 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEPAS: Efficient Training with Progressive Activation Sharing
Jan 27, 2026We present a novel method for Efficient training with Progressive Activation Sharing (EPAS). This method bridges progressive training paradigm with the phenomenon of redundant QK (or KV ) activations across deeper layers of transformers. EPAS gradually grows a sharing region during training by switching decoder layers to activation sharing mode. This results in throughput increase due to reduced compute. To utilize deeper layer redundancy, the sharing region starts from the deep end of the model and grows towards the shallow end. The EPAS trained models allow for variable region lengths of activation sharing for different compute budgets during inference. Empirical evaluations with QK activation sharing in LLaMA models ranging from 125M to 7B parameters show up to an 11.1% improvement in training throughput and up to a 29% improvement in inference throughput while maintaining similar loss curve to the baseline models. Furthermore, applying EPAS in continual pretraining to transform TinyLLaMA into an attention-sharing model yields up to a 10% improvement in average accuracy over state-of-the-art methods, emphasizing the significance of progressive training in cross layer activation sharing models.
ECHO-LLaMA: Efficient Caching for High-Performance LLaMA Training
May 22, 2025This paper introduces ECHO-LLaMA, an efficient LLaMA architecture designed to improve both the training speed and inference throughput of LLaMA architectures while maintaining its learning capacity. ECHO-LLaMA transforms LLaMA models into shared KV caching across certain layers, significantly reducing KV computational complexity while maintaining or improving language performance. Experimental results demonstrate that ECHO-LLaMA achieves up to 77\% higher token-per-second throughput during training, up to 16\% higher Model FLOPs Utilization (MFU), and up to 14\% lower loss when trained on an equal number of tokens. Furthermore, on the 1.1B model, ECHO-LLaMA delivers approximately 7\% higher test-time throughput compared to the baseline. By introducing a computationally efficient adaptation mechanism, ECHO-LLaMA offers a scalable and cost-effective solution for pretraining and finetuning large language models, enabling faster and more resource-efficient training without compromising performance.
Understanding Video Transformers for Segmentation: A Survey of Application and Interpretability
Oct 18, 2023Video segmentation encompasses a wide range of categories of problem formulation, e.g., object, scene, actor-action and multimodal video segmentation, for delineating task-specific scene components with pixel-level masks. Recently, approaches in this research area shifted from concentrating on ConvNet-based to transformer-based models. In addition, various interpretability approaches have appeared for transformer models and video temporal dynamics, motivated by the growing interest in basic scientific understanding, model diagnostics and societal implications of real-world deployment. Previous surveys mainly focused on ConvNet models on a subset of video segmentation tasks or transformers for classification tasks. Moreover, component-wise discussion of transformer-based video segmentation models has not yet received due focus. In addition, previous reviews of interpretability methods focused on transformers for classification, while analysis of video temporal dynamics modelling capabilities of video models received less attention. In this survey, we address the above with a thorough discussion of various categories of video segmentation, a component-wise discussion of the state-of-the-art transformer-based models, and a review of related interpretability methods. We first present an introduction to the different video segmentation task categories, their objectives, specific challenges and benchmark datasets. Next, we provide a component-wise review of recent transformer-based models and document the state of the art on different video segmentation tasks. Subsequently, we discuss post-hoc and ante-hoc interpretability methods for transformer models and interpretability methods for understanding the role of the temporal dimension in video models. Finally, we conclude our discussion with future research directions.
DESTINE: Dynamic Goal Queries with Temporal Transductive Alignment for Trajectory Prediction
Oct 11, 2023Predicting temporally consistent road users' trajectories in a multi-agent setting is a challenging task due to unknown characteristics of agents and their varying intentions. Besides using semantic map information and modeling interactions, it is important to build an effective mechanism capable of reasoning about behaviors at different levels of granularity. To this end, we propose Dynamic goal quErieS with temporal Transductive alIgNmEnt (DESTINE) method. Unlike past arts, our approach 1) dynamically predicts agents' goals irrespective of particular road structures, such as lanes, allowing the method to produce a more accurate estimation of destinations; 2) achieves map compliant predictions by generating future trajectories in a coarse-to-fine fashion, where the coarser predictions at a lower frame rate serve as intermediate goals; and 3) uses an attention module designed to temporally align predicted trajectories via masked attention. Using the common Argoverse benchmark dataset, we show that our method achieves state-of-the-art performance on various metrics, and further investigate the contributions of proposed modules via comprehensive ablation studies.
Multiscale Memory Comparator Transformer for Few-Shot Video Segmentation
Jul 15, 2023Few-shot video segmentation is the task of delineating a specific novel class in a query video using few labelled support images. Typical approaches compare support and query features while limiting comparisons to a single feature layer and thereby ignore potentially valuable information. We present a meta-learned Multiscale Memory Comparator (MMC) for few-shot video segmentation that combines information across scales within a transformer decoder. Typical multiscale transformer decoders for segmentation tasks learn a compressed representation, their queries, through information exchange across scales. Unlike previous work, we instead preserve the detailed feature maps during across scale information exchange via a multiscale memory transformer decoding to reduce confusion between the background and novel class. Integral to the approach, we investigate multiple forms of information exchange across scales in different tasks and provide insights with empirical evidence on which to use in each task. The overall comparisons among query and support features benefit from both rich semantics and precise localization. We demonstrate our approach primarily on few-shot video object segmentation and an adapted version on the fully supervised counterpart. In all cases, our approach outperforms the baseline and yields state-of-the-art performance. Our code is publicly available at https://github.com/MSiam/MMC-MultiscaleMemory.
MED-VT: Multiscale Encoder-Decoder Video Transformer with Application to Object Segmentation
Apr 12, 2023
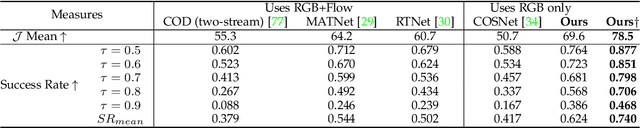
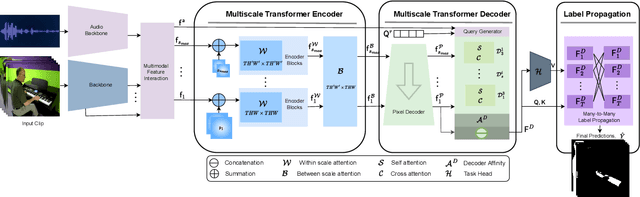

Multiscale video transformers have been explored in a wide variety of vision tasks. To date, however, the multiscale processing has been confined to the encoder or decoder alone. We present a unified multiscale encoder-decoder transformer that is focused on dense prediction tasks in videos. Multiscale representation at both encoder and decoder yields key benefits of implicit extraction of spatiotemporal features (i.e. without reliance on input optical flow) as well as temporal consistency at encoding and coarseto-fine detection for high-level (e.g. object) semantics to guide precise localization at decoding. Moreover, we propose a transductive learning scheme through many-to-many label propagation to provide temporally consistent predictions. We showcase our Multiscale Encoder-Decoder Video Transformer (MED-VT) on Automatic Video Object Segmentation (AVOS) and actor/action segmentation, where we outperform state-of-the-art approaches on multiple benchmarks using only raw images, without using optical flow.
Distributed Iterative Gating Networks for Semantic Segmentation
Sep 28, 2019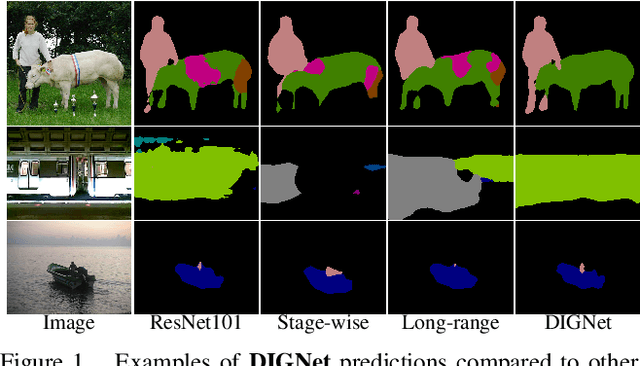

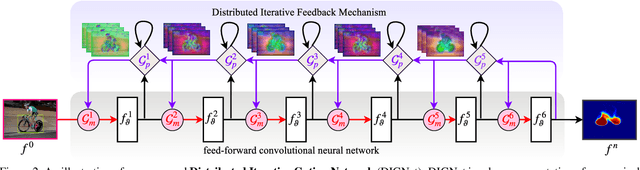
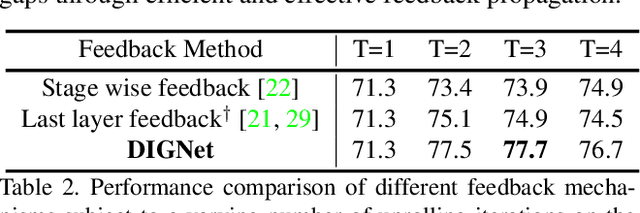
In this paper, we present a canonical structure for controlling information flow in neural networks with an efficient feedback routing mechanism based on a strategy of Distributed Iterative Gating (DIGNet). The structure of this mechanism derives from a strong conceptual foundation and presents a light-weight mechanism for adaptive control of computation similar to recurrent convolutional neural networks by integrating feedback signals with a feed-forward architecture. In contrast to other RNN formulations, DIGNet generates feedback signals in a cascaded manner that implicitly carries information from all the layers above. This cascaded feedback propagation by means of the propagator gates is found to be more effective compared to other feedback mechanisms that use feedback from the output of either the corresponding stage or from the previous stage. Experiments reveal the high degree of capability that this recurrent approach with cascaded feedback presents over feed-forward baselines and other recurrent models for pixel-wise labeling problems on three challenging datasets, PASCAL VOC 2012, COCO-Stuff, and ADE20K.
Recurrent Iterative Gating Networks for Semantic Segmentation
Nov 20, 2018
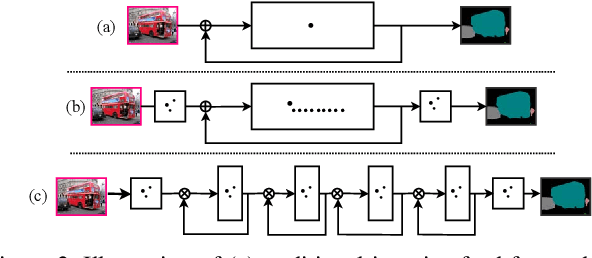


In this paper, we present an approach for Recurrent Iterative Gating called RIGNet. The core elements of RIGNet involve recurrent connections that control the flow of information in neural networks in a top-down manner, and different variants on the core structure are considered. The iterative nature of this mechanism allows for gating to spread in both spatial extent and feature space. This is revealed to be a powerful mechanism with broad compatibility with common existing networks. Analysis shows how gating interacts with different network characteristics, and we also show that more shallow networks with gating may be made to perform better than much deeper networks that do not include RIGNet modules.
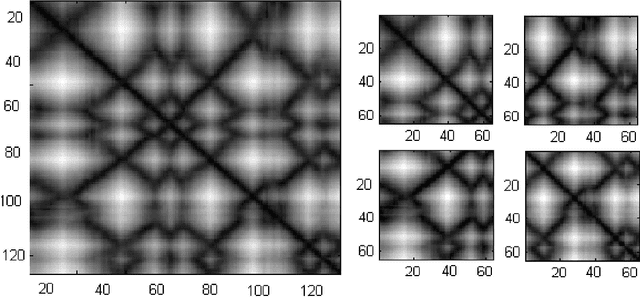
A novel and effective scoring scheme for structure classification and pairwise similarity measurement
Oct 04, 2016
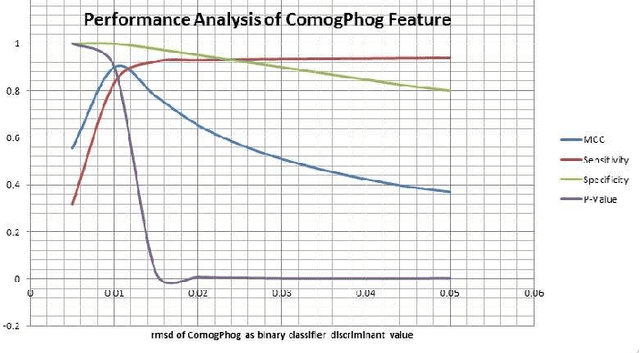
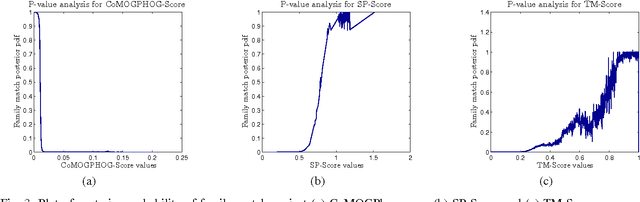
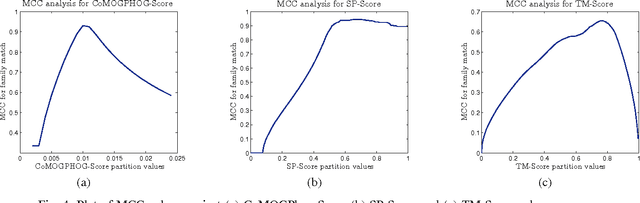
Protein tertiary structure defines its functions, classification and binding sites. Similar structural characteristics between two proteins often lead to the similar characteristics thereof. Determining structural similarity accurately in real time is a crucial research issue. In this paper, we present a novel and effective scoring scheme that is dependent on novel features extracted from protein alpha carbon distance matrices. Our scoring scheme is inspired from pattern recognition and computer vision. Our method is significantly better than the current state of the art methods in terms of family match of pairs of protein structures and other statistical measurements. The effectiveness of our method is tested on standard benchmark structures. A web service is available at http://research.buet.ac.bd:8080/Comograd/score.html where you can get the similarity measurement score between two protein structures based on our method.
CoMOGrad and PHOG: From Computer Vision to Fast and Accurate Protein Tertiary Structure Retrieval
Sep 02, 2014


Due to the advancements in technology number of entries in the structural database of proteins are increasing day by day. Methods for retrieving protein tertiary structures from this large database is the key to comparative analysis of structures which plays an important role to understand proteins and their function. In this paper, we present fast and accurate methods for the retrieval of proteins from a large database with tertiary structures similar to a query protein. Our proposed methods borrow ideas from the field of computer vision. The speed and accuracy of our methods comes from the two newly introduced features, the co-occurrence matrix of the oriented gradient and pyramid histogram of oriented gradient and from the use of Euclidean distance as the distance measure. Experimental results clearly indicate the superiority of our approach in both running time and accuracy. Our method is readily available for use from this website: http://research.buet.ac.bd:8080/Comograd/.