 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting and Diagnosing Adversarial Images with Class-Conditional Capsule Reconstructions
Paper and Code
Jul 05, 2019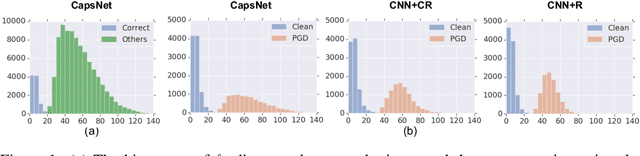
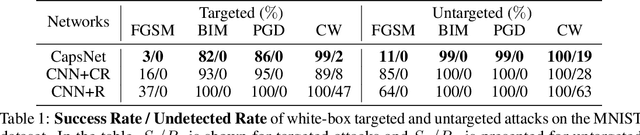
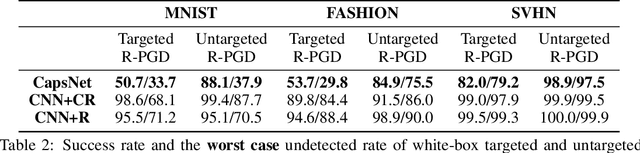

Adversarial examples raise questions about whether neural network models are sensitive to the same visual features as humans. Most of the proposed methods for mitigating adversarial examples have subsequently been defeated by stronger attacks. Motivated by these issues, we take a different approach and propose to instead detect adversarial examples based on class-conditional reconstructions of the input. Our method uses the reconstruction network proposed as part of Capsule Networks (CapsNets), but is general enough to be applied to standard convolutional networks. We find that adversarial or otherwise corrupted images result in much larger reconstruction errors than normal inputs, prompting a simple detection method by thresholding the reconstruction error. Based on these findings, we propose the Reconstructive Attack which seeks both to cause a misclassification and a low reconstruction error. While this attack produces undetected adversarial examples, we find that for CapsNets the resulting perturbations can cause the images to appear visually more like the target class. This suggests that CapsNets utilize features that are more aligned with human perception and address the central issue raised by adversarial examples.