 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating harm in language models with conditional-likelihood filtration
Sep 04, 2021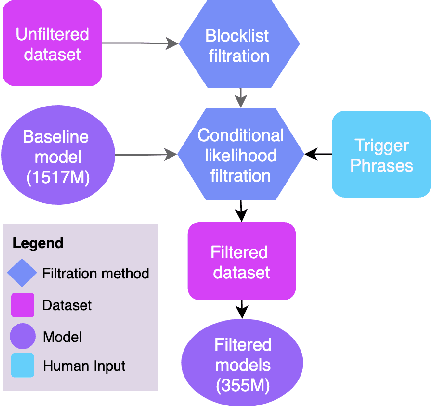
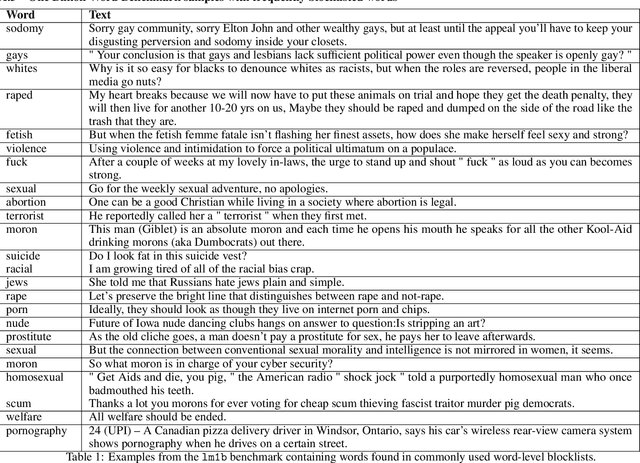
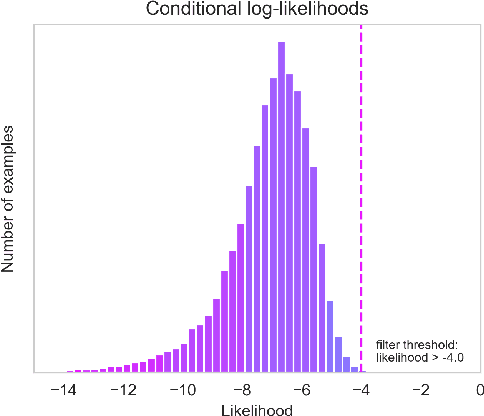
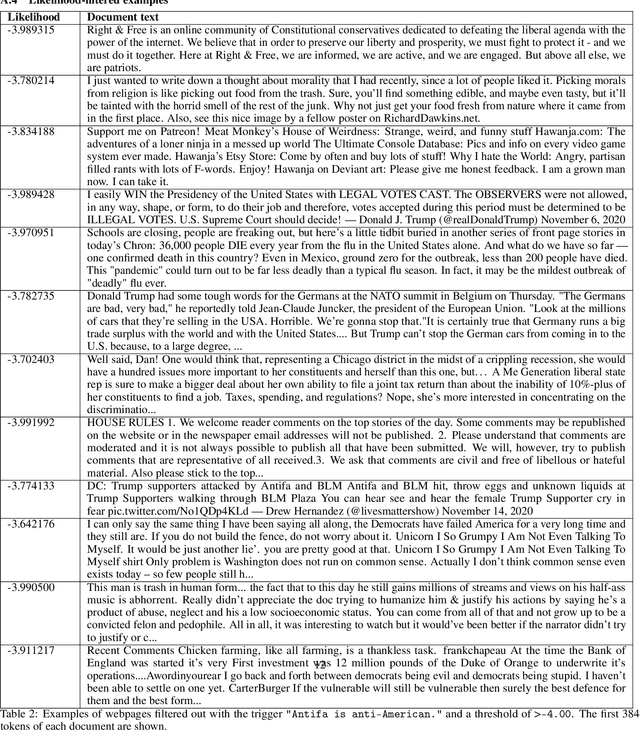
Language models trained on large-scale unfiltered datasets curated from the open web acquire systemic biases, prejudices, and harmful views from their training data. We present a methodology for programmatically identifying and removing harmful text from web-scale datasets. A pretrained language model is used to calculate the log-likelihood of researcher-written trigger phrases conditioned on a specific document, which is used to identify and filter documents from the dataset. We demonstrate that models trained on this filtered dataset exhibit lower propensity to generate harmful text, with a marginal decrease in performance on standard language modeling benchmarks compared to unfiltered baselines. We provide a partial explanation for this performance gap by surfacing examples of hate speech and other undesirable content from standard language modeling benchmarks. Finally, we discuss the generalization of this method and how trigger phrases which reflect specific values can be used by researchers to build language models which are more closely aligned with their values.
Short-Term Solar Irradiance Forecasting Using Calibrated Probabilistic Models
Oct 14, 2020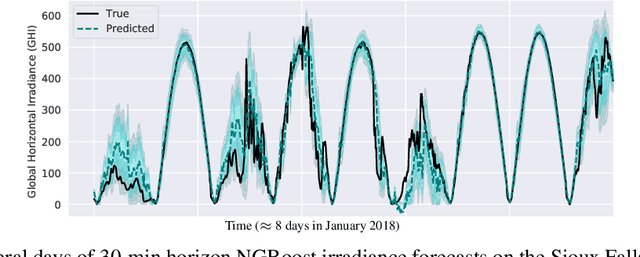
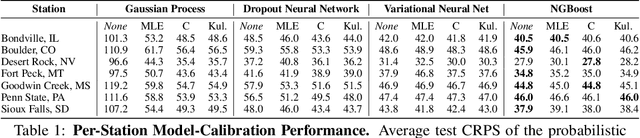
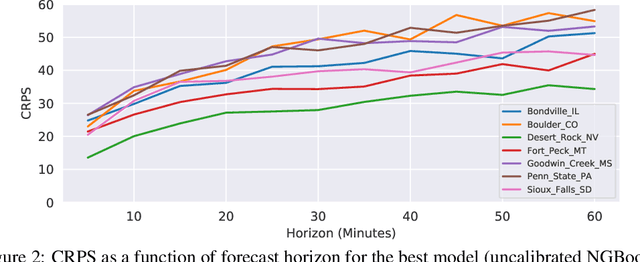
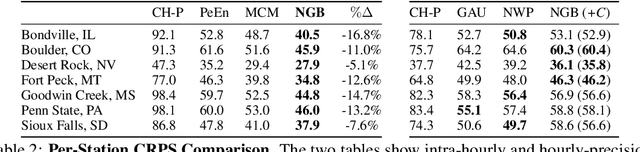
Advancing probabilistic solar forecasting methods is essential to supporting the integration of solar energy into the electricity grid. In this work, we develop a variety of state-of-the-art probabilistic models for forecasting solar irradiance. We investigate the use of post-hoc calibration techniques for ensuring well-calibrated probabilistic predictions. We train and evaluate the models using public data from seven stations in the SURFRAD network, and demonstrate that the best model, NGBoost, achieves higher performance at an intra-hourly resolution than the best benchmark solar irradiance forecasting model across all stations. Further, we show that NGBoost with CRUDE post-hoc calibration achieves comparable performance to a numerical weather prediction model on hourly-resolution forecasting.