 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepression detection from Social Media Bangla Text Using Recurrent Neural Networks
Dec 08, 2024



Emotion artificial intelligence is a field of study that focuses on figuring out how to recognize emotions, especially in the area of text mining. Today is the age of social media which has opened a door for us to share our individual expressions, emotions, and perspectives on any event. We can analyze sentiment on social media posts to detect positive, negative, or emotional behavior toward society. One of the key challenges in sentiment analysis is to identify depressed text from social media text that is a root cause of mental ill-health. Furthermore, depression leads to severe impairment in day-to-day living and is a major source of suicide incidents. In this paper, we apply natural language processing techniques on Facebook texts for conducting emotion analysis focusing on depression using multiple machine learning algorithms. Preprocessing steps like stemming, stop word removal, etc. are used to clean the collected data, and feature extraction techniques like stylometric feature, TF-IDF, word embedding, etc. are applied to the collected dataset which consists of 983 texts collected from social media posts. In the process of class prediction, LSTM, GRU, support vector machine, and Naive-Bayes classifiers have been used. We have presented the results using the primary classification metrics including F1-score, and accuracy. This work focuses on depression detection from social media posts to help psychologists to analyze sentiment from shared posts which may reduce the undesirable behaviors of depressed individuals through diagnosis and treatment.
Leveraging the Domain Adaptation of Retrieval Augmented Generation Models for Question Answering and Reducing Hallucination
Oct 23, 2024


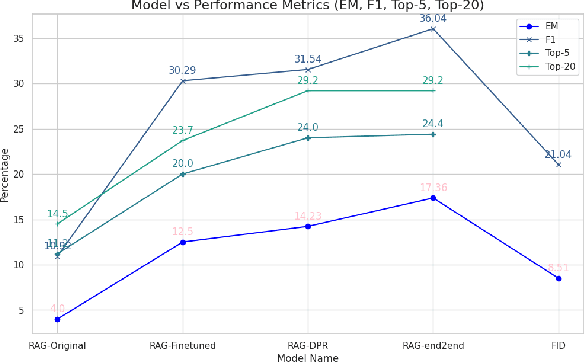
While ongoing advancements in Large Language Models have demonstrated remarkable success across various NLP tasks, Retrieval Augmented Generation Model stands out to be highly effective on downstream applications like Question Answering. Recently, RAG-end2end model further optimized the architecture and achieved notable performance improvements on domain adaptation. However, the effectiveness of these RAG-based architectures remains relatively unexplored when fine-tuned on specialized domains such as customer service for building a reliable conversational AI system. Furthermore, a critical challenge persists in reducing the occurrence of hallucinations while maintaining high domain-specific accuracy. In this paper, we investigated the performance of diverse RAG and RAG-like architectures through domain adaptation and evaluated their ability to generate accurate and relevant response grounded in the contextual knowledge base. To facilitate the evaluation of the models, we constructed a novel dataset HotelConvQA, sourced from wide range of hotel-related conversations and fine-tuned all the models on our domain specific dataset. We also addressed a critical research gap on determining the impact of domain adaptation on reducing hallucinations across different RAG architectures, an aspect that was not properly measured in prior work. Our evaluation shows positive results in all metrics by employing domain adaptation, demonstrating strong performance on QA tasks and providing insights into their efficacy in reducing hallucinations. Our findings clearly indicate that domain adaptation not only enhances the models' performance on QA tasks but also significantly reduces hallucination across all evaluated RAG architectures.
CoMOGrad and PHOG: From Computer Vision to Fast and Accurate Protein Tertiary Structure Retrieval
Sep 02, 2014


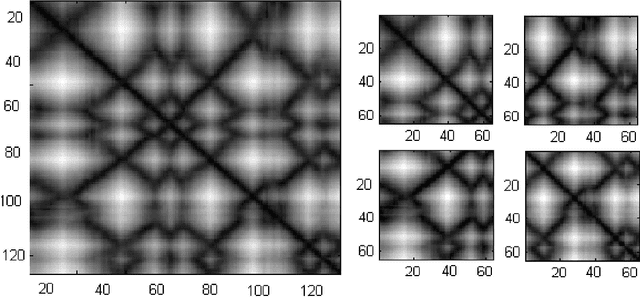
Due to the advancements in technology number of entries in the structural database of proteins are increasing day by day. Methods for retrieving protein tertiary structures from this large database is the key to comparative analysis of structures which plays an important role to understand proteins and their function. In this paper, we present fast and accurate methods for the retrieval of proteins from a large database with tertiary structures similar to a query protein. Our proposed methods borrow ideas from the field of computer vision. The speed and accuracy of our methods comes from the two newly introduced features, the co-occurrence matrix of the oriented gradient and pyramid histogram of oriented gradient and from the use of Euclidean distance as the distance measure. Experimental results clearly indicate the superiority of our approach in both running time and accuracy. Our method is readily available for use from this website: http://research.buet.ac.bd:8080/Comograd/.