 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Replicable Human Evaluations via Stable Ranking Probability
Apr 01, 2024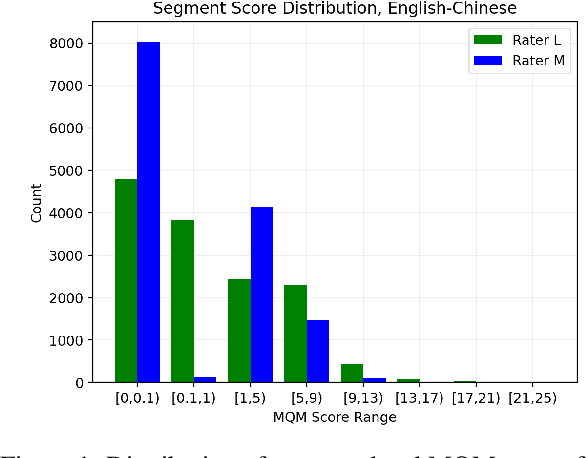


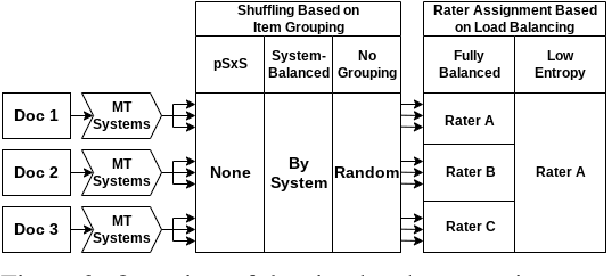
Reliable human evaluation is critical to the development of successful natural language generation models, but achieving it is notoriously difficult. Stability is a crucial requirement when ranking systems by quality: consistent ranking of systems across repeated evaluations is not just desirable, but essential. Without it, there is no reliable foundation for hill-climbing or product launch decisions. In this paper, we use machine translation and its state-of-the-art human evaluation framework, MQM, as a case study to understand how to set up reliable human evaluations that yield stable conclusions. We investigate the optimal configurations for item allocation to raters, number of ratings per item, and score normalization. Our study on two language pairs provides concrete recommendations for designing replicable human evaluation studies. We also collect and release the largest publicly available dataset of multi-segment translations rated by multiple professional translators, consisting of nearly 140,000 segment annotations across two language pairs.
Importance-Aware Data Augmentation for Document-Level Neural Machine Translation
Jan 27, 2024


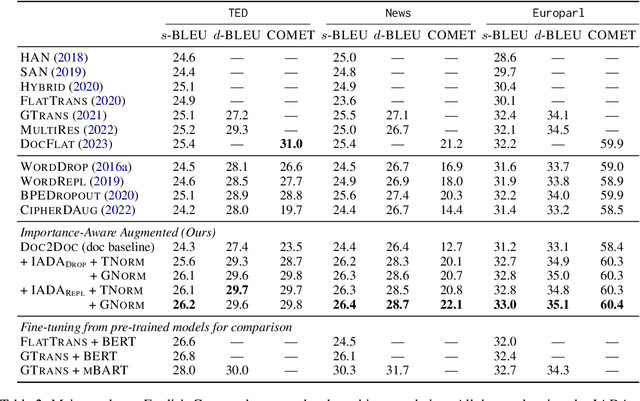
Document-level neural machine translation (DocNMT) aims to generate translations that are both coherent and cohesive, in contrast to its sentence-level counterpart. However, due to its longer input length and limited availability of training data, DocNMT often faces the challenge of data sparsity. To overcome this issue, we propose a novel Importance-Aware Data Augmentation (IADA) algorithm for DocNMT that augments the training data based on token importance information estimated by the norm of hidden states and training gradients. We conduct comprehensive experiments on three widely-used DocNMT benchmarks. Our empirical results show that our proposed IADA outperforms strong DocNMT baselines as well as several data augmentation approaches, with statistical significance on both sentence-level and document-level BLEU.
Adapting Large Language Models for Document-Level Machine Translation
Jan 12, 2024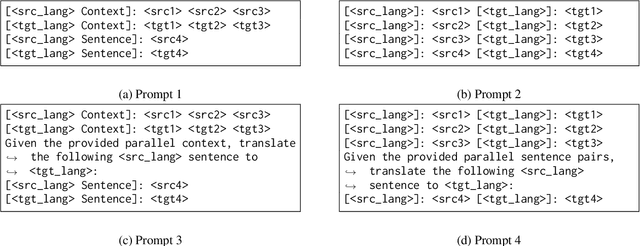
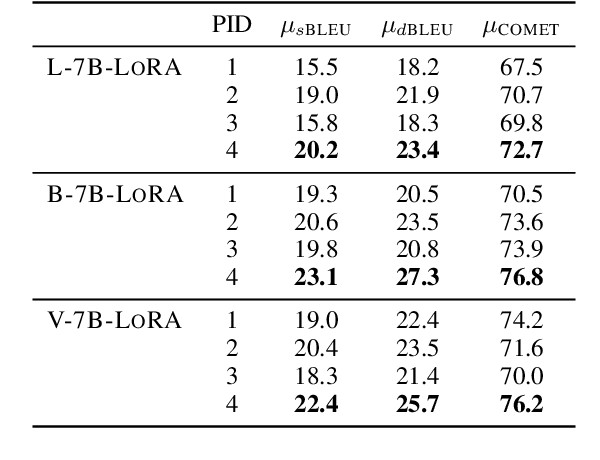
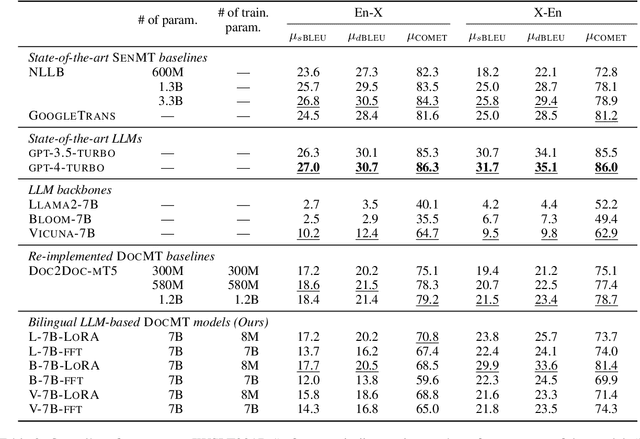
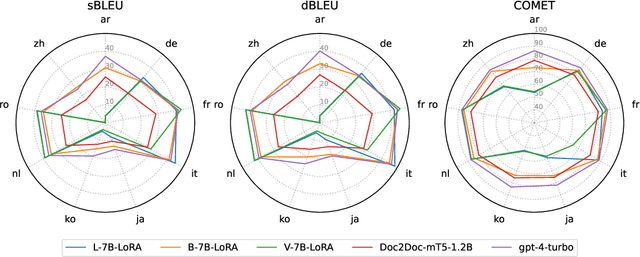
Large language models (LLMs) have made significant strides in various natural language processing (NLP) tasks. Recent research shows that the moderately-sized LLMs often outperform their larger counterparts after task-specific fine-tuning. In this work, we delve into the process of adapting LLMs to specialize in document-level machine translation (DocMT) for a specific language pair. Firstly, we explore how prompt strategies affect downstream translation performance. Then, we conduct extensive experiments with two fine-tuning methods, three LLM backbones, and 18 translation tasks across nine language pairs. Our findings indicate that in some cases, these specialized models even surpass GPT-4 in translation performance, while they still significantly suffer from the off-target translation issue in others, even if they are exclusively fine-tuned on bilingual parallel documents. Furthermore, we provide an in-depth analysis of these LLMs tailored for DocMT, exploring aspects such as translation errors, the scaling law of parallel documents, out-of-domain generalization, and the impact of zero-shot crosslingual transfer. The findings of this research not only shed light on the strengths and limitations of LLM-based DocMT models but also provide a foundation for future research in DocMT.
To Diverge or Not to Diverge: A Morphosyntactic Perspective on Machine Translation vs Human Translation
Jan 02, 2024We conduct a large-scale fine-grained comparative analysis of machine translations (MT) against human translations (HT) through the lens of morphosyntactic divergence. Across three language pairs and two types of divergence defined as the structural difference between the source and the target, MT is consistently more conservative than HT, with less morphosyntactic diversity, more convergent patterns, and more one-to-one alignments. Through analysis on different decoding algorithms, we attribute this discrepancy to the use of beam search that biases MT towards more convergent patterns. This bias is most amplified when the convergent pattern appears around 50% of the time in training data. Lastly, we show that for a majority of morphosyntactic divergences, their presence in HT is correlated with decreased MT performance, presenting a greater challenge for MT systems.
Ties Matter: Modifying Kendall's Tau for Modern Metric Meta-Evaluation
May 23, 2023



Kendall's tau is frequently used to meta-evaluate how well machine translation (MT) evaluation metrics score individual translations. Its focus on pairwise score comparisons is intuitive but raises the question of how ties should be handled, a gray area that has motivated different variants in the literature. We demonstrate that, in settings like modern MT meta-evaluation, existing variants have weaknesses arising from their handling of ties, and in some situations can even be gamed. We propose a novel variant that gives metrics credit for correctly predicting ties, as well as an optimization procedure that automatically introduces ties into metric scores, enabling fair comparison between metrics that do and do not predict ties. We argue and provide experimental evidence that these modifications lead to fairer Kendall-based assessments of metric performance.
Searching for Needles in a Haystack: On the Role of Incidental Bilingualism in PaLM's Translation Capability
May 17, 2023



Large, multilingual language models exhibit surprisingly good zero- or few-shot machine translation capabilities, despite having never seen the intentionally-included translation examples provided to typical neural translation systems. We investigate the role of incidental bilingualism -- the unintentional consumption of bilingual signals, including translation examples -- in explaining the translation capabilities of large language models, taking the Pathways Language Model (PaLM) as a case study. We introduce a mixed-method approach to measure and understand incidental bilingualism at scale. We show that PaLM is exposed to over 30 million translation pairs across at least 44 languages. Furthermore, the amount of incidental bilingual content is highly correlated with the amount of monolingual in-language content for non-English languages. We relate incidental bilingual content to zero-shot prompts and show that it can be used to mine new prompts to improve PaLM's out-of-English zero-shot translation quality. Finally, in a series of small-scale ablations, we show that its presence has a substantial impact on translation capabilities, although this impact diminishes with model scale.
Document Flattening: Beyond Concatenating Context for Document-Level Neural Machine Translation
Feb 16, 2023Existing work in document-level neural machine translation commonly concatenates several consecutive sentences as a pseudo-document, and then learns inter-sentential dependencies. This strategy limits the model's ability to leverage information from distant context. We overcome this limitation with a novel Document Flattening (DocFlat) technique that integrates Flat-Batch Attention (FBA) and Neural Context Gate (NCG) into Transformer model to utilize information beyond the pseudo-document boundaries. FBA allows the model to attend to all the positions in the batch and learns the relationships between positions explicitly and NCG identifies the useful information from the distant context. We conduct comprehensive experiments and analyses on three benchmark datasets for English-German translation, and validate the effectiveness of two variants of DocFlat. Empirical results show that our approach outperforms strong baselines with statistical significance on BLEU, COMET and accuracy on the contrastive test set. The analyses highlight that DocFlat is highly effective in capturing the long-range information.
The unreasonable effectiveness of few-shot learning for machine translation
Feb 02, 2023



We demonstrate the potential of few-shot translation systems, trained with unpaired language data, for both high and low-resource language pairs. We show that with only 5 examples of high-quality translation data shown at inference, a transformer decoder-only model trained solely with self-supervised learning, is able to match specialized supervised state-of-the-art models as well as more general commercial translation systems. In particular, we outperform the best performing system on the WMT'21 English - Chinese news translation task by only using five examples of English - Chinese parallel data at inference. Moreover, our approach in building these models does not necessitate joint multilingual training or back-translation, is conceptually simple and shows the potential to extend to the multilingual setting. Furthermore, the resulting models are two orders of magnitude smaller than state-of-the-art language models. We then analyze the factors which impact the performance of few-shot translation systems, and highlight that the quality of the few-shot demonstrations heavily determines the quality of the translations generated by our models. Finally, we show that the few-shot paradigm also provides a way to control certain attributes of the translation -- we show that we are able to control for regional varieties and formality using only a five examples at inference, paving the way towards controllable machine translation systems.
Prompting PaLM for Translation: Assessing Strategies and Performance
Nov 16, 2022



Large language models (LLMs) that have been trained on multilingual but not parallel text exhibit a remarkable ability to translate between languages. We probe this ability in an in-depth study of the pathways language model (PaLM), which has demonstrated the strongest machine translation (MT) performance among similarly-trained LLMs to date. We investigate various strategies for choosing translation examples for few-shot prompting, concluding that example quality is the most important factor. Using optimized prompts, we revisit previous assessments of PaLM's MT capabilities with more recent test sets, modern MT metrics, and human evaluation, and find that its performance, while impressive, still lags that of state-of-the-art supervised systems. We conclude by providing an analysis of PaLM's MT output which reveals some interesting properties and prospects for future work.
Toward More Effective Human Evaluation for Machine Translation
Apr 11, 2022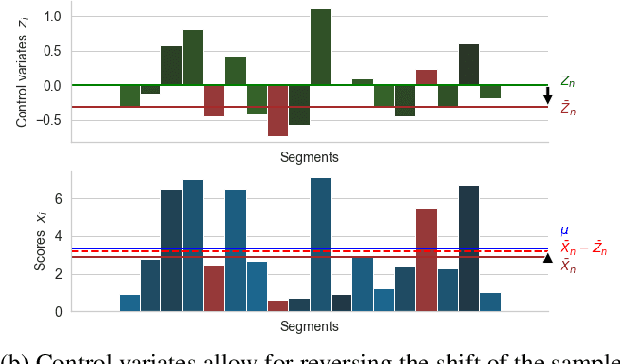
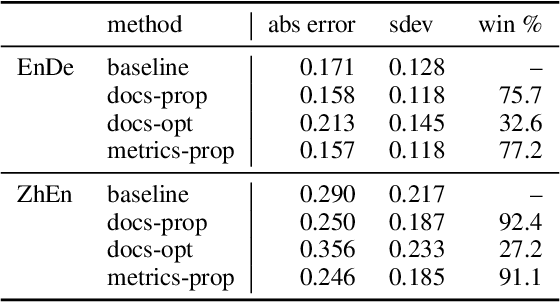
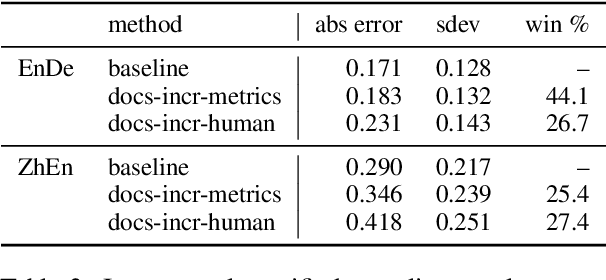
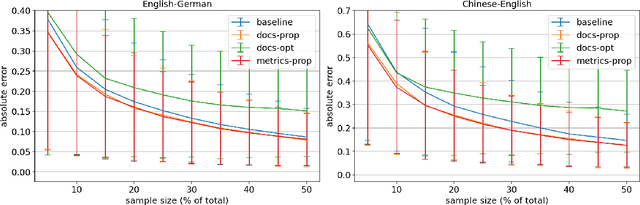
Improvements in text generation technologies such as machine translation have necessitated more costly and time-consuming human evaluation procedures to ensure an accurate signal. We investigate a simple way to reduce cost by reducing the number of text segments that must be annotated in order to accurately predict a score for a complete test set. Using a sampling approach, we demonstrate that information from document membership and automatic metrics can help improve estimates compared to a pure random sampling baseline. We achieve gains of up to 20% in average absolute error by leveraging stratified sampling and control variates. Our techniques can improve estimates made from a fixed annotation budget, are easy to implement, and can be applied to any problem with structure similar to the one we study.