 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards End-to-End In-Image Neural Machine Translation
Oct 20, 2020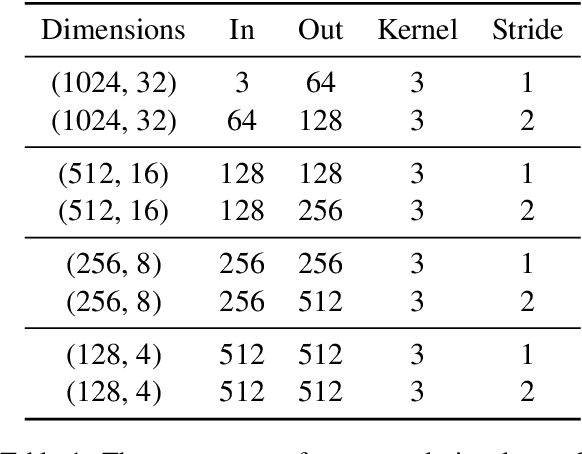

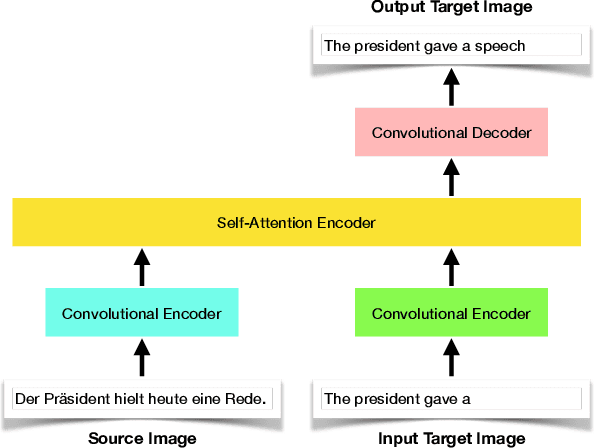
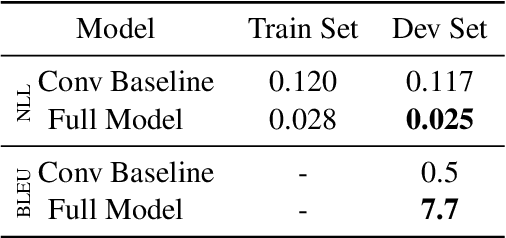
In this paper, we offer a preliminary investigation into the task of in-image machine translation: transforming an image containing text in one language into an image containing the same text in another language. We propose an end-to-end neural model for this task inspired by recent approaches to neural machine translation, and demonstrate promising initial results based purely on pixel-level supervision. We then offer a quantitative and qualitative evaluation of our system outputs and discuss some common failure modes. Finally, we conclude with directions for future work.
Semantic Scaffolds for Pseudocode-to-Code Generation
May 12, 2020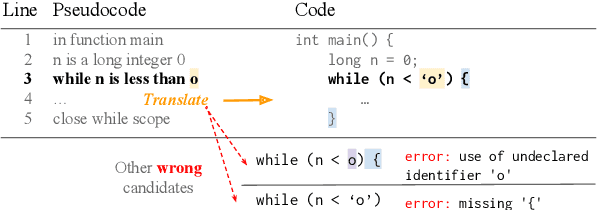
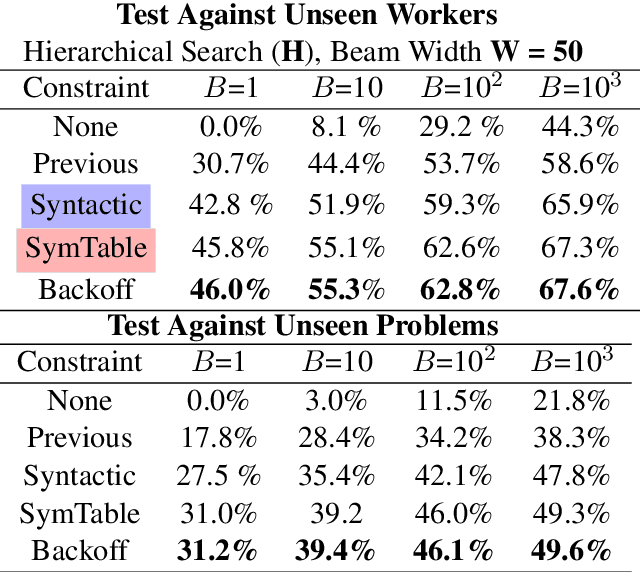

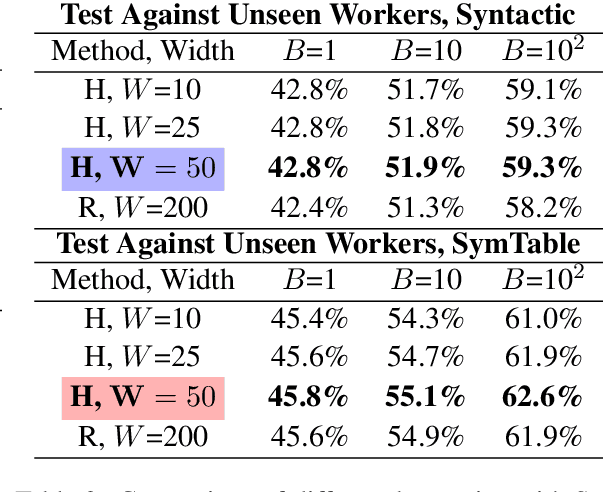
We propose a method for program generation based on semantic scaffolds, lightweight structures representing the high-level semantic and syntactic composition of a program. By first searching over plausible scaffolds then using these as constraints for a beam search over programs, we achieve better coverage of the search space when compared with existing techniques. We apply our hierarchical search method to the SPoC dataset for pseudocode-to-code generation, in which we are given line-level natural language pseudocode annotations and aim to produce a program satisfying execution-based test cases. By using semantic scaffolds during inference, we achieve a 10% absolute improvement in top-100 accuracy over the previous state-of-the-art. Additionally, we require only 11 candidates to reach the top-3000 performance of the previous best approach when tested against unseen problems, demonstrating a substantial improvement in efficiency.
Imitation Attacks and Defenses for Black-box Machine Translation Systems
Apr 30, 2020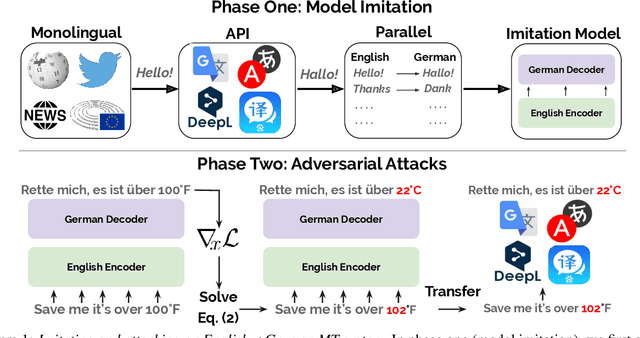
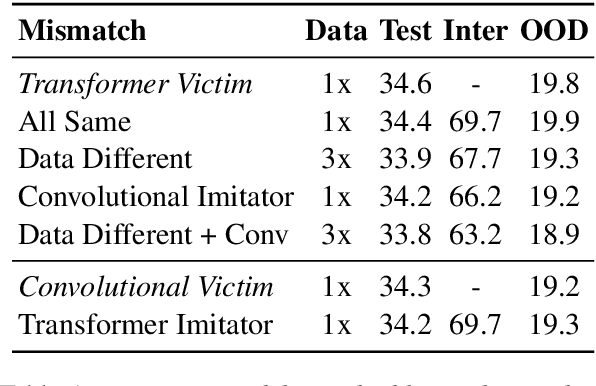
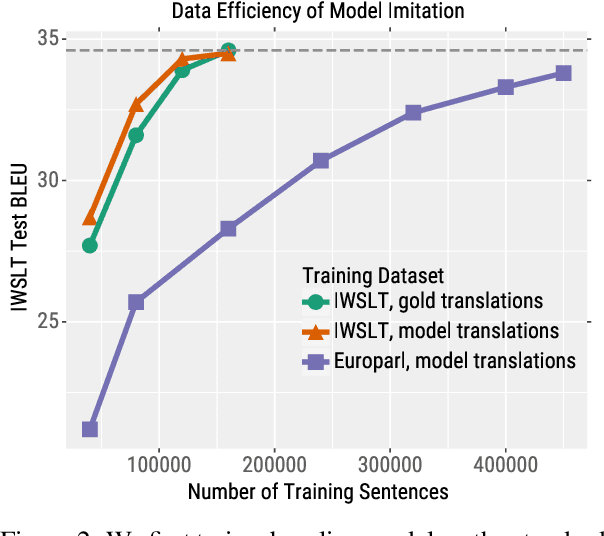
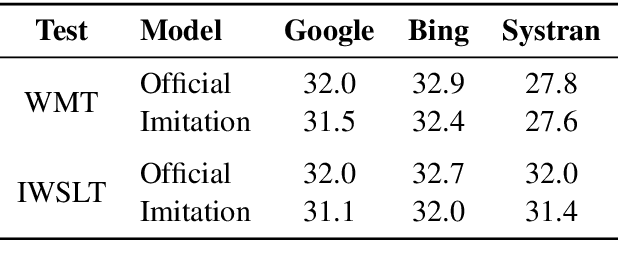
We consider an adversary looking to steal or attack a black-box machine translation (MT) system, either for financial gain or to exploit model errors. We first show that black-box MT systems can be stolen by querying them with monolingual sentences and training models to imitate their outputs. Using simulated experiments, we demonstrate that MT model stealing is possible even when imitation models have different input data or architectures than their victims. Applying these ideas, we train imitation models that reach within 0.6 BLEU of three production MT systems on both high-resource and low-resource language pairs. We then leverage the similarity of our imitation models to transfer adversarial examples to the production systems. We use gradient-based attacks that expose inputs which lead to semantically-incorrect translations, dropped content, and vulgar model outputs. To mitigate these vulnerabilities, we propose a defense that modifies translation outputs in order to misdirect the optimization of imitation models. This defense degrades imitation model BLEU and attack transfer rates at some cost in BLEU and inference speed.
Insertion-Deletion Transformer
Jan 15, 2020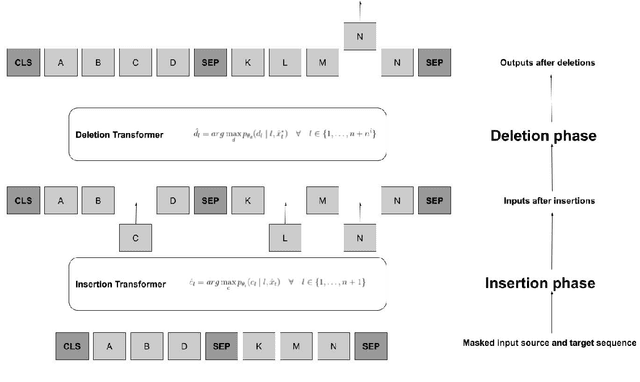



We propose the Insertion-Deletion Transformer, a novel transformer-based neural architecture and training method for sequence generation. The model consists of two phases that are executed iteratively, 1) an insertion phase and 2) a deletion phase. The insertion phase parameterizes a distribution of insertions on the current output hypothesis, while the deletion phase parameterizes a distribution of deletions over the current output hypothesis. The training method is a principled and simple algorithm, where the deletion model obtains its signal directly on-policy from the insertion model output. We demonstrate the effectiveness of our Insertion-Deletion Transformer on synthetic translation tasks, obtaining significant BLEU score improvement over an insertion-only model.
An Empirical Study of Generation Order for Machine Translation
Oct 29, 2019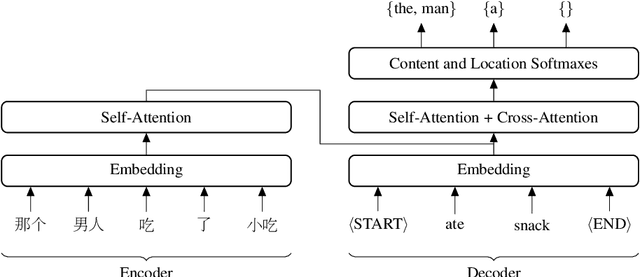


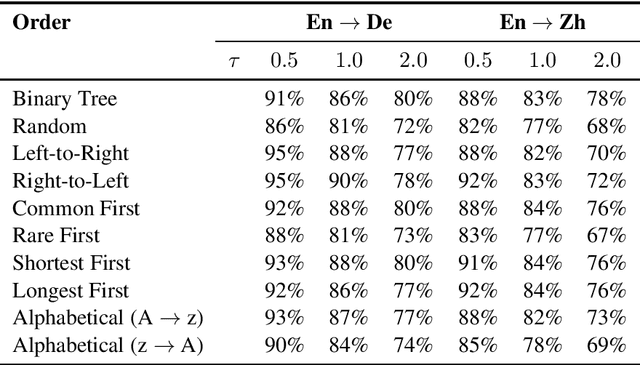
In this work, we present an empirical study of generation order for machine translation. Building on recent advances in insertion-based modeling, we first introduce a soft order-reward framework that enables us to train models to follow arbitrary oracle generation policies. We then make use of this framework to explore a large variety of generation orders, including uninformed orders, location-based orders, frequency-based orders, content-based orders, and model-based orders. Curiously, we find that for the WMT'14 English $\to$ German translation task, order does not have a substantial impact on output quality, with unintuitive orderings such as alphabetical and shortest-first matching the performance of a standard Transformer. This demonstrates that traditional left-to-right generation is not strictly necessary to achieve high performance. On the other hand, results on the WMT'18 English $\to$ Chinese task tend to vary more widely, suggesting that translation for less well-aligned language pairs may be more sensitive to generation order.
KERMIT: Generative Insertion-Based Modeling for Sequences
Jun 04, 2019

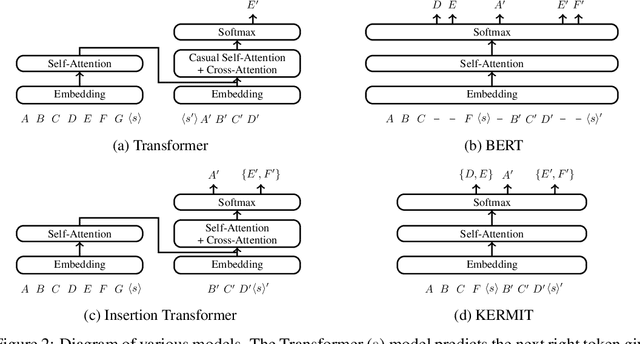
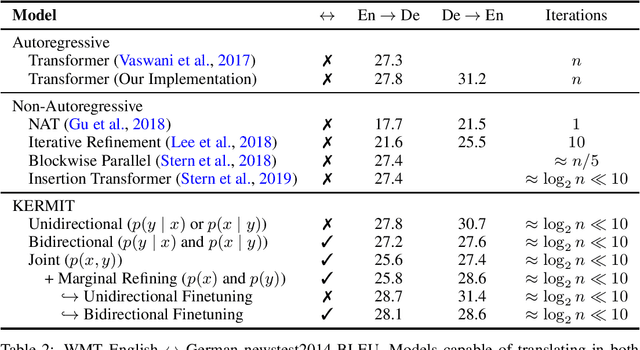
We present KERMIT, a simple insertion-based approach to generative modeling for sequences and sequence pairs. KERMIT models the joint distribution and its decompositions (i.e., marginals and conditionals) using a single neural network and, unlike much prior work, does not rely on a prespecified factorization of the data distribution. During training, one can feed KERMIT paired data $(x, y)$ to learn the joint distribution $p(x, y)$, and optionally mix in unpaired data $x$ or $y$ to refine the marginals $p(x)$ or $p(y)$. During inference, we have access to the conditionals $p(x \mid y)$ and $p(y \mid x)$ in both directions. We can also sample from the joint distribution or the marginals. The model supports both serial fully autoregressive decoding and parallel partially autoregressive decoding, with the latter exhibiting an empirically logarithmic runtime. We demonstrate through experiments in machine translation, representation learning, and zero-shot cloze question answering that our unified approach is capable of matching or exceeding the performance of dedicated state-of-the-art systems across a wide range of tasks without the need for problem-specific architectural adaptation.
Insertion Transformer: Flexible Sequence Generation via Insertion Operations
Feb 08, 2019
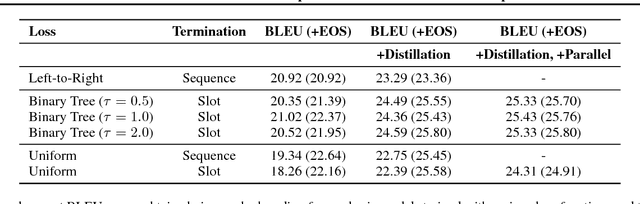
We present the Insertion Transformer, an iterative, partially autoregressive model for sequence generation based on insertion operations. Unlike typical autoregressive models which rely on a fixed, often left-to-right ordering of the output, our approach accommodates arbitrary orderings by allowing for tokens to be inserted anywhere in the sequence during decoding. This flexibility confers a number of advantages: for instance, not only can our model be trained to follow specific orderings such as left-to-right generation or a binary tree traversal, but it can also be trained to maximize entropy over all valid insertions for robustness. In addition, our model seamlessly accommodates both fully autoregressive generation (one insertion at a time) and partially autoregressive generation (simultaneous insertions at multiple locations). We validate our approach by analyzing its performance on the WMT 2014 English-German machine translation task under various settings for training and decoding. We find that the Insertion Transformer outperforms many prior non-autoregressive approaches to translation at comparable or better levels of parallelism, and successfully recovers the performance of the original Transformer while requiring only logarithmically many iterations during decoding.
Blockwise Parallel Decoding for Deep Autoregressive Models
Nov 07, 2018
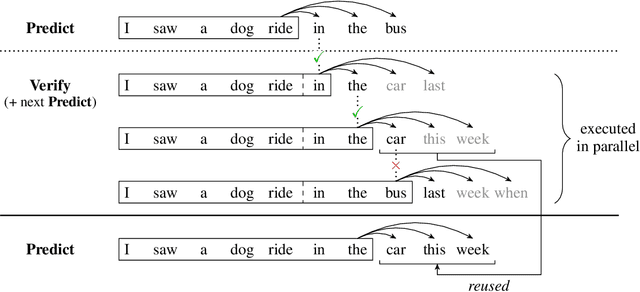
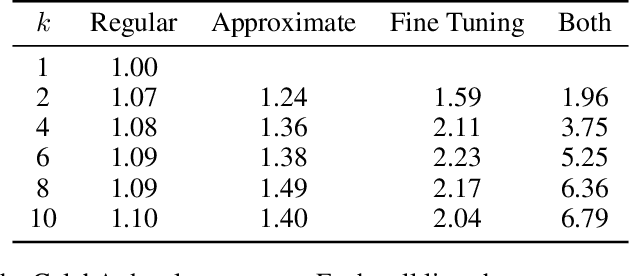
Deep autoregressive sequence-to-sequence models have demonstrated impressive performance across a wide variety of tasks in recent years. While common architecture classes such as recurrent, convolutional, and self-attention networks make different trade-offs between the amount of computation needed per layer and the length of the critical path at training time, generation still remains an inherently sequential process. To overcome this limitation, we propose a novel blockwise parallel decoding scheme in which we make predictions for multiple time steps in parallel then back off to the longest prefix validated by a scoring model. This allows for substantial theoretical improvements in generation speed when applied to architectures that can process output sequences in parallel. We verify our approach empirically through a series of experiments using state-of-the-art self-attention models for machine translation and image super-resolution, achieving iteration reductions of up to 2x over a baseline greedy decoder with no loss in quality, or up to 7x in exchange for a slight decrease in performance. In terms of wall-clock time, our fastest models exhibit real-time speedups of up to 4x over standard greedy decoding.
Kernel Feature Selection via Conditional Covariance Minimization
Oct 20, 2018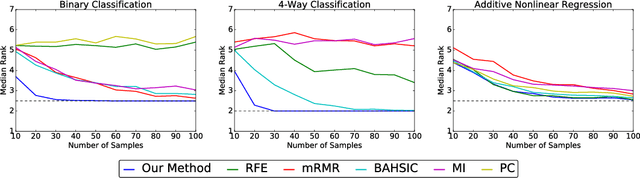

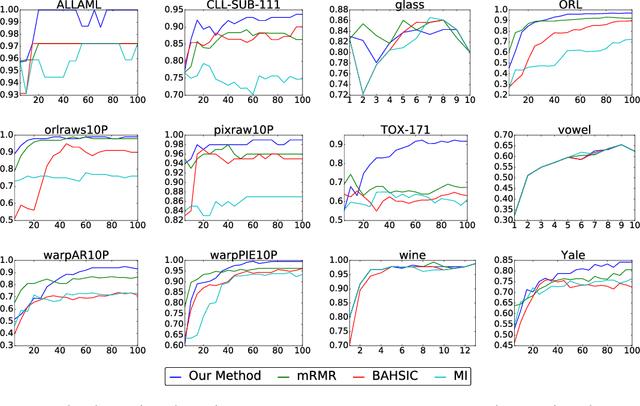
We propose a method for feature selection that employs kernel-based measures of independence to find a subset of covariates that is maximally predictive of the response. Building on past work in kernel dimension reduction, we show how to perform feature selection via a constrained optimization problem involving the trace of the conditional covariance operator. We prove various consistency results for this procedure, and also demonstrate that our method compares favorably with other state-of-the-art algorithms on a variety of synthetic and real data sets.
The Marginal Value of Adaptive Gradient Methods in Machine Learning
May 22, 2018
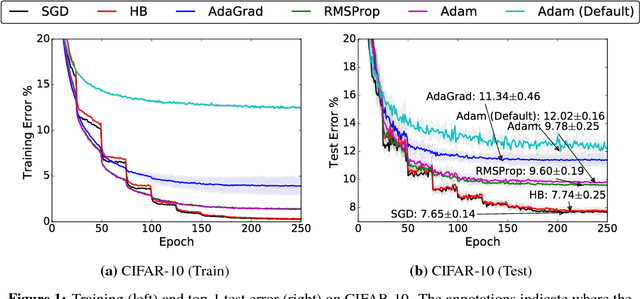

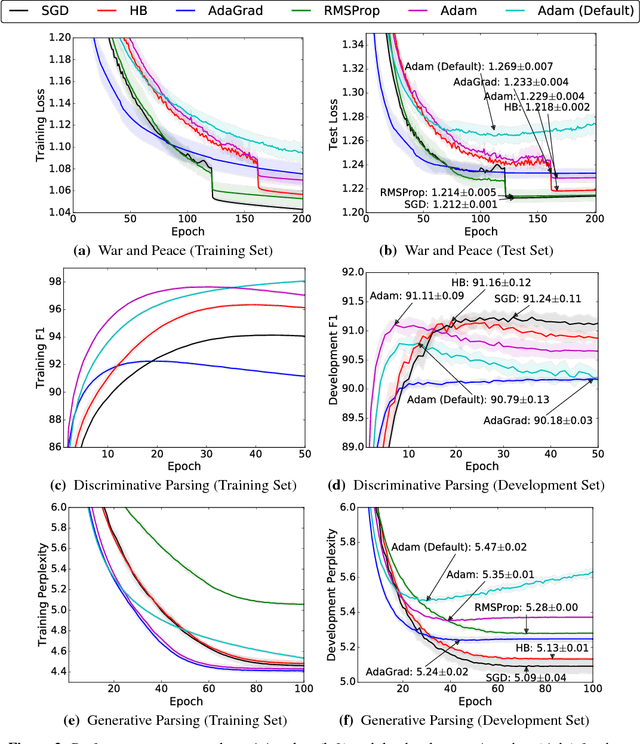
Adaptive optimization methods, which perform local optimization with a metric constructed from the history of iterates, are becoming increasingly popular for training deep neural networks. Examples include AdaGrad, RMSProp, and Adam. We show that for simple overparameterized problems, adaptive methods often find drastically different solutions than gradient descent (GD) or stochastic gradient descent (SGD). We construct an illustrative binary classification problem where the data is linearly separable, GD and SGD achieve zero test error, and AdaGrad, Adam, and RMSProp attain test errors arbitrarily close to half. We additionally study the empirical generalization capability of adaptive methods on several state-of-the-art deep learning models. We observe that the solutions found by adaptive methods generalize worse (often significantly worse) than SGD, even when these solutions have better training performance. These results suggest that practitioners should reconsider the use of adaptive methods to train neural networks.