 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Replicable Human Evaluations via Stable Ranking Probability
Apr 01, 2024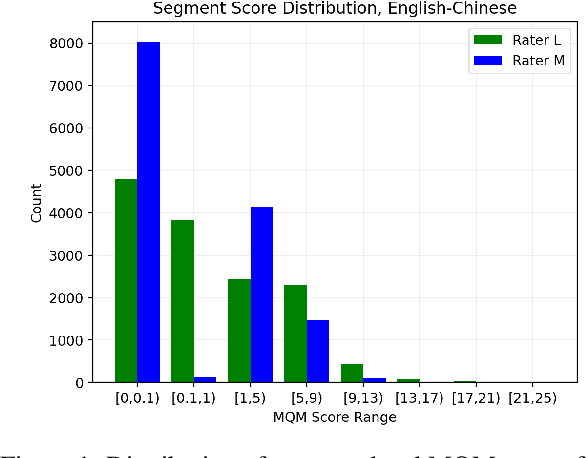


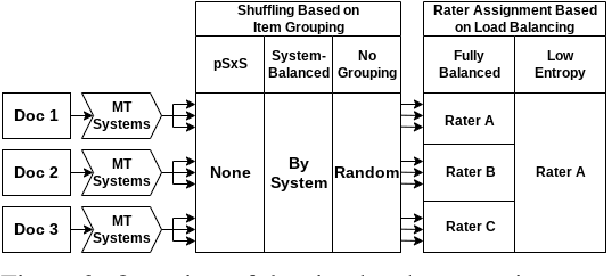
Reliable human evaluation is critical to the development of successful natural language generation models, but achieving it is notoriously difficult. Stability is a crucial requirement when ranking systems by quality: consistent ranking of systems across repeated evaluations is not just desirable, but essential. Without it, there is no reliable foundation for hill-climbing or product launch decisions. In this paper, we use machine translation and its state-of-the-art human evaluation framework, MQM, as a case study to understand how to set up reliable human evaluations that yield stable conclusions. We investigate the optimal configurations for item allocation to raters, number of ratings per item, and score normalization. Our study on two language pairs provides concrete recommendations for designing replicable human evaluation studies. We also collect and release the largest publicly available dataset of multi-segment translations rated by multiple professional translators, consisting of nearly 140,000 segment annotations across two language pairs.
Prompting PaLM for Translation: Assessing Strategies and Performance
Nov 16, 2022



Large language models (LLMs) that have been trained on multilingual but not parallel text exhibit a remarkable ability to translate between languages. We probe this ability in an in-depth study of the pathways language model (PaLM), which has demonstrated the strongest machine translation (MT) performance among similarly-trained LLMs to date. We investigate various strategies for choosing translation examples for few-shot prompting, concluding that example quality is the most important factor. Using optimized prompts, we revisit previous assessments of PaLM's MT capabilities with more recent test sets, modern MT metrics, and human evaluation, and find that its performance, while impressive, still lags that of state-of-the-art supervised systems. We conclude by providing an analysis of PaLM's MT output which reveals some interesting properties and prospects for future work.
DOCmT5: Document-Level Pretraining of Multilingual Language Models
Dec 16, 2021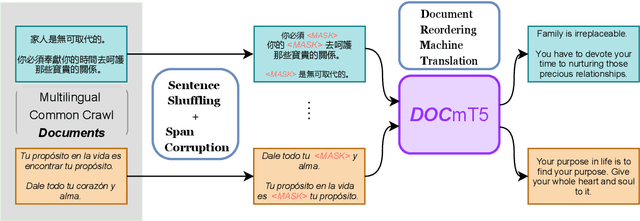
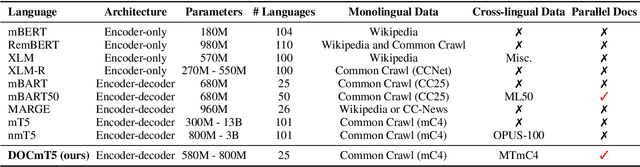
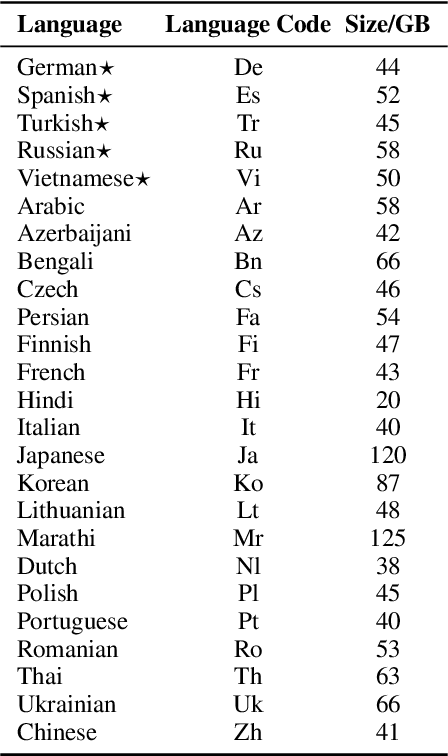
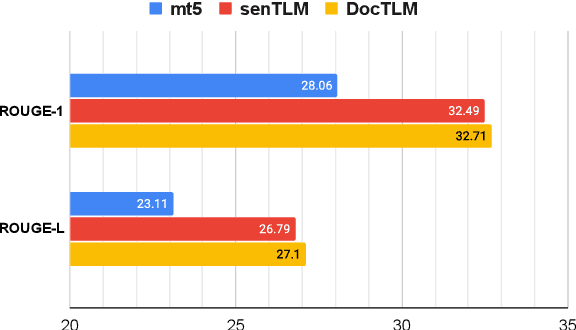
In this paper, we introduce DOCmT5, a multilingual sequence-to-sequence language model pre-trained with large scale parallel documents. While previous approaches have focused on leveraging sentence-level parallel data, we try to build a general-purpose pre-trained model that can understand and generate long documents. We propose a simple and effective pre-training objective - Document Reordering Machine Translation (DrMT), in which the input documents that are shuffled and masked need to be translated. DrMT brings consistent improvements over strong baselines on a variety of document-level generation tasks, including over 12 BLEU points for seen-language-pair document-level MT, over 7 BLEU points for unseen-language-pair document-level MT and over 3 ROUGE-1 points for seen-language-pair cross-lingual summarization. We achieve state-of-the-art (SOTA) on WMT20 De-En and IWSLT15 Zh-En document translation tasks. We also conduct extensive analysis on various factors for document pre-training, including (1) the effects of pre-training data quality and (2) The effects of combining mono-lingual and cross-lingual pre-training. We plan to make our model checkpoints publicly available.
Experts, Errors, and Context: A Large-Scale Study of Human Evaluation for Machine Translation
Apr 29, 2021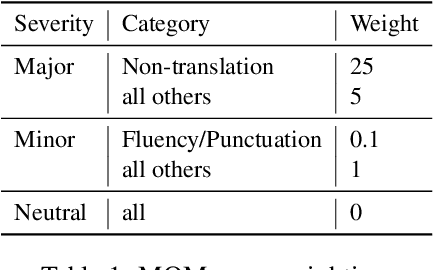
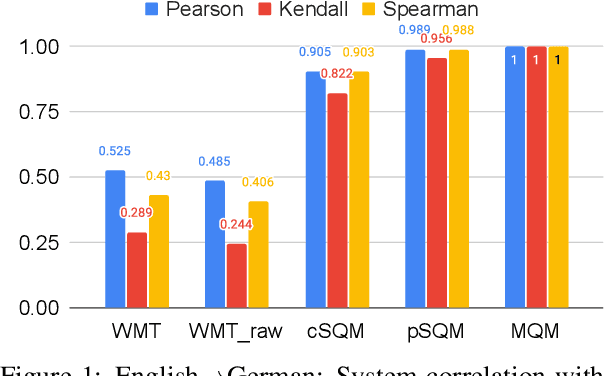
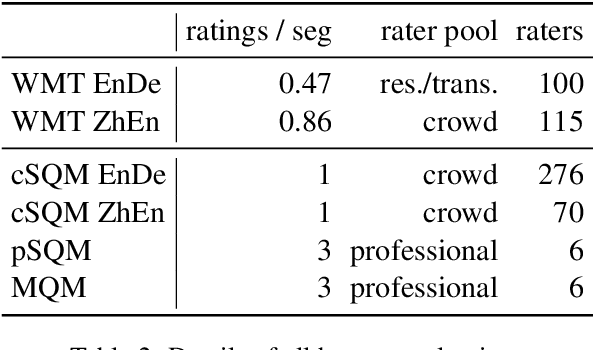
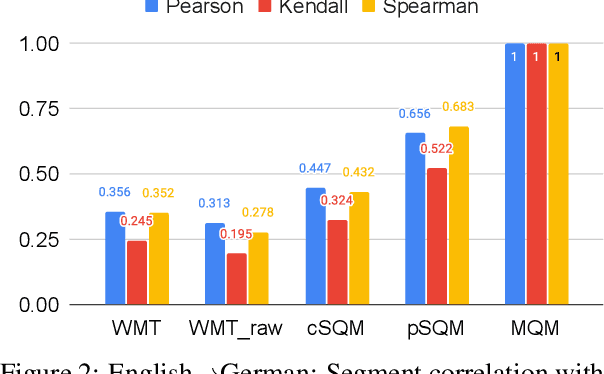
Human evaluation of modern high-quality machine translation systems is a difficult problem, and there is increasing evidence that inadequate evaluation procedures can lead to erroneous conclusions. While there has been considerable research on human evaluation, the field still lacks a commonly-accepted standard procedure. As a step toward this goal, we propose an evaluation methodology grounded in explicit error analysis, based on the Multidimensional Quality Metrics (MQM) framework. We carry out the largest MQM research study to date, scoring the outputs of top systems from the WMT 2020 shared task in two language pairs using annotations provided by professional translators with access to full document context. We analyze the resulting data extensively, finding among other results a substantially different ranking of evaluated systems from the one established by the WMT crowd workers, exhibiting a clear preference for human over machine output. Surprisingly, we also find that automatic metrics based on pre-trained embeddings can outperform human crowd workers. We make our corpus publicly available for further research.