 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEDS-Bench: Behavior of EHR-models under Distributional Shift--A Benchmark
Jul 17, 2021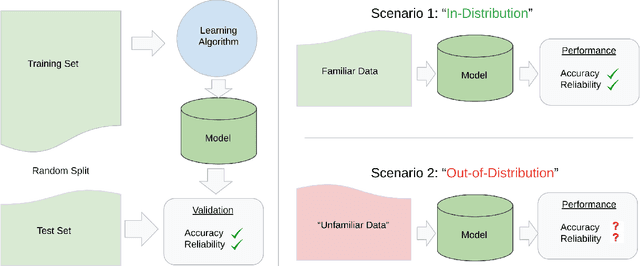
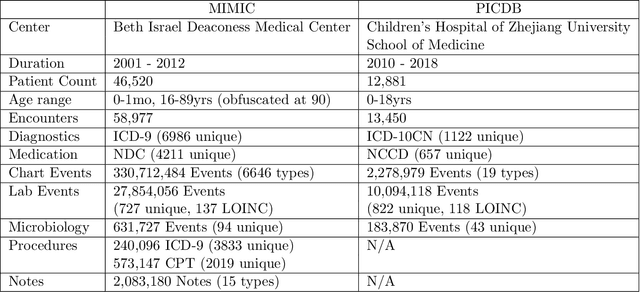
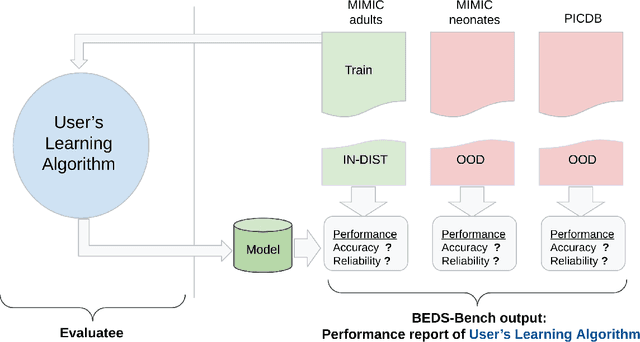
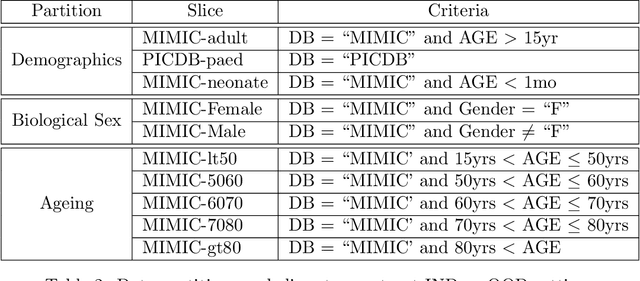
Machine learning has recently demonstrated impressive progress in predictive accuracy across a wide array of tasks. Most ML approaches focus on generalization performance on unseen data that are similar to the training data (In-Distribution, or IND). However, real world applications and deployments of ML rarely enjoy the comfort of encountering examples that are always IND. In such situations, most ML models commonly display erratic behavior on Out-of-Distribution (OOD) examples, such as assigning high confidence to wrong predictions, or vice-versa. Implications of such unusual model behavior are further exacerbated in the healthcare setting, where patient health can potentially be put at risk. It is crucial to study the behavior and robustness properties of models under distributional shift, understand common failure modes, and take mitigation steps before the model is deployed. Having a benchmark that shines light upon these aspects of a model is a first and necessary step in addressing the issue. Recent work and interest in increasing model robustness in OOD settings have focused more on image modality, while the Electronic Health Record (EHR) modality is still largely under-explored. We aim to bridge this gap by releasing BEDS-Bench, a benchmark for quantifying the behavior of ML models over EHR data under OOD settings. We use two open access, de-identified EHR datasets to construct several OOD data settings to run tests on, and measure relevant metrics that characterize crucial aspects of a model's OOD behavior. We evaluate several learning algorithms under BEDS-Bench and find that all of them show poor generalization performance under distributional shift in general. Our results highlight the need and the potential to improve robustness of EHR models under distributional shift, and BEDS-Bench provides one way to measure progress towards that goal.
Short-Term Solar Irradiance Forecasting Using Calibrated Probabilistic Models
Oct 14, 2020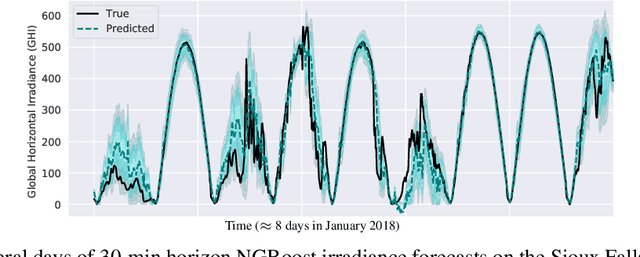
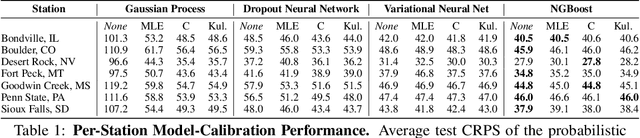
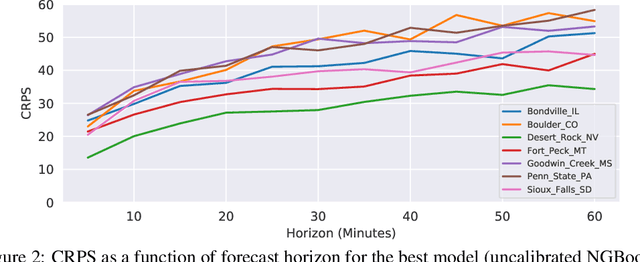
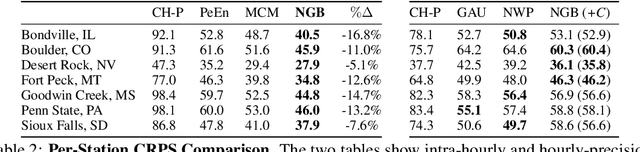
Advancing probabilistic solar forecasting methods is essential to supporting the integration of solar energy into the electricity grid. In this work, we develop a variety of state-of-the-art probabilistic models for forecasting solar irradiance. We investigate the use of post-hoc calibration techniques for ensuring well-calibrated probabilistic predictions. We train and evaluate the models using public data from seven stations in the SURFRAD network, and demonstrate that the best model, NGBoost, achieves higher performance at an intra-hourly resolution than the best benchmark solar irradiance forecasting model across all stations. Further, we show that NGBoost with CRUDE post-hoc calibration achieves comparable performance to a numerical weather prediction model on hourly-resolution forecasting.
CRUDE: Calibrating Regression Uncertainty Distributions Empirically
Jun 23, 2020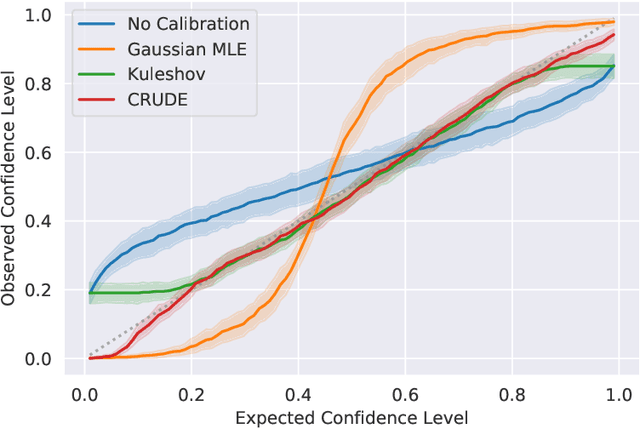
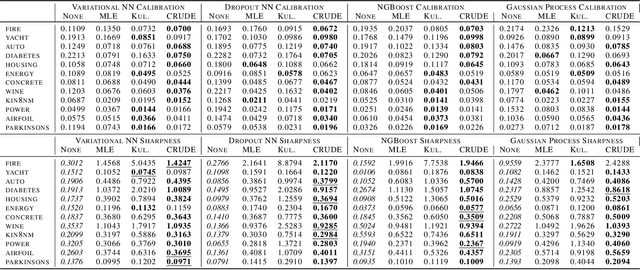
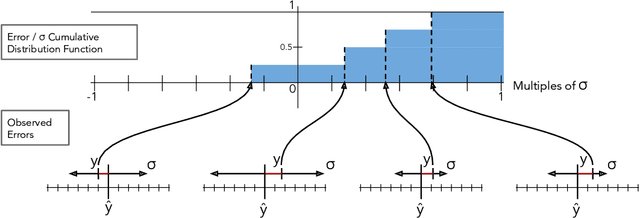
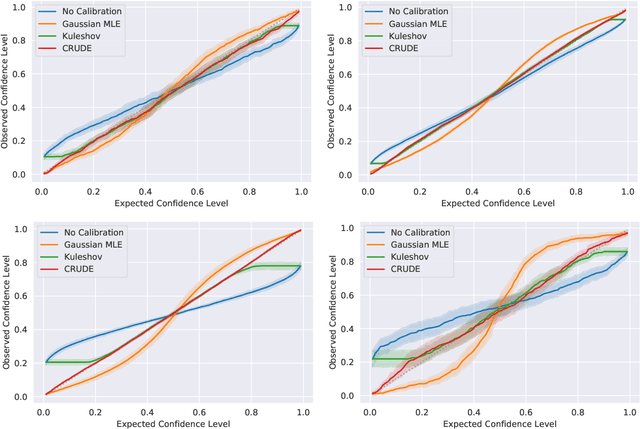
The importance of calibrated uncertainty estimates in machine learning is growing apparent across many fields such as autonomous vehicles, medicine, and weather and climate forecasting. While there is extensive literature on uncertainty calibration for classification, the classification findings do not always translate to regression. As a result, modern models for predicting uncertainty in regression settings typically produce uncalibrated and overconfident estimates. To address these gaps, we present a calibration method for regression settings that does not assume a particular uncertainty distribution over the error: Calibrating Regression Uncertainty Distributions Empirically (CRUDE). CRUDE makes the weaker assumption that error distributions have a constant arbitrary shape across the output space, shifted by predicted mean and scaled by predicted standard deviation. CRUDE requires no training of the calibration estimator, aside from a parameter to account for fixed bias in the predicted mean. Across an extensive set of regression tasks, CRUDE demonstrates consistently sharper, better calibrated, and more accurate uncertainty estimates than state-of-the-art techniques.
NGBoost: Natural Gradient Boosting for Probabilistic Prediction
Oct 09, 2019



We present Natural Gradient Boosting (NGBoost), an algorithm which brings probabilistic prediction capability to gradient boosting in a generic way. Predictive uncertainty estimation is crucial in many applications such as healthcare and weather forecasting. Probabilistic prediction, which is the approach where the model outputs a full probability distribution over the entire outcome space, is a natural way to quantify those uncertainties. Gradient Boosting Machines have been widely successful in prediction tasks on structured input data, but a simple boosting solution for probabilistic prediction of real valued outputs is yet to be made. NGBoost is a gradient boosting approach which uses the \emph{Natural Gradient} to address technical challenges that makes generic probabilistic prediction hard with existing gradient boosting methods. Our approach is modular with respect to the choice of base learner, probability distribution, and scoring rule. We show empirically on several regression datasets that NGBoost provides competitive predictive performance of both uncertainty estimates and traditional metrics.
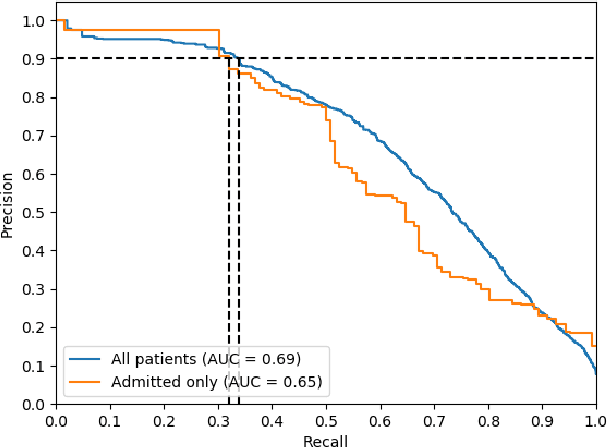
Predicting Inpatient Discharge Prioritization With Electronic Health Records
Dec 02, 2018
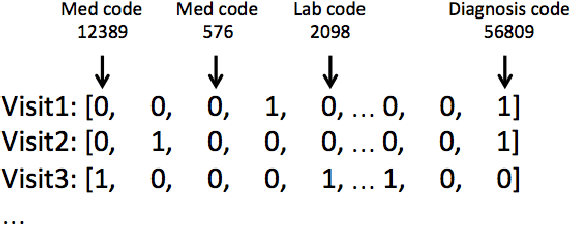


Identifying patients who will be discharged within 24 hours can improve hospital resource management and quality of care. We studied this problem using eight years of Electronic Health Records (EHR) data from Stanford Hospital. We fit models to predict 24 hour discharge across the entire inpatient population. The best performing models achieved an area under the receiver-operator characteristic curve (AUROC) of 0.85 and an AUPRC of 0.53 on a held out test set. This model was also well calibrated. Finally, we analyzed the utility of this model in a decision theoretic framework to identify regions of ROC space in which using the model increases expected utility compared to the trivial always negative or always positive classifiers.
Countdown Regression: Sharp and Calibrated Survival Predictions
Jun 21, 2018



Personalized probabilistic forecasts of time to event (such as mortality) can be crucial in decision making, especially in the clinical setting. Inspired by ideas from the meteorology literature, we approach this problem through the paradigm of maximizing sharpness of prediction distributions, subject to calibration. In regression problems, it has been shown that optimizing the continuous ranked probability score (CRPS) instead of maximum likelihood leads to sharper prediction distributions while maintaining calibration. We introduce the Survival-CRPS, a generalization of the CRPS to the time to event setting, and present right-censored and interval-censored variants. To holistically evaluate the quality of predicted distributions over time to event, we present the Survival-AUPRC evaluation metric, an analog to area under the precision-recall curve. We apply these ideas by building a recurrent neural network for mortality prediction, using an Electronic Health Record dataset covering millions of patients. We demonstrate significant benefits in models trained by the Survival-CRPS objective instead of maximum likelihood.
Improving Palliative Care with Deep Learning
Nov 17, 2017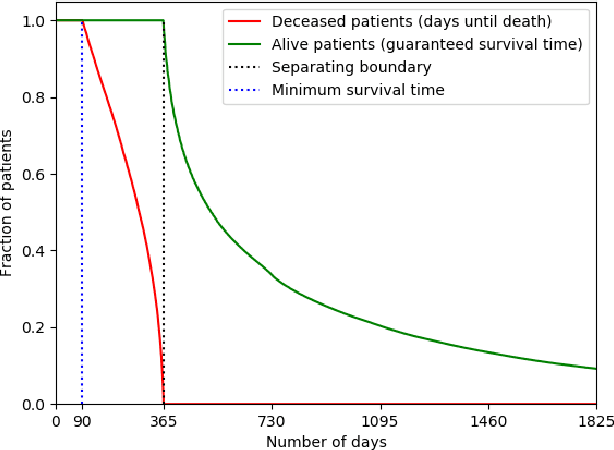
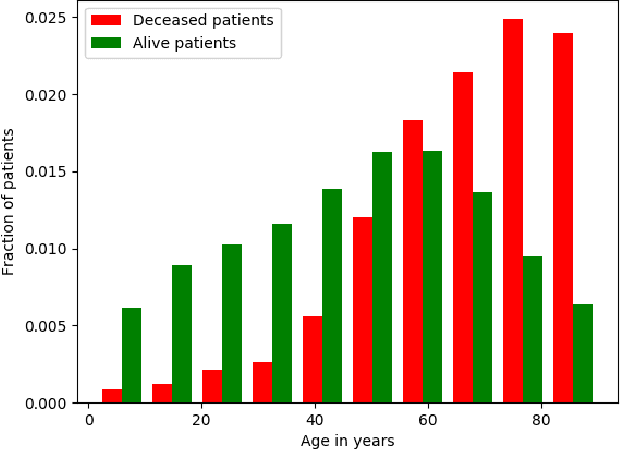
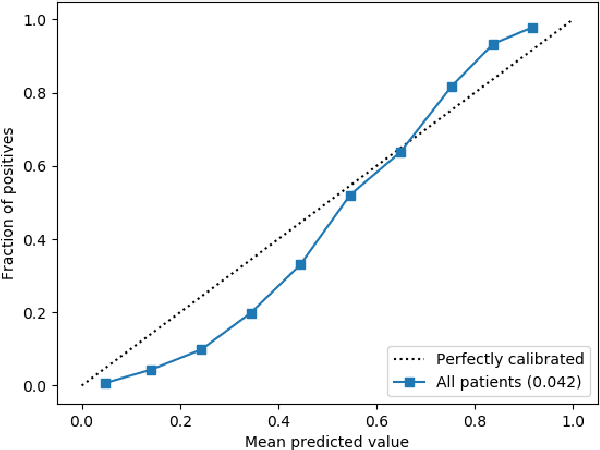
Improving the quality of end-of-life care for hospitalized patients is a priority for healthcare organizations. Studies have shown that physicians tend to over-estimate prognoses, which in combination with treatment inertia results in a mismatch between patients wishes and actual care at the end of life. We describe a method to address this problem using Deep Learning and Electronic Health Record (EHR) data, which is currently being piloted, with Institutional Review Board approval, at an academic medical center. The EHR data of admitted patients are automatically evaluated by an algorithm, which brings patients who are likely to benefit from palliative care services to the attention of the Palliative Care team. The algorithm is a Deep Neural Network trained on the EHR data from previous years, to predict all-cause 3-12 month mortality of patients as a proxy for patients that could benefit from palliative care. Our predictions enable the Palliative Care team to take a proactive approach in reaching out to such patients, rather than relying on referrals from treating physicians, or conduct time consuming chart reviews of all patients. We also present a novel interpretation technique which we use to provide explanations of the model's predictions.
Neural Language Correction with Character-Based Attention
Mar 31, 2016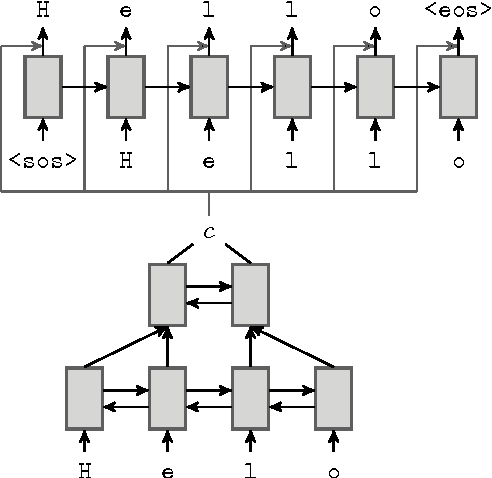


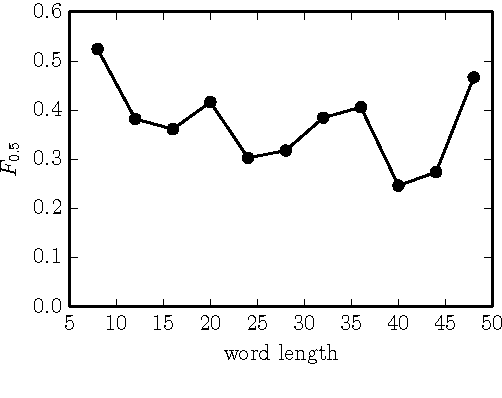
Natural language correction has the potential to help language learners improve their writing skills. While approaches with separate classifiers for different error types have high precision, they do not flexibly handle errors such as redundancy or non-idiomatic phrasing. On the other hand, word and phrase-based machine translation methods are not designed to cope with orthographic errors, and have recently been outpaced by neural models. Motivated by these issues, we present a neural network-based approach to language correction. The core component of our method is an encoder-decoder recurrent neural network with an attention mechanism. By operating at the character level, the network avoids the problem of out-of-vocabulary words. We illustrate the flexibility of our approach on dataset of noisy, user-generated text collected from an English learner forum. When combined with a language model, our method achieves a state-of-the-art $F_{0.5}$-score on the CoNLL 2014 Shared Task. We further demonstrate that training the network on additional data with synthesized errors can improve performance.