 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Development of Authenticated Clients and Applications for ICICLE CI Services -- Final Report for the REHS Program, June-August, 2022
Apr 17, 2023



The Artificial Intelligence (AI) institute for Intelligent Cyberinfrastructure with Computational Learning in the Environment (ICICLE) is funded by the NSF to build the next generation of Cyberinfrastructure to render AI more accessible to everyone and drive its further democratization in the larger society. We describe our efforts to develop Jupyter Notebooks and Python command line clients that would access these ICICLE resources and services using ICICLE authentication mechanisms. To connect our clients, we used Tapis, which is a framework that supports computational research to enable scientists to access, utilize, and manage multi-institution resources and services. We used Neo4j to organize data into a knowledge graph (KG). We then hosted the KG on a Tapis Pod, which offers persistent data storage with a template made specifically for Neo4j KGs. In order to demonstrate the capabilities of our software, we developed several clients: Jupyter notebooks authentication, Neural Networks (NN) notebook, and command line applications that provide a convenient frontend to the Tapis API. In addition, we developed a data processing notebook that can manipulate KGs on the Tapis servers, including creations of a KG, data upload and modification. In this report we present the software architecture, design and approach, the successfulness of our client software, and future work.
Towards End-to-End In-Image Neural Machine Translation
Oct 20, 2020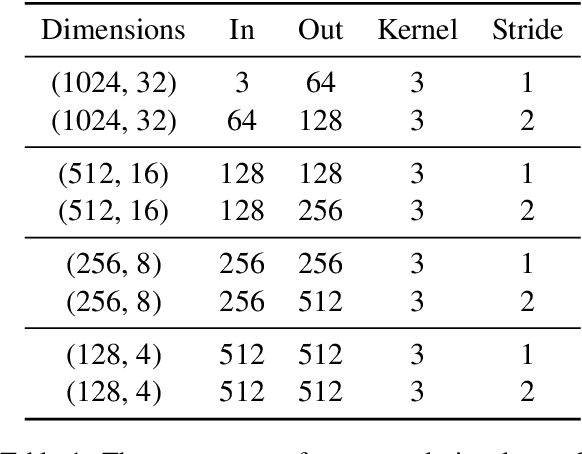

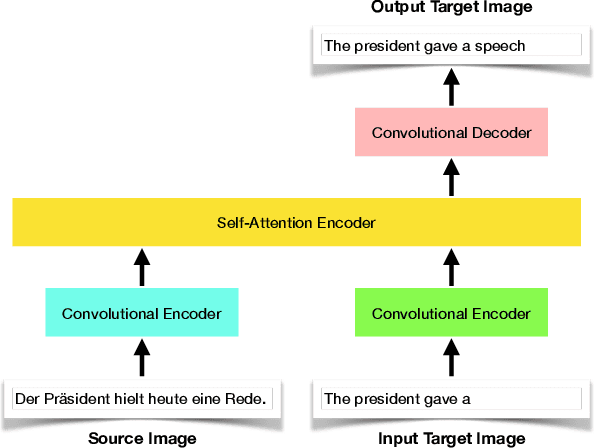
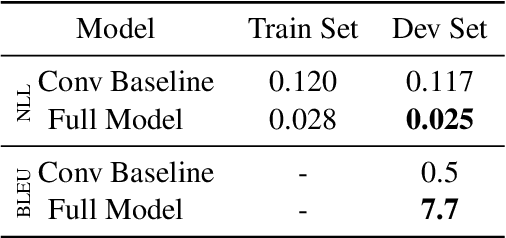
In this paper, we offer a preliminary investigation into the task of in-image machine translation: transforming an image containing text in one language into an image containing the same text in another language. We propose an end-to-end neural model for this task inspired by recent approaches to neural machine translation, and demonstrate promising initial results based purely on pixel-level supervision. We then offer a quantitative and qualitative evaluation of our system outputs and discuss some common failure modes. Finally, we conclude with directions for future work.
Leveraging Monolingual Data with Self-Supervision for Multilingual Neural Machine Translation
May 11, 2020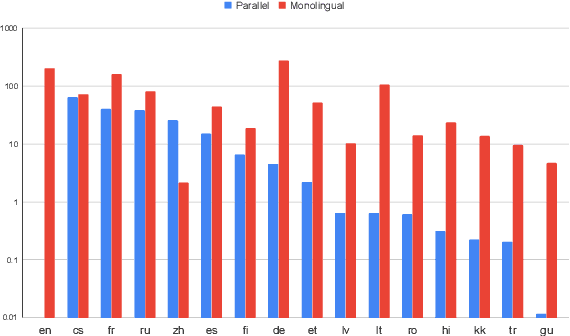

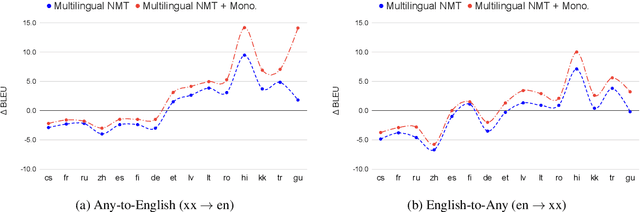
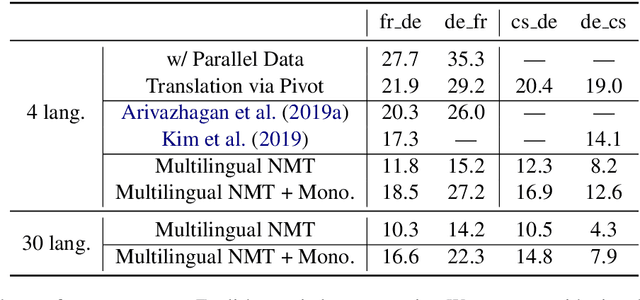
Over the last few years two promising research directions in low-resource neural machine translation (NMT) have emerged. The first focuses on utilizing high-resource languages to improve the quality of low-resource languages via multilingual NMT. The second direction employs monolingual data with self-supervision to pre-train translation models, followed by fine-tuning on small amounts of supervised data. In this work, we join these two lines of research and demonstrate the efficacy of monolingual data with self-supervision in multilingual NMT. We offer three major results: (i) Using monolingual data significantly boosts the translation quality of low-resource languages in multilingual models. (ii) Self-supervision improves zero-shot translation quality in multilingual models. (iii) Leveraging monolingual data with self-supervision provides a viable path towards adding new languages to multilingual models, getting up to 33 BLEU on ro-en translation without any parallel data or back-translation.
Faster Transformer Decoding: N-gram Masked Self-Attention
Jan 14, 2020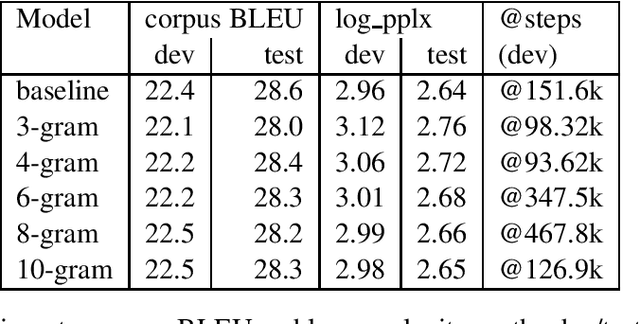
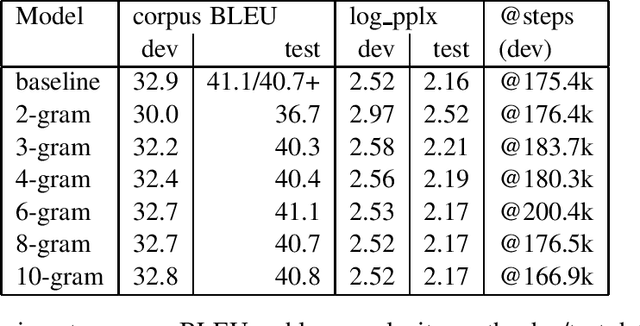
Motivated by the fact that most of the information relevant to the prediction of target tokens is drawn from the source sentence $S=s_1, \ldots, s_S$, we propose truncating the target-side window used for computing self-attention by making an $N$-gram assumption. Experiments on WMT EnDe and EnFr data sets show that the $N$-gram masked self-attention model loses very little in BLEU score for $N$ values in the range $4, \ldots, 8$, depending on the task.