 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Language Correction with Character-Based Attention
Paper and Code
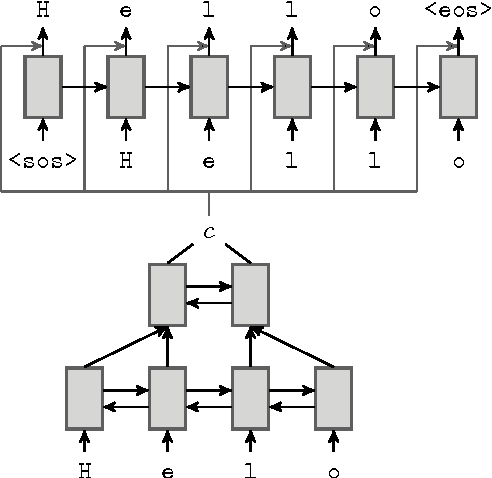


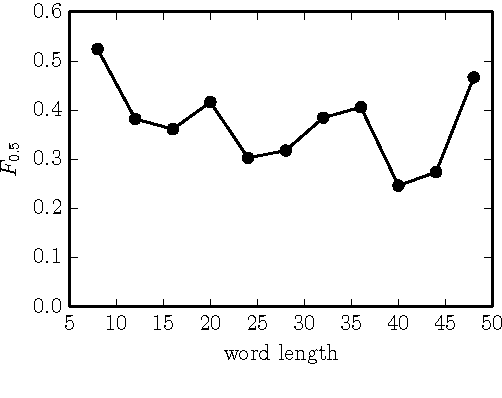
Natural language correction has the potential to help language learners improve their writing skills. While approaches with separate classifiers for different error types have high precision, they do not flexibly handle errors such as redundancy or non-idiomatic phrasing. On the other hand, word and phrase-based machine translation methods are not designed to cope with orthographic errors, and have recently been outpaced by neural models. Motivated by these issues, we present a neural network-based approach to language correction. The core component of our method is an encoder-decoder recurrent neural network with an attention mechanism. By operating at the character level, the network avoids the problem of out-of-vocabulary words. We illustrate the flexibility of our approach on dataset of noisy, user-generated text collected from an English learner forum. When combined with a language model, our method achieves a state-of-the-art $F_{0.5}$-score on the CoNLL 2014 Shared Task. We further demonstrate that training the network on additional data with synthesized errors can improve performance.