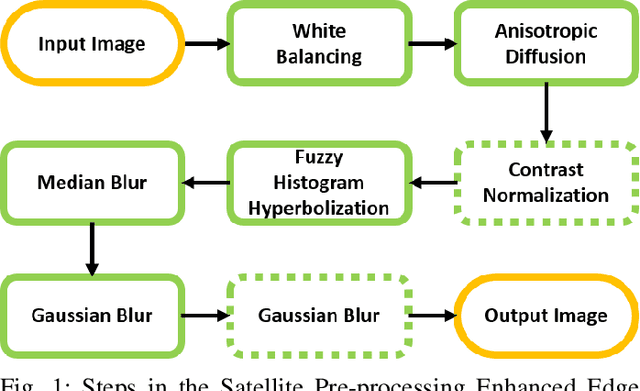
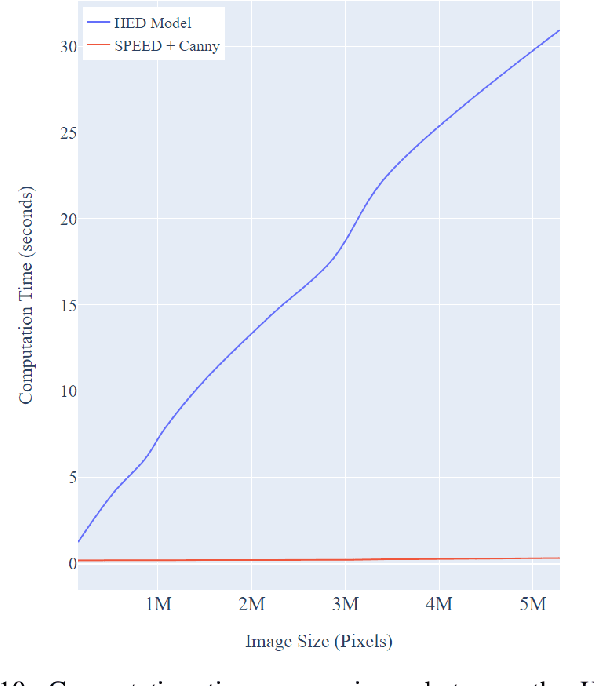
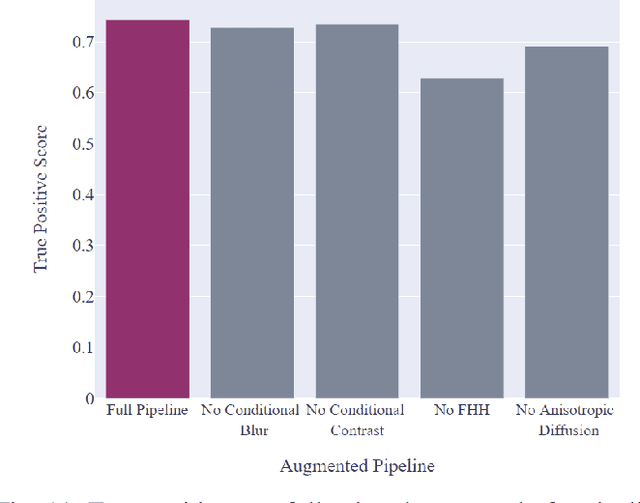
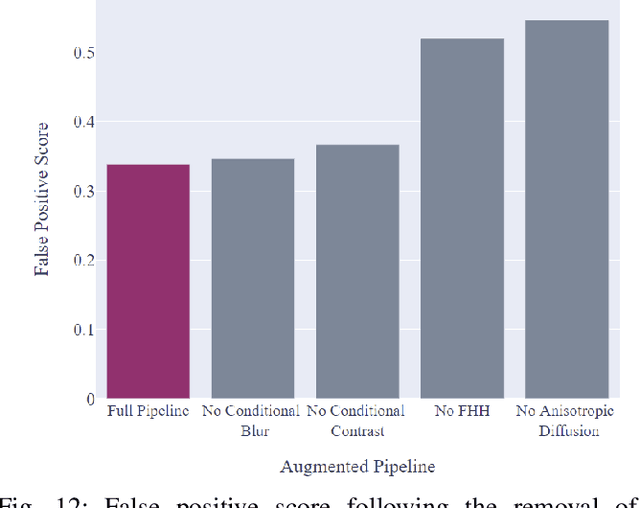
Satellite imagery is widely used in many application sectors, including agriculture, navigation, and urban planning. Frequently, satellite imagery involves both large numbers of images as well as high pixel counts, making satellite datasets computationally expensive to analyze. Recent approaches to satellite image analysis have largely emphasized deep learning methods. Though extremely powerful, deep learning has some drawbacks, including the requirement of specialized computing hardware and a high reliance on training data. When dealing with large satellite datasets, the cost of both computational resources and training data annotation may be prohibitive.
An Empirical Method to Quantify the Peripheral Performance Degradation in Deep Networks
Dec 04, 2020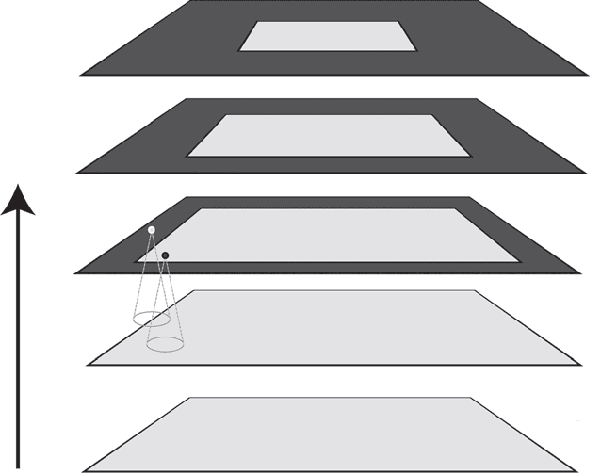


When applying a convolutional kernel to an image, if the output is to remain the same size as the input then some form of padding is required around the image boundary, meaning that for each layer of convolution in a convolutional neural network (CNN), a strip of pixels equal to the half-width of the kernel size is produced with a non-veridical representation. Although most CNN kernels are small to reduce the parameter load of a network, this non-veridical area compounds with each convolutional layer. The tendency toward deeper and deeper networks combined with stride-based down-sampling means that the propagation of this region can end up covering a non-negligable portion of the image. Although this issue with convolutions has been well acknowledged over the years, the impact of this degraded peripheral representation on modern network behavior has not been fully quantified. What are the limits of translation invariance? Does image padding successfully mitigate the issue, or is performance affected as an object moves between the image border and center? Using Mask R-CNN as an experimental model, we design a dataset and methodology to quantify the spatial dependency of network performance. Our dataset is constructed by inserting objects into high resolution backgrounds, thereby allowing us to crop sub-images which place target objects at specific locations relative to the image border. By probing the behaviour of Mask R-CNN across a selection of target locations, we see clear patterns of performance degredation near the image boundary, and in particular in the image corners. Quantifying both the extent and magnitude of this spatial anisotropy in network performance is important for the deployment of deep networks into unconstrained and realistic environments in which the location of objects or regions of interest are not guaranteed to be well localized within a given image.
Do Saliency Models Detect Odd-One-Out Targets? New Datasets and Evaluations
May 13, 2020
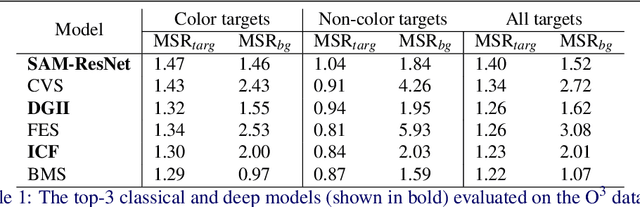

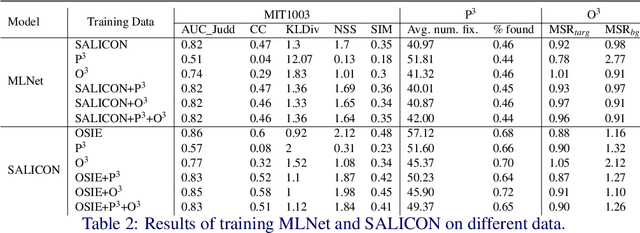
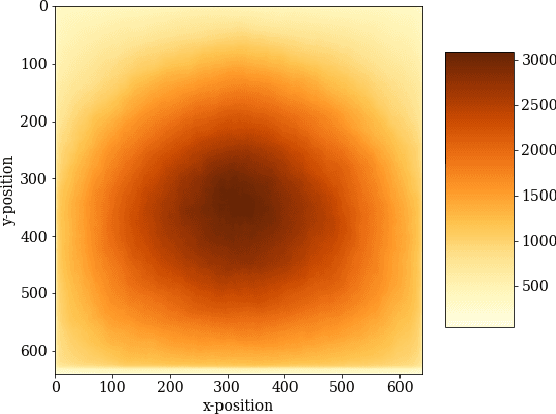
Recent advances in the field of saliency have concentrated on fixation prediction, with benchmarks reaching saturation. However, there is an extensive body of works in psychology and neuroscience that describe aspects of human visual attention that might not be adequately captured by current approaches. Here, we investigate singleton detection, which can be thought of as a canonical example of salience. We introduce two novel datasets, one with psychophysical patterns and one with natural odd-one-out stimuli. Using these datasets we demonstrate through extensive experimentation that nearly all saliency algorithms do not adequately respond to singleton targets in synthetic and natural images. Furthermore, we investigate the effect of training state-of-the-art CNN-based saliency models on these types of stimuli and conclude that the additional training data does not lead to a significant improvement of their ability to find odd-one-out targets.
Early Salient Region Selection Does Not Drive Rapid Visual Categorization
Jan 15, 2019



The current dominant visual processing paradigm in both human and machine research is the feedforward, layered hierarchy of neural-like processing elements. Within this paradigm, visual saliency is seen by many to have a specific role, namely that of early selection. Early selection is thought to enable very fast visual performance by limiting processing to only the most relevant candidate portions of an image. Though this strategy has indeed led to improved processing time efficiency in machine algorithms, at least one set of critical tests of this idea has never been performed with respect to the role of early selection in human vision. How would the best of the current saliency models perform on the stimuli used by experimentalists who first provided evidence for this visual processing paradigm? Would the algorithms really provide correct candidate sub-images to enable fast categorization on those same images? Here, we report on a new series of tests of these questions whose results suggest that it is quite unlikely that such an early selection process has any role in human rapid visual categorization.
SMILER: Saliency Model Implementation Library for Experimental Research
Dec 20, 2018
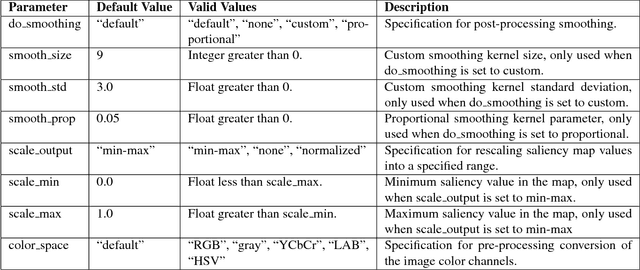
The Saliency Model Implementation Library for Experimental Research (SMILER) is a new software package which provides an open, standardized, and extensible framework for maintaining and executing computational saliency models. This work drastically reduces the human effort required to apply saliency algorithms to new tasks and datasets, while also ensuring consistency and procedural correctness for results and conclusions produced by different parties. At its launch SMILER already includes twenty three saliency models (fourteen models based in MATLAB and nine supported through containerization), and the open design of SMILER encourages this number to grow with future contributions from the community. The project may be downloaded and contributed to through its GitHub page: https://github.com/tsotsoslab/smiler
Saccade Sequence Prediction: Beyond Static Saliency Maps
Nov 29, 2017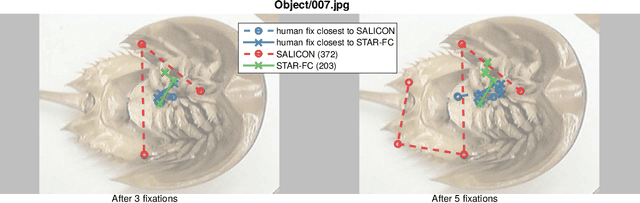
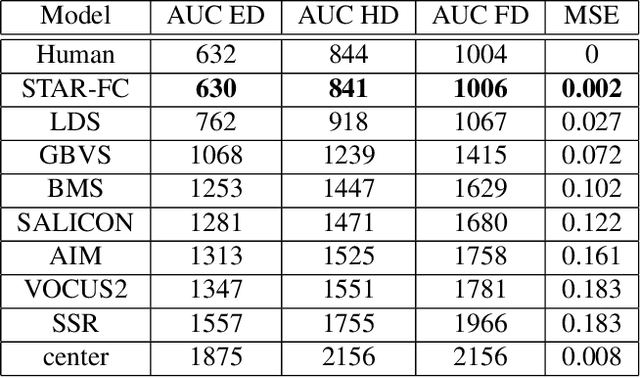

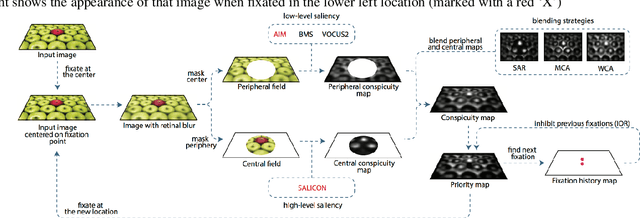
Visual attention is a field with a considerable history, with eye movement control and prediction forming an important subfield. Fixation modeling in the past decades has been largely dominated computationally by a number of highly influential bottom-up saliency models, such as the Itti-Koch-Niebur model. The accuracy of such models has dramatically increased recently due to deep learning. However, on static images the emphasis of these models has largely been based on non-ordered prediction of fixations through a saliency map. Very few implemented models can generate temporally ordered human-like sequences of saccades beyond an initial fixation point. Towards addressing these shortcomings we present STAR-FC, a novel multi-saccade generator based on a central/peripheral integration of deep learning-based saliency and lower-level feature-based saliency. We have evaluated our model using the CAT2000 database, successfully predicting human patterns of fixation with equivalent accuracy and quality compared to what can be achieved by using one human sequence to predict another. This is a significant improvement over fixation sequences predicted by state-of-the-art saliency algorithms.