 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying and Learning Static vs. Dynamic Information in Deep Spatiotemporal Networks
Nov 03, 2022



There is limited understanding of the information captured by deep spatiotemporal models in their intermediate representations. For example, while evidence suggests that action recognition algorithms are heavily influenced by visual appearance in single frames, no quantitative methodology exists for evaluating such static bias in the latent representation compared to bias toward dynamics. We tackle this challenge by proposing an approach for quantifying the static and dynamic biases of any spatiotemporal model, and apply our approach to three tasks, action recognition, automatic video object segmentation (AVOS) and video instance segmentation (VIS). Our key findings are: (i) Most examined models are biased toward static information. (ii) Some datasets that are assumed to be biased toward dynamics are actually biased toward static information. (iii) Individual channels in an architecture can be biased toward static, dynamic or a combination of the two. (iv) Most models converge to their culminating biases in the first half of training. We then explore how these biases affect performance on dynamically biased datasets. For action recognition, we propose StaticDropout, a semantically guided dropout that debiases a model from static information toward dynamics. For AVOS, we design a better combination of fusion and cross connection layers compared with previous architectures.
A Deeper Dive Into What Deep Spatiotemporal Networks Encode: Quantifying Static vs. Dynamic Information
Jun 06, 2022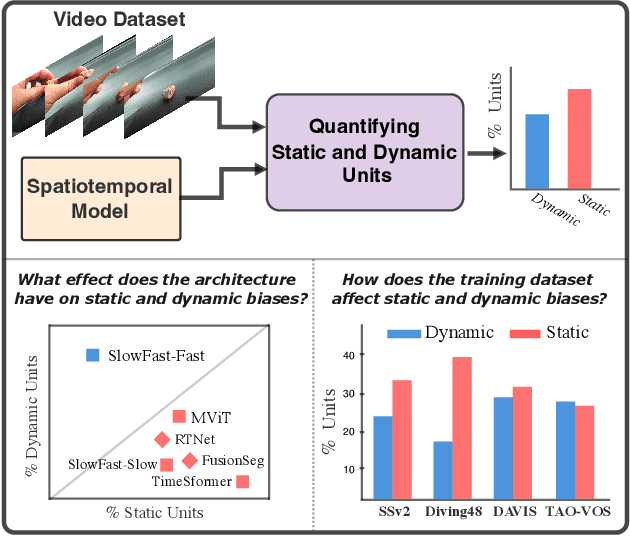
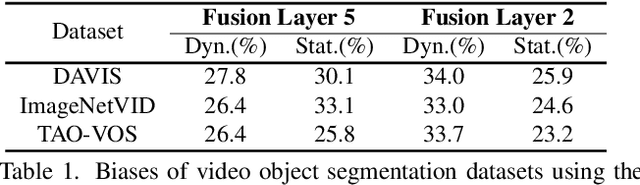
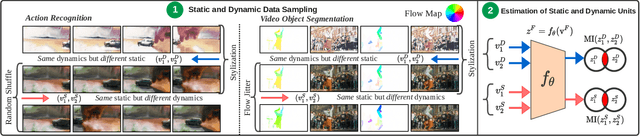
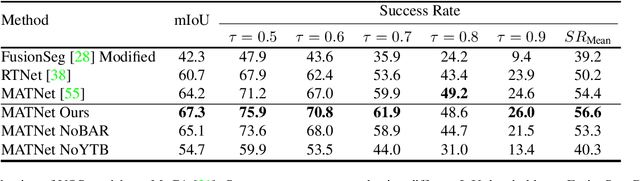
Deep spatiotemporal models are used in a variety of computer vision tasks, such as action recognition and video object segmentation. Currently, there is a limited understanding of what information is captured by these models in their intermediate representations. For example, while it has been observed that action recognition algorithms are heavily influenced by visual appearance in single static frames, there is no quantitative methodology for evaluating such static bias in the latent representation compared to bias toward dynamic information (e.g. motion). We tackle this challenge by proposing a novel approach for quantifying the static and dynamic biases of any spatiotemporal model. To show the efficacy of our approach, we analyse two widely studied tasks, action recognition and video object segmentation. Our key findings are threefold: (i) Most examined spatiotemporal models are biased toward static information; although, certain two-stream architectures with cross-connections show a better balance between the static and dynamic information captured. (ii) Some datasets that are commonly assumed to be biased toward dynamics are actually biased toward static information. (iii) Individual units (channels) in an architecture can be biased toward static, dynamic or a combination of the two.
Simpler Does It: Generating Semantic Labels with Objectness Guidance
Oct 20, 2021
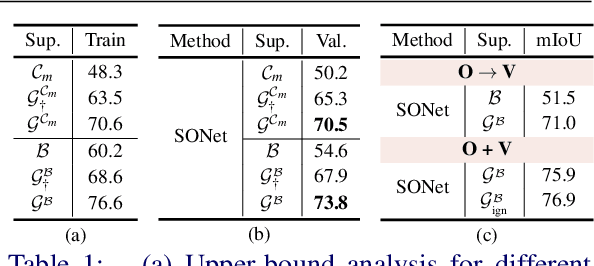
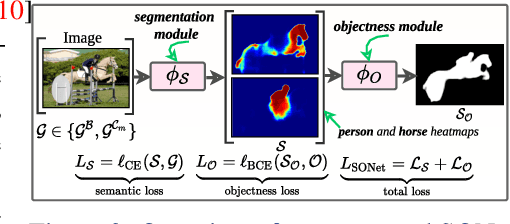
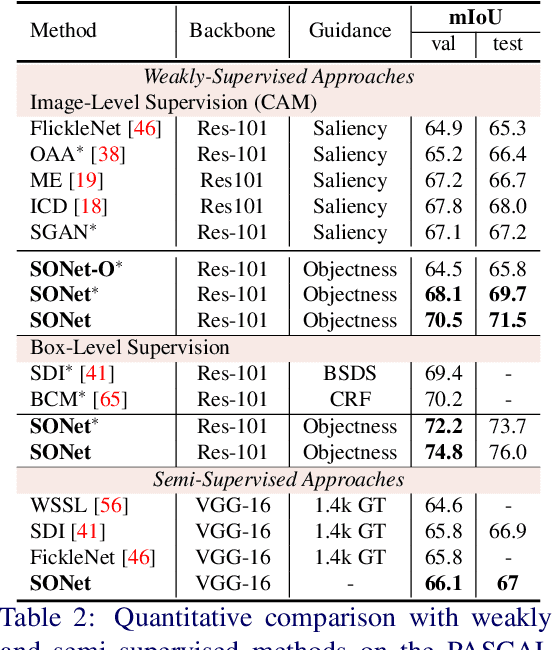
Existing weakly or semi-supervised semantic segmentation methods utilize image or box-level supervision to generate pseudo-labels for weakly labeled images. However, due to the lack of strong supervision, the generated pseudo-labels are often noisy near the object boundaries, which severely impacts the network's ability to learn strong representations. To address this problem, we present a novel framework that generates pseudo-labels for training images, which are then used to train a segmentation model. To generate pseudo-labels, we combine information from: (i) a class agnostic objectness network that learns to recognize object-like regions, and (ii) either image-level or bounding box annotations. We show the efficacy of our approach by demonstrating how the objectness network can naturally be leveraged to generate object-like regions for unseen categories. We then propose an end-to-end multi-task learning strategy, that jointly learns to segment semantics and objectness using the generated pseudo-labels. Extensive experiments demonstrate the high quality of our generated pseudo-labels and effectiveness of the proposed framework in a variety of domains. Our approach achieves better or competitive performance compared to existing weakly-supervised and semi-supervised methods.
SegMix: Co-occurrence Driven Mixup for Semantic Segmentation and Adversarial Robustness
Aug 23, 2021
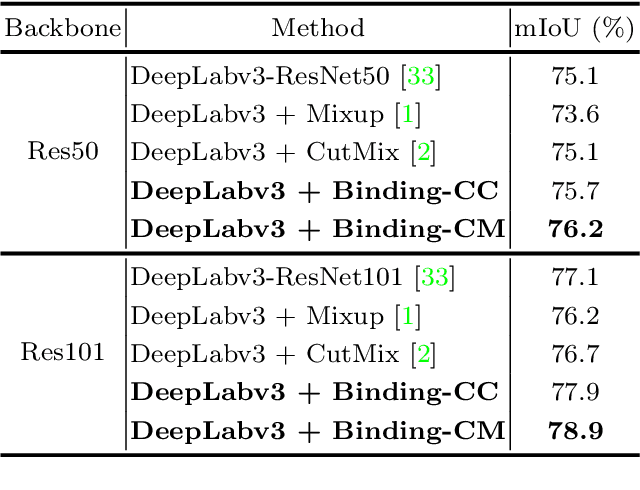
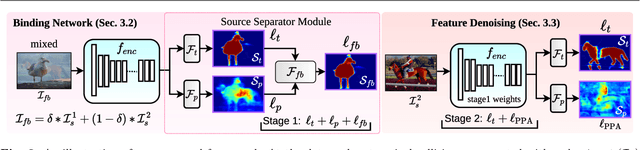

In this paper, we present a strategy for training convolutional neural networks to effectively resolve interference arising from competing hypotheses relating to inter-categorical information throughout the network. The premise is based on the notion of feature binding, which is defined as the process by which activations spread across space and layers in the network are successfully integrated to arrive at a correct inference decision. In our work, this is accomplished for the task of dense image labelling by blending images based on (i) categorical clustering or (ii) the co-occurrence likelihood of categories. We then train a feature binding network which simultaneously segments and separates the blended images. Subsequent feature denoising to suppress noisy activations reveals additional desirable properties and high degrees of successful predictions. Through this process, we reveal a general mechanism, distinct from any prior methods, for boosting the performance of the base segmentation and saliency network while simultaneously increasing robustness to adversarial attacks.
Global Pooling, More than Meets the Eye: Position Information is Encoded Channel-Wise in CNNs
Aug 17, 2021
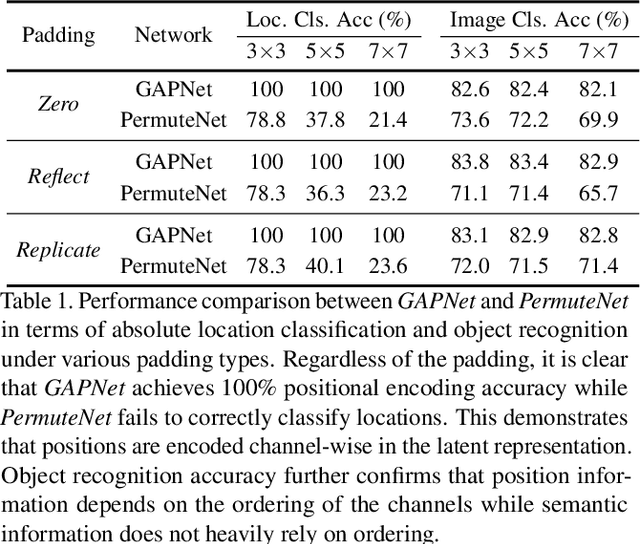
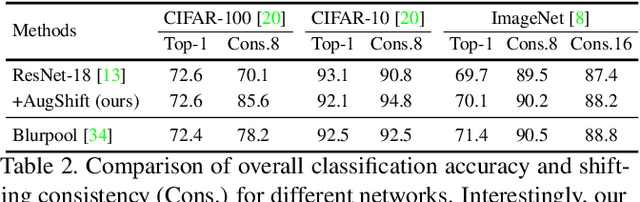
In this paper, we challenge the common assumption that collapsing the spatial dimensions of a 3D (spatial-channel) tensor in a convolutional neural network (CNN) into a vector via global pooling removes all spatial information. Specifically, we demonstrate that positional information is encoded based on the ordering of the channel dimensions, while semantic information is largely not. Following this demonstration, we show the real world impact of these findings by applying them to two applications. First, we propose a simple yet effective data augmentation strategy and loss function which improves the translation invariance of a CNN's output. Second, we propose a method to efficiently determine which channels in the latent representation are responsible for (i) encoding overall position information or (ii) region-specific positions. We first show that semantic segmentation has a significant reliance on the overall position channels to make predictions. We then show for the first time that it is possible to perform a `region-specific' attack, and degrade a network's performance in a particular part of the input. We believe our findings and demonstrated applications will benefit research areas concerned with understanding the characteristics of CNNs.
Position, Padding and Predictions: A Deeper Look at Position Information in CNNs
Jan 28, 2021
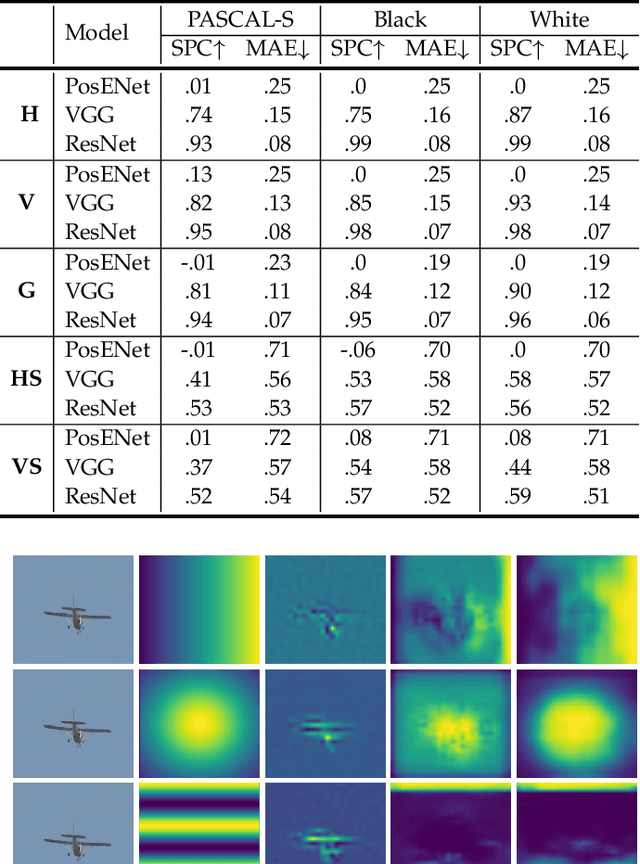
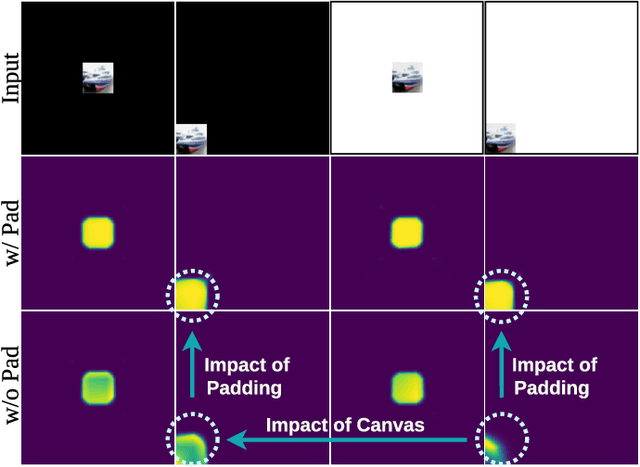
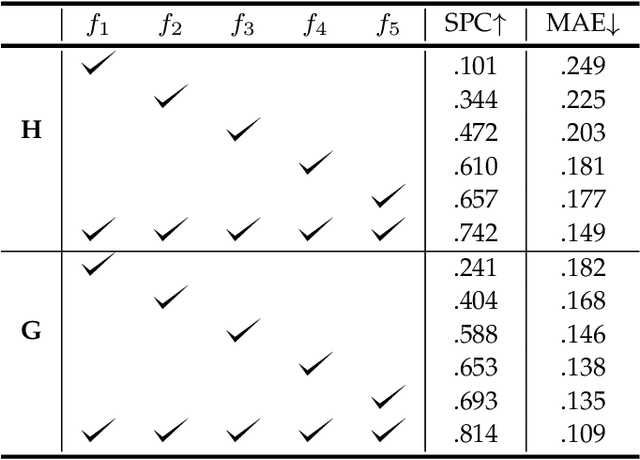
In contrast to fully connected networks, Convolutional Neural Networks (CNNs) achieve efficiency by learning weights associated with local filters with a finite spatial extent. An implication of this is that a filter may know what it is looking at, but not where it is positioned in the image. In this paper, we first test this hypothesis and reveal that a surprising degree of absolute position information is encoded in commonly used CNNs. We show that zero padding drives CNNs to encode position information in their internal representations, while a lack of padding precludes position encoding. This gives rise to deeper questions about the role of position information in CNNs: (i) What boundary heuristics enable optimal position encoding for downstream tasks?; (ii) Does position encoding affect the learning of semantic representations?; (iii) Does position encoding always improve performance? To provide answers, we perform the largest case study to date on the role that padding and border heuristics play in CNNs. We design novel tasks which allow us to quantify boundary effects as a function of the distance to the border. Numerous semantic objectives reveal the effect of the border on semantic representations. Finally, we demonstrate the implications of these findings on multiple real-world tasks to show that position information can both help or hurt performance.
Feature Binding with Category-Dependant MixUp for Semantic Segmentation and Adversarial Robustness
Aug 13, 2020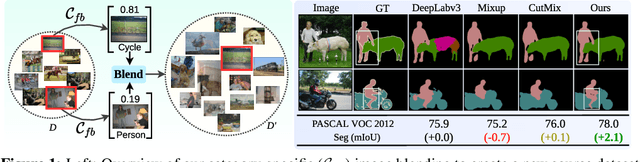

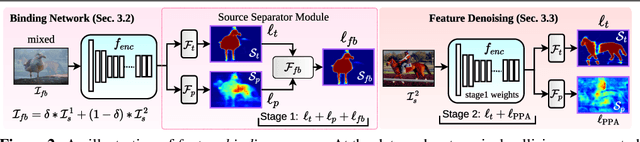
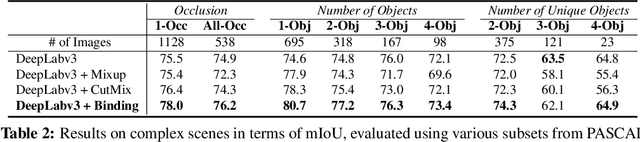
In this paper, we present a strategy for training convolutional neural networks to effectively resolve interference arising from competing hypotheses relating to inter-categorical information throughout the network. The premise is based on the notion of feature binding, which is defined as the process by which activation's spread across space and layers in the network are successfully integrated to arrive at a correct inference decision. In our work, this is accomplished for the task of dense image labelling by blending images based on their class labels, and then training a feature binding network, which simultaneously segments and separates the blended images. Subsequent feature denoising to suppress noisy activations reveals additional desirable properties and high degrees of successful predictions. Through this process, we reveal a general mechanism, distinct from any prior methods, for boosting the performance of the base segmentation network while simultaneously increasing robustness to adversarial attacks.
Revisiting Saliency Metrics: Farthest-Neighbor Area Under Curve
Feb 24, 2020


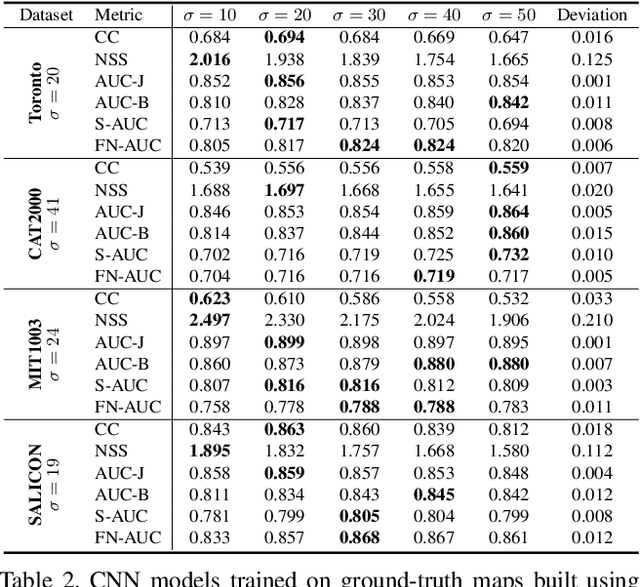
Saliency detection has been widely studied because it plays an important role in various vision applications, but it is difficult to evaluate saliency systems because each measure has its own bias. In this paper, we first revisit the problem of applying the widely used saliency metrics on modern Convolutional Neural Networks(CNNs). Our investigation shows the saliency datasets have been built based on different choices of parameters and CNNs are designed to fit a dataset-specific distribution. Secondly, we show that the Shuffled Area Under Curve(S-AUC) metric still suffers from spatial biases. We propose a new saliency metric based on the AUC property, which aims at sampling a more directional negative set for evaluation, denoted as Farthest-Neighbor AUC(FN-AUC). We also propose a strategy to measure the quality of the sampled negative set. Our experiment shows FN-AUC can measure spatial biases, central and peripheral, more effectively than S-AUC without penalizing the fixation locations. Thirdly, we propose a global smoothing function to overcome the problem of few value degrees (output quantization) in computing AUC metrics. Comparing with random noise, our smooth function can create unique values without losing the relative saliency relationship.
How Much Position Information Do Convolutional Neural Networks Encode?
Jan 22, 2020
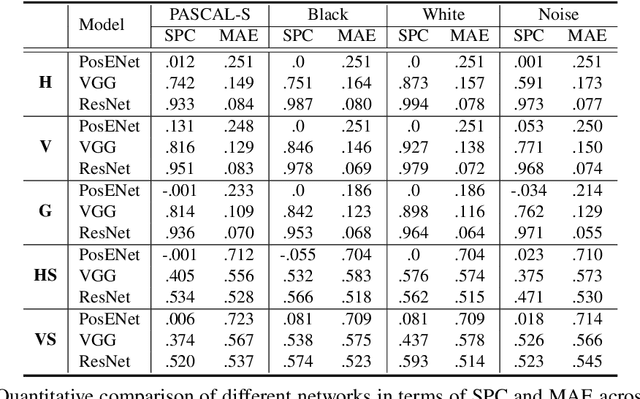
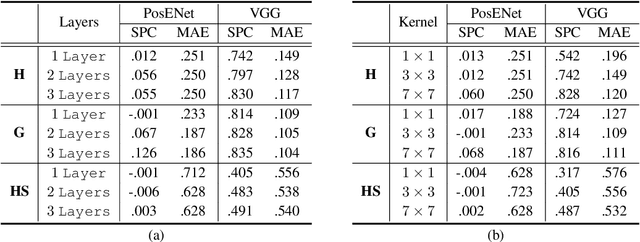
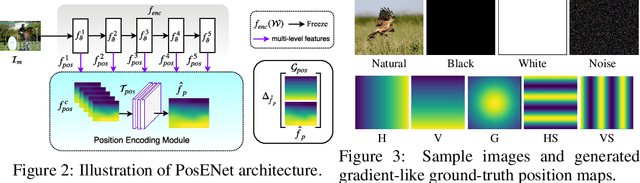
In contrast to fully connected networks, Convolutional Neural Networks (CNNs) achieve efficiency by learning weights associated with local filters with a finite spatial extent. An implication of this is that a filter may know what it is looking at, but not where it is positioned in the image. Information concerning absolute position is inherently useful, and it is reasonable to assume that deep CNNs may implicitly learn to encode this information if there is a means to do so. In this paper, we test this hypothesis revealing the surprising degree of absolute position information that is encoded in commonly used neural networks. A comprehensive set of experiments show the validity of this hypothesis and shed light on how and where this information is represented while offering clues to where positional information is derived from in deep CNNs.
Distributed Iterative Gating Networks for Semantic Segmentation
Sep 28, 2019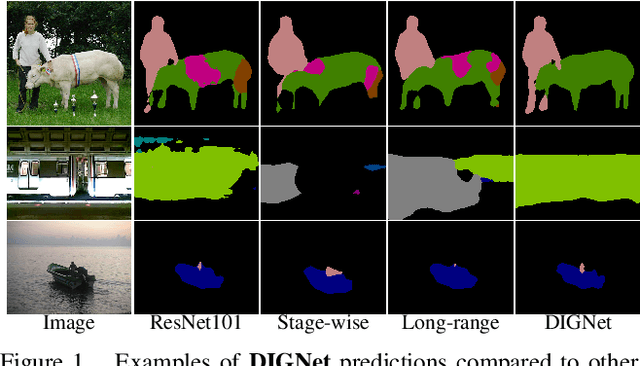

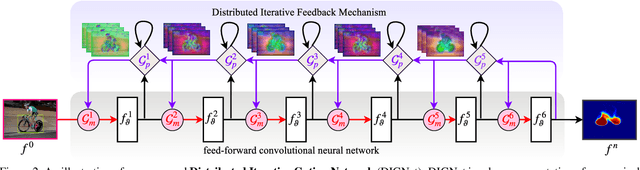
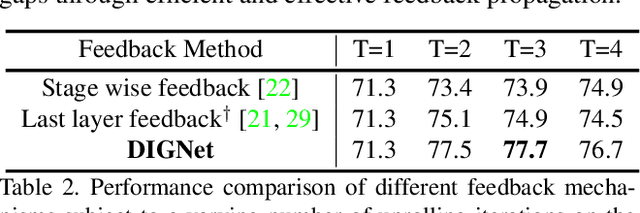
In this paper, we present a canonical structure for controlling information flow in neural networks with an efficient feedback routing mechanism based on a strategy of Distributed Iterative Gating (DIGNet). The structure of this mechanism derives from a strong conceptual foundation and presents a light-weight mechanism for adaptive control of computation similar to recurrent convolutional neural networks by integrating feedback signals with a feed-forward architecture. In contrast to other RNN formulations, DIGNet generates feedback signals in a cascaded manner that implicitly carries information from all the layers above. This cascaded feedback propagation by means of the propagator gates is found to be more effective compared to other feedback mechanisms that use feedback from the output of either the corresponding stage or from the previous stage. Experiments reveal the high degree of capability that this recurrent approach with cascaded feedback presents over feed-forward baselines and other recurrent models for pixel-wise labeling problems on three challenging datasets, PASCAL VOC 2012, COCO-Stuff, and ADE20K.