 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDARCCC: Detecting Adversaries by Reconstruction from Class Conditional Capsules
Paper and Code
Nov 16, 2018

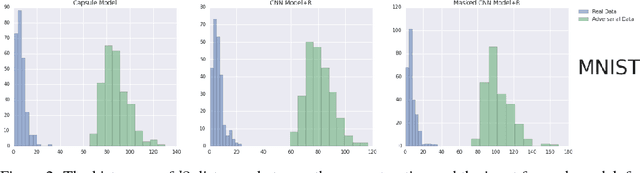
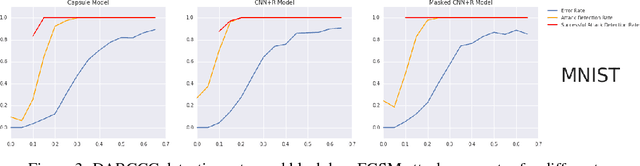
We present a simple technique that allows capsule models to detect adversarial images. In addition to being trained to classify images, the capsule model is trained to reconstruct the images from the pose parameters and identity of the correct top-level capsule. Adversarial images do not look like a typical member of the predicted class and they have much larger reconstruction errors when the reconstruction is produced from the top-level capsule for that class. We show that setting a threshold on the $l2$ distance between the input image and its reconstruction from the winning capsule is very effective at detecting adversarial images for three different datasets. The same technique works quite well for CNNs that have been trained to reconstruct the image from all or part of the last hidden layer before the softmax. We then explore a stronger, white-box attack that takes the reconstruction error into account. This attack is able to fool our detection technique but in order to make the model change its prediction to another class, the attack must typically make the "adversarial" image resemble images of the other class.