 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Document-Level Translation Enables Zero-Shot Transfer From Sentences to Documents
Sep 21, 2021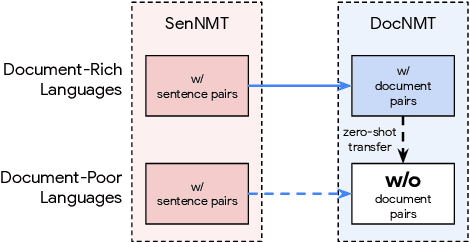

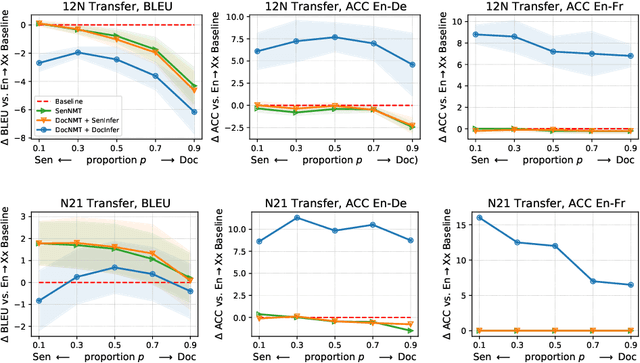
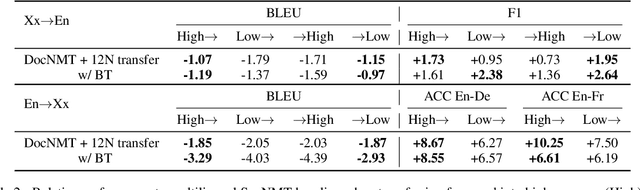
Document-level neural machine translation (DocNMT) delivers coherent translations by incorporating cross-sentence context. However, for most language pairs there's a shortage of parallel documents, although parallel sentences are readily available. In this paper, we study whether and how contextual modeling in DocNMT is transferable from sentences to documents in a zero-shot fashion (i.e. no parallel documents for student languages) through multilingual modeling. Using simple concatenation-based DocNMT, we explore the effect of 3 factors on multilingual transfer: the number of document-supervised teacher languages, the data schedule for parallel documents at training, and the data condition of parallel documents (genuine vs. backtranslated). Our experiments on Europarl-7 and IWSLT-10 datasets show the feasibility of multilingual transfer for DocNMT, particularly on document-specific metrics. We observe that more teacher languages and adequate data schedule both contribute to better transfer quality. Surprisingly, the transfer is less sensitive to the data condition and multilingual DocNMT achieves comparable performance with both back-translated and genuine document pairs.
Sentence Boundary Augmentation For Neural Machine Translation Robustness
Oct 21, 2020
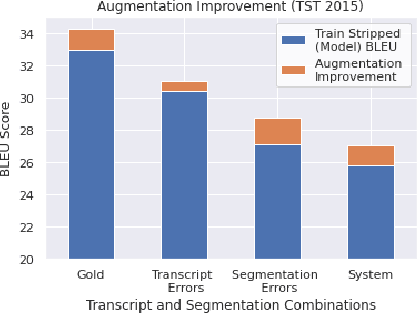

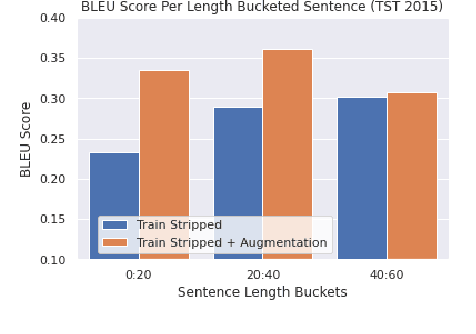
Neural Machine Translation (NMT) models have demonstrated strong state of the art performance on translation tasks where well-formed training and evaluation data are provided, but they remain sensitive to inputs that include errors of various types. Specifically, in the context of long-form speech translation systems, where the input transcripts come from Automatic Speech Recognition (ASR), the NMT models have to handle errors including phoneme substitutions, grammatical structure, and sentence boundaries, all of which pose challenges to NMT robustness. Through in-depth error analysis, we show that sentence boundary segmentation has the largest impact on quality, and we develop a simple data augmentation strategy to improve segmentation robustness.
Language-agnostic BERT Sentence Embedding
Jul 03, 2020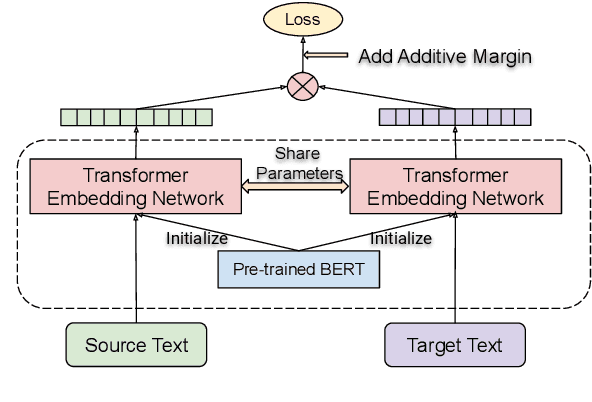
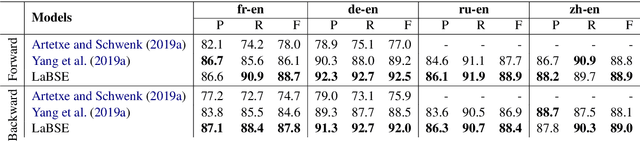
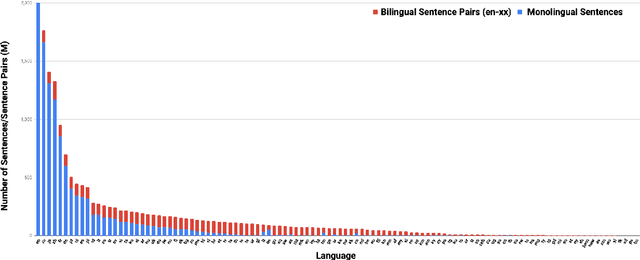
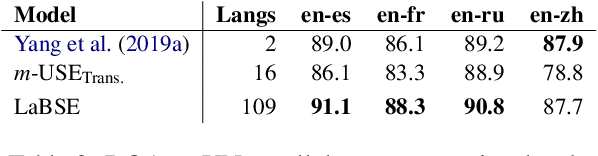
We adapt multilingual BERT to produce language-agnostic sentence embeddings for 109 languages. %The state-of-the-art for numerous monolingual and multilingual NLP tasks is masked language model (MLM) pretraining followed by task specific fine-tuning. While English sentence embeddings have been obtained by fine-tuning a pretrained BERT model, such models have not been applied to multilingual sentence embeddings. Our model combines masked language model (MLM) and translation language model (TLM) pretraining with a translation ranking task using bi-directional dual encoders. The resulting multilingual sentence embeddings improve average bi-text retrieval accuracy over 112 languages to 83.7%, well above the 65.5% achieved by the prior state-of-the-art on Tatoeba. Our sentence embeddings also establish new state-of-the-art results on BUCC and UN bi-text retrieval.
Leveraging Monolingual Data with Self-Supervision for Multilingual Neural Machine Translation
May 11, 2020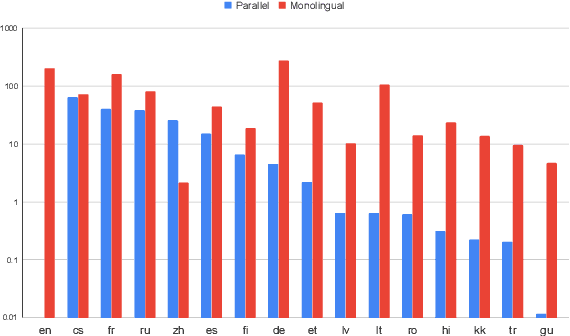

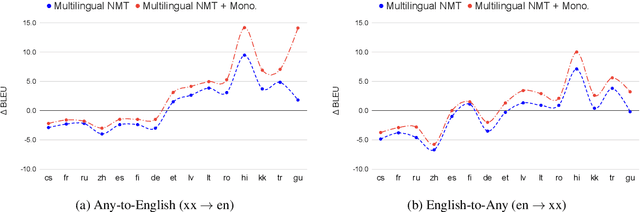
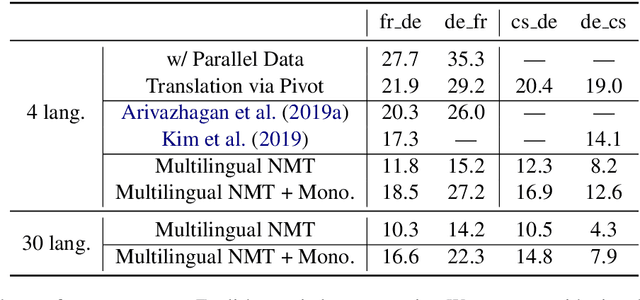
Over the last few years two promising research directions in low-resource neural machine translation (NMT) have emerged. The first focuses on utilizing high-resource languages to improve the quality of low-resource languages via multilingual NMT. The second direction employs monolingual data with self-supervision to pre-train translation models, followed by fine-tuning on small amounts of supervised data. In this work, we join these two lines of research and demonstrate the efficacy of monolingual data with self-supervision in multilingual NMT. We offer three major results: (i) Using monolingual data significantly boosts the translation quality of low-resource languages in multilingual models. (ii) Self-supervision improves zero-shot translation quality in multilingual models. (iii) Leveraging monolingual data with self-supervision provides a viable path towards adding new languages to multilingual models, getting up to 33 BLEU on ro-en translation without any parallel data or back-translation.
Re-translation versus Streaming for Simultaneous Translation
Apr 14, 2020
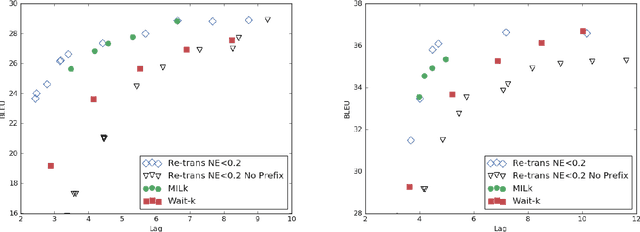

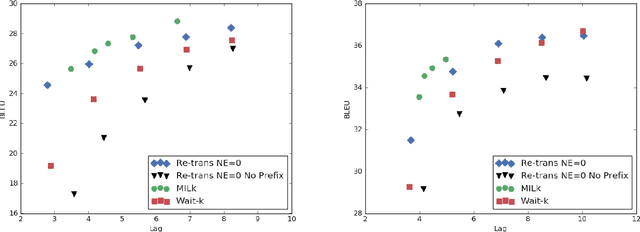
There has been great progress in improving streaming machine translation, a simultaneous paradigm where the system appends to a growing hypothesis as more source content becomes available. We study a related problem in which revisions to the hypothesis beyond strictly appending words are permitted. This is suitable for applications such as live captioning an audio feed. In this setting, we compare custom streaming approaches to re-translation, a straightforward strategy where each new source token triggers a distinct translation from scratch. We find re-translation to be as good or better than state-of-the-art streaming systems, even when operating under constraints that allow very few revisions. We attribute much of this success to a previously proposed data-augmentation technique that adds prefix-pairs to the training data, which alongside wait-k inference forms a strong baseline for streaming translation. We also highlight re-translation's ability to wrap arbitrarily powerful MT systems with an experiment showing large improvements from an upgrade to its base model.
Controlling Computation versus Quality for Neural Sequence Models
Feb 17, 2020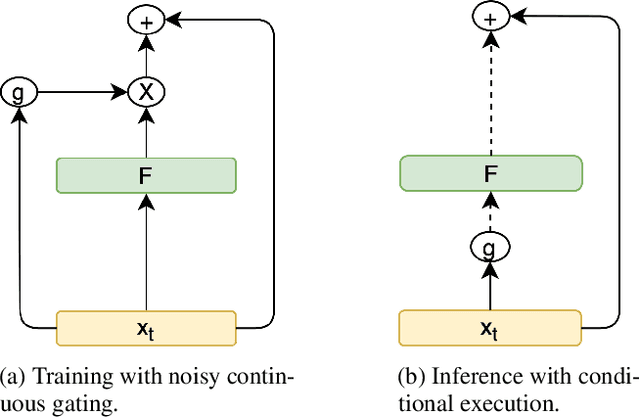
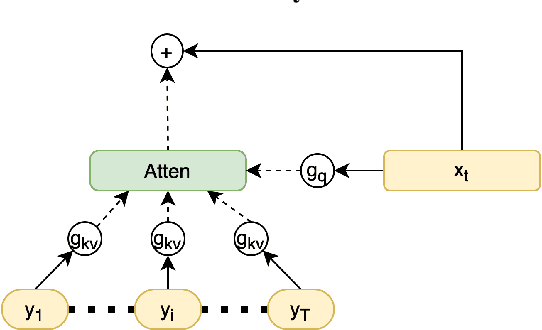
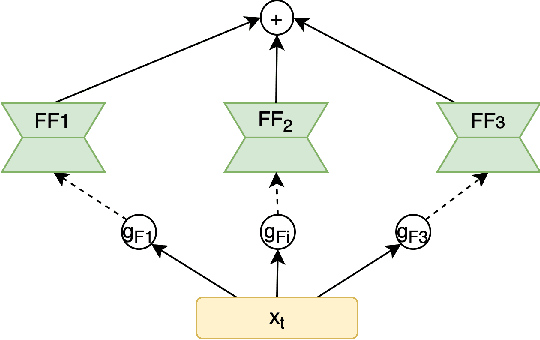
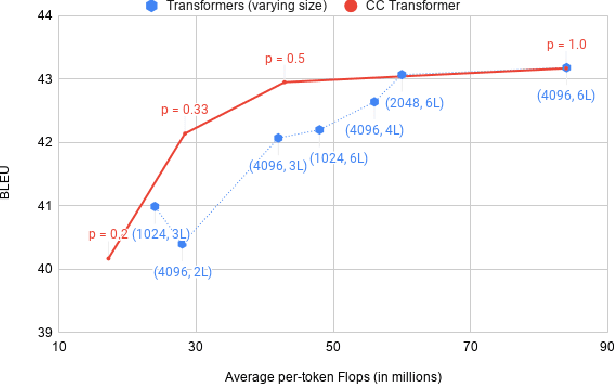
Most neural networks utilize the same amount of compute for every example independent of the inherent complexity of the input. Further, methods that adapt the amount of computation to the example focus on finding a fixed inference-time computational graph per example, ignoring any external computational budgets or varying inference time limitations. In this work, we utilize conditional computation to make neural sequence models (Transformer) more efficient and computation-aware during inference. We first modify the Transformer architecture, making each set of operations conditionally executable depending on the output of a learned control network. We then train this model in a multi-task setting, where each task corresponds to a particular computation budget. This allows us to train a single model that can be controlled to operate on different points of the computation-quality trade-off curve, depending on the available computation budget at inference time. We evaluate our approach on two tasks: (i) WMT English-French Translation and (ii) Unsupervised representation learning (BERT). Our experiments demonstrate that the proposed Conditional Computation Transformer (CCT) is competitive with vanilla Transformers when allowed to utilize its full computational budget, while improving significantly over computationally equivalent baselines when operating on smaller computational budgets.
Re-Translation Strategies For Long Form, Simultaneous, Spoken Language Translation
Dec 06, 2019
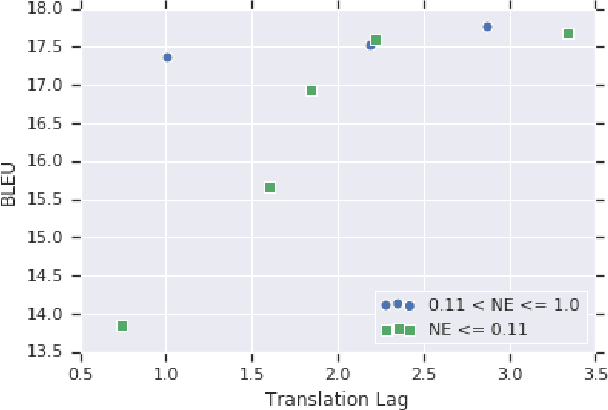
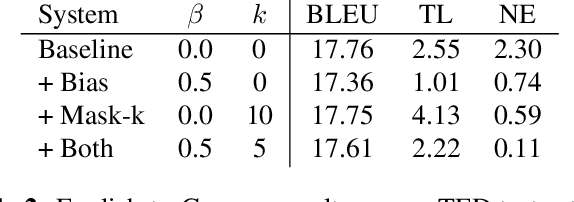
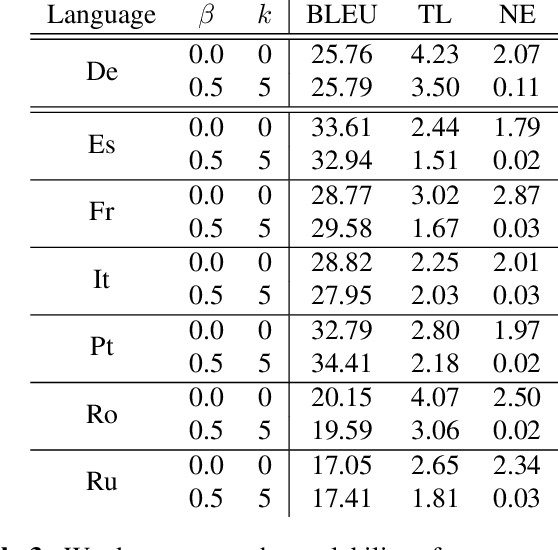
We investigate the problem of simultaneous machine translation of long-form speech content. We target a continuous speech-to-text scenario, generating translated captions for a live audio feed, such as a lecture or play-by-play commentary. As this scenario allows for revisions to our incremental translations, we adopt a re-translation approach to simultaneous translation, where the source is repeatedly translated from scratch as it grows. This approach naturally exhibits very low latency and high final quality, but at the cost of incremental instability as the output is continuously refined. We experiment with a pipeline of industry-grade speech recognition and translation tools, augmented with simple inference heuristics to improve stability. We use TED Talks as a source of multilingual test data, developing our techniques on English-to-German spoken language translation. Our minimalist approach to simultaneous translation allows us to easily scale our final evaluation to six more target languages, dramatically improving incremental stability for all of them.
Simple, Scalable Adaptation for Neural Machine Translation
Sep 18, 2019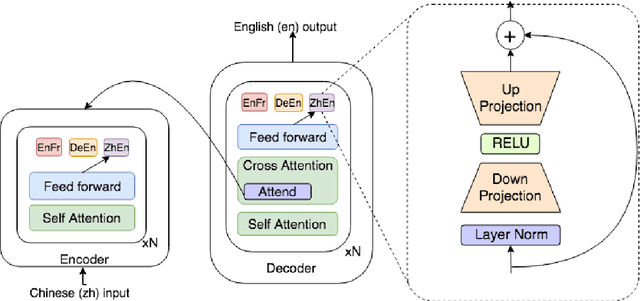
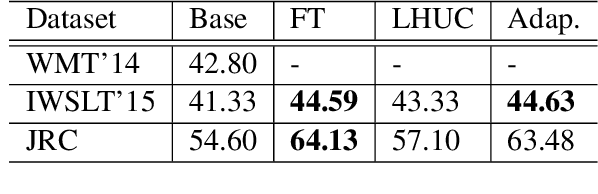
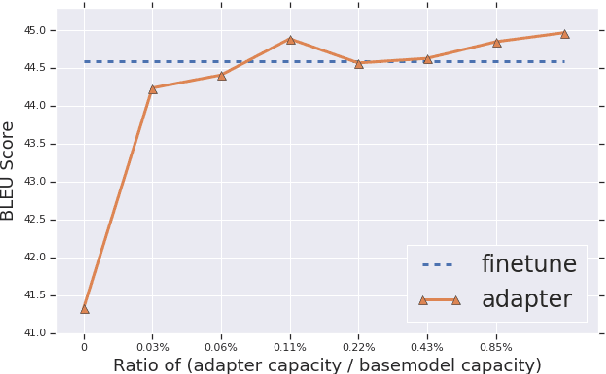
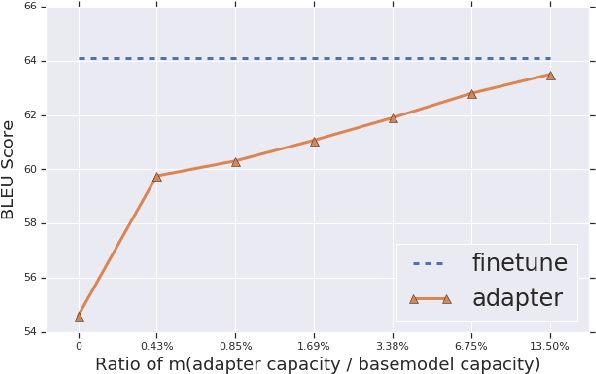
Fine-tuning pre-trained Neural Machine Translation (NMT) models is the dominant approach for adapting to new languages and domains. However, fine-tuning requires adapting and maintaining a separate model for each target task. We propose a simple yet efficient approach for adaptation in NMT. Our proposed approach consists of injecting tiny task specific adapter layers into a pre-trained model. These lightweight adapters, with just a small fraction of the original model size, adapt the model to multiple individual tasks simultaneously. We evaluate our approach on two tasks: (i) Domain Adaptation and (ii) Massively Multilingual NMT. Experiments on domain adaptation demonstrate that our proposed approach is on par with full fine-tuning on various domains, dataset sizes and model capacities. On a massively multilingual dataset of 103 languages, our adaptation approach bridges the gap between individual bilingual models and one massively multilingual model for most language pairs, paving the way towards universal machine translation.
Investigating Multilingual NMT Representations at Scale
Sep 11, 2019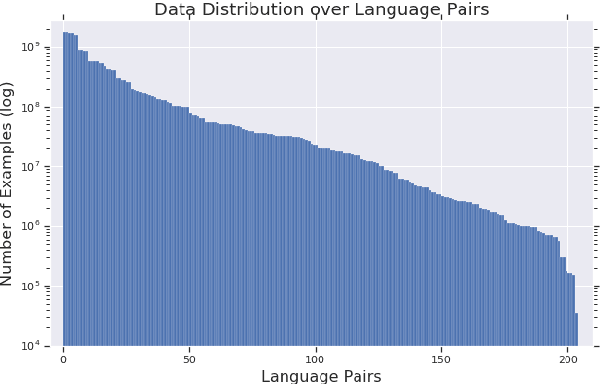
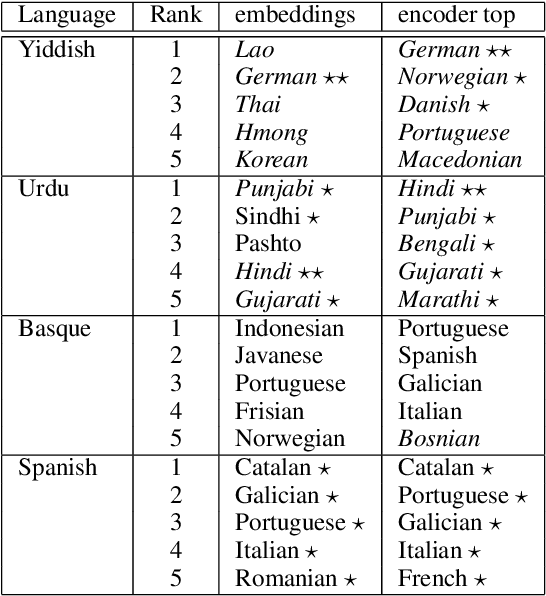
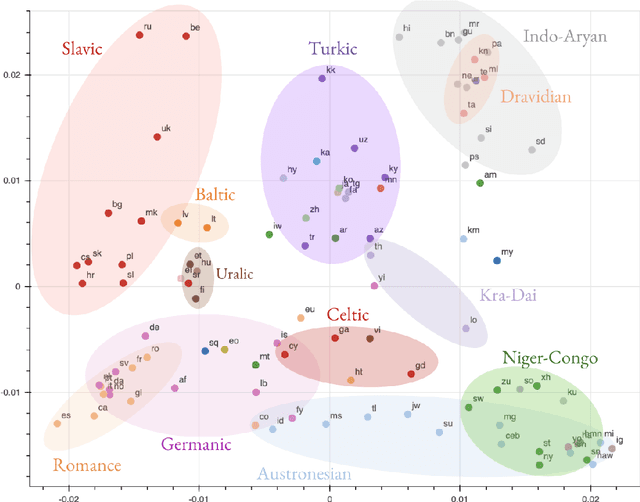

Multilingual Neural Machine Translation (NMT) models have yielded large empirical success in transfer learning settings. However, these black-box representations are poorly understood, and their mode of transfer remains elusive. In this work, we attempt to understand massively multilingual NMT representations (with 103 languages) using Singular Value Canonical Correlation Analysis (SVCCA), a representation similarity framework that allows us to compare representations across different languages, layers and models. Our analysis validates several empirical results and long-standing intuitions, and unveils new observations regarding how representations evolve in a multilingual translation model. We draw three major conclusions from our analysis, with implications on cross-lingual transfer learning: (i) Encoder representations of different languages cluster based on linguistic similarity, (ii) Representations of a source language learned by the encoder are dependent on the target language, and vice-versa, and (iii) Representations of high resource and/or linguistically similar languages are more robust when fine-tuning on an arbitrary language pair, which is critical to determining how much cross-lingual transfer can be expected in a zero or few-shot setting. We further connect our findings with existing empirical observations in multilingual NMT and transfer learning.
Evaluating the Cross-Lingual Effectiveness of Massively Multilingual Neural Machine Translation
Sep 01, 2019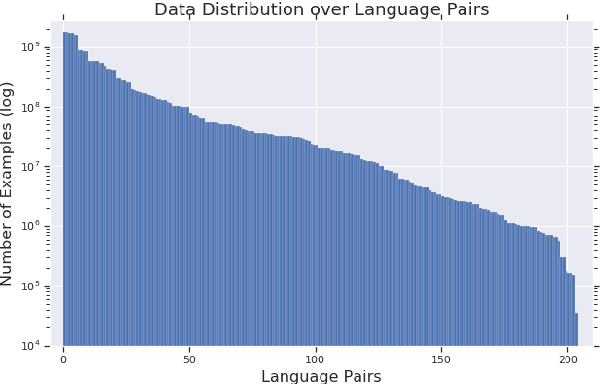
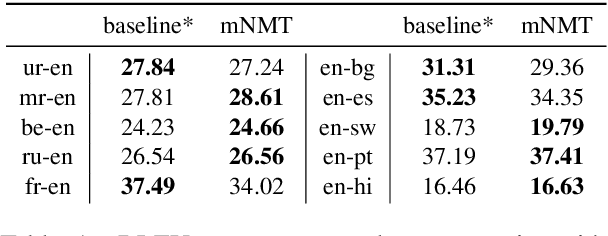
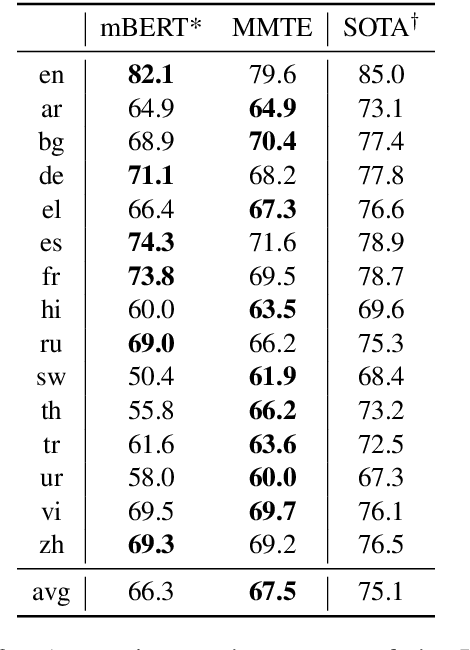
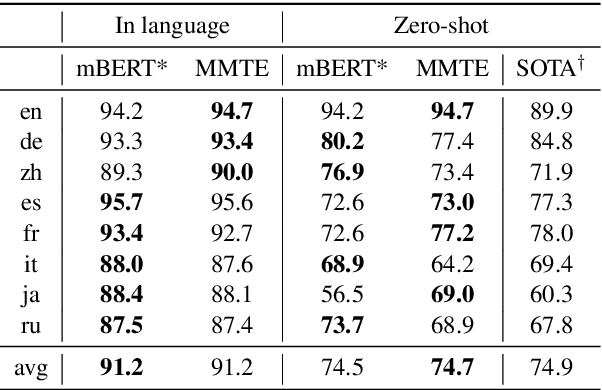
The recently proposed massively multilingual neural machine translation (NMT) system has been shown to be capable of translating over 100 languages to and from English within a single model. Its improved translation performance on low resource languages hints at potential cross-lingual transfer capability for downstream tasks. In this paper, we evaluate the cross-lingual effectiveness of representations from the encoder of a massively multilingual NMT model on 5 downstream classification and sequence labeling tasks covering a diverse set of over 50 languages. We compare against a strong baseline, multilingual BERT (mBERT), in different cross-lingual transfer learning scenarios and show gains in zero-shot transfer in 4 out of these 5 tasks.