 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Method to Quantify the Peripheral Performance Degradation in Deep Networks
Paper and Code
Dec 04, 2020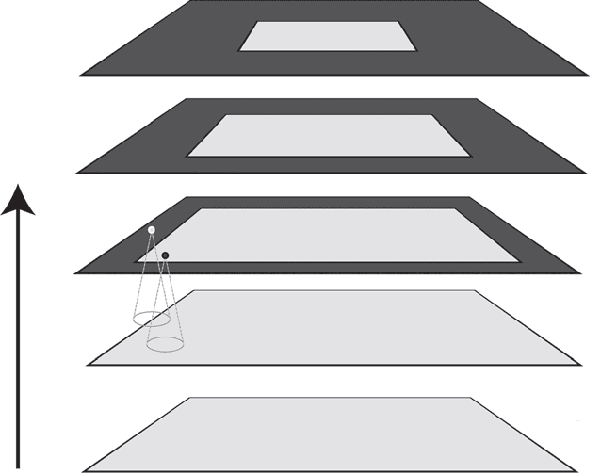
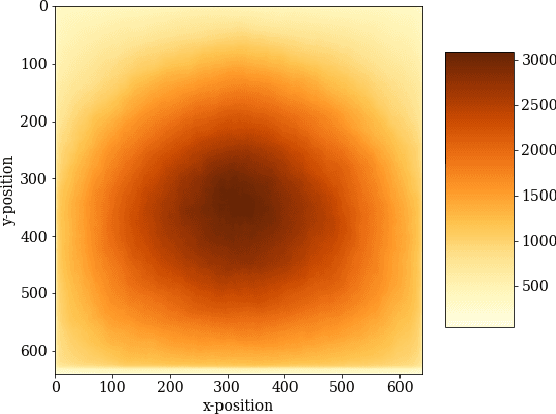


When applying a convolutional kernel to an image, if the output is to remain the same size as the input then some form of padding is required around the image boundary, meaning that for each layer of convolution in a convolutional neural network (CNN), a strip of pixels equal to the half-width of the kernel size is produced with a non-veridical representation. Although most CNN kernels are small to reduce the parameter load of a network, this non-veridical area compounds with each convolutional layer. The tendency toward deeper and deeper networks combined with stride-based down-sampling means that the propagation of this region can end up covering a non-negligable portion of the image. Although this issue with convolutions has been well acknowledged over the years, the impact of this degraded peripheral representation on modern network behavior has not been fully quantified. What are the limits of translation invariance? Does image padding successfully mitigate the issue, or is performance affected as an object moves between the image border and center? Using Mask R-CNN as an experimental model, we design a dataset and methodology to quantify the spatial dependency of network performance. Our dataset is constructed by inserting objects into high resolution backgrounds, thereby allowing us to crop sub-images which place target objects at specific locations relative to the image border. By probing the behaviour of Mask R-CNN across a selection of target locations, we see clear patterns of performance degredation near the image boundary, and in particular in the image corners. Quantifying both the extent and magnitude of this spatial anisotropy in network performance is important for the deployment of deep networks into unconstrained and realistic environments in which the location of objects or regions of interest are not guaranteed to be well localized within a given image.