 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuTE: decentralized multiple testing on sensor networks with false discovery rate control
Oct 09, 2022



This paper designs methods for decentralized multiple hypothesis testing on graphs that are equipped with provable guarantees on the false discovery rate (FDR). We consider the setting where distinct agents reside on the nodes of an undirected graph, and each agent possesses p-values corresponding to one or more hypotheses local to its node. Each agent must individually decide whether to reject one or more of its local hypotheses by only communicating with its neighbors, with the joint aim that the global FDR over the entire graph must be controlled at a predefined level. We propose a simple decentralized family of Query-Test-Exchange (QuTE) algorithms and prove that they can control FDR under independence or positive dependence of the p-values. Our algorithm reduces to the Benjamini-Hochberg (BH) algorithm when after graph-diameter rounds of communication, and to the Bonferroni procedure when no communication has occurred or the graph is empty. To avoid communicating real-valued p-values, we develop a quantized BH procedure, and extend it to a quantized QuTE procedure. QuTE works seamlessly in streaming data settings, where anytime-valid p-values may be continually updated at each node. Last, QuTE is robust to arbitrary dropping of packets, or a graph that changes at every step, making it particularly suitable to mobile sensor networks involving drones or other multi-agent systems. We study the power of our procedure using a simulation suite of different levels of connectivity and communication on a variety of graph structures, and also provide an illustrative real-world example.
A Transformer-based deep neural network model for SSVEP classification
Oct 09, 2022



Steady-state visual evoked potential (SSVEP) is one of the most commonly used control signal in the brain-computer interface (BCI) systems. However, the conventional spatial filtering methods for SSVEP classification highly depend on the subject-specific calibration data. The need for the methods that can alleviate the demand for the calibration data become urgent. In recent years, developing the methods that can work in inter-subject classification scenario has become a promising new direction. As the popular deep learning model nowadays, Transformer has excellent performance and has been used in EEG signal classification tasks. Therefore, in this study, we propose a deep learning model for SSVEP classification based on Transformer structure in inter-subject classification scenario, termed as SSVEPformer, which is the first application of the transformer to the classification of SSVEP. Inspired by previous studies, the model adopts the frequency spectrum of SSVEP data as input, and explores the spectral and spatial domain information for classification. Furthermore, to fully utilize the harmonic information, an extended SSVEPformer based on the filter bank technology (FB-SSVEPformer) is proposed to further improve the classification performance. Experiments were conducted using two open datasets (Dataset 1: 10 subjects, 12-class task; Dataset 2: 35 subjects, 40-class task) in the inter-subject classification scenario. The experimental results show that the proposed models could achieve better results in terms of classification accuracy and information transfer rate, compared with other baseline methods. The proposed model validates the feasibility of deep learning models based on Transformer structure for SSVEP classification task, and could serve as a potential model to alleviate the calibration procedure in the practical application of SSVEP-based BCI systems.
ML-LOO: Detecting Adversarial Examples with Feature Attribution
Jun 08, 2019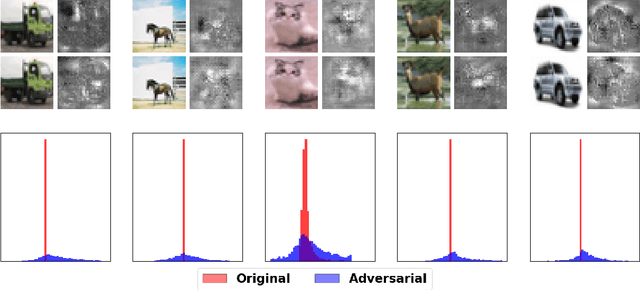
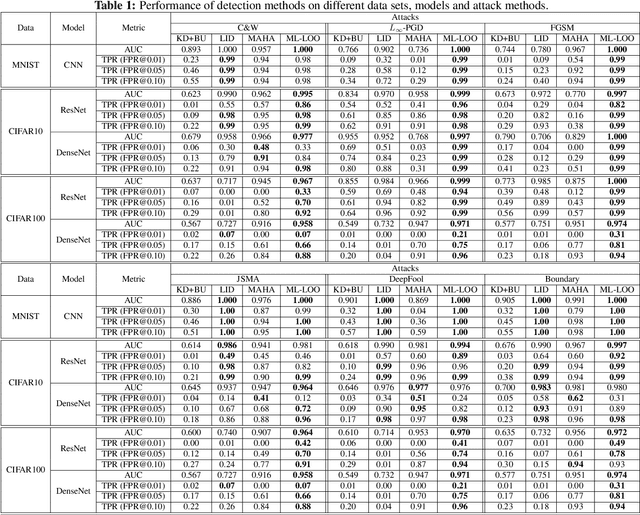
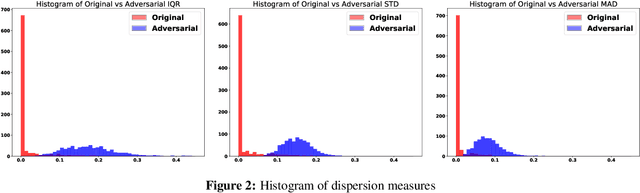
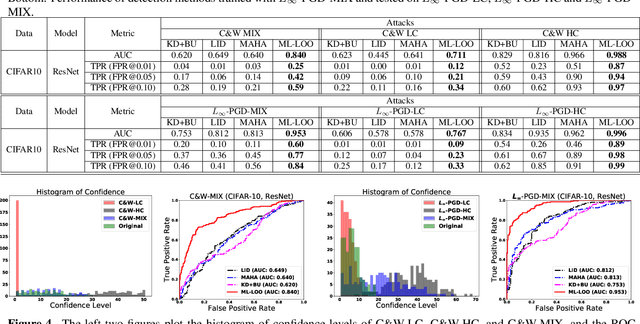
Deep neural networks obtain state-of-the-art performance on a series of tasks. However, they are easily fooled by adding a small adversarial perturbation to input. The perturbation is often human imperceptible on image data. We observe a significant difference in feature attributions of adversarially crafted examples from those of original ones. Based on this observation, we introduce a new framework to detect adversarial examples through thresholding a scale estimate of feature attribution scores. Furthermore, we extend our method to include multi-layer feature attributions in order to tackle the attacks with mixed confidence levels. Through vast experiments, our method achieves superior performances in distinguishing adversarial examples from popular attack methods on a variety of real data sets among state-of-the-art detection methods. In particular, our method is able to detect adversarial examples of mixed confidence levels, and transfer between different attacking methods.
Boundary Attack++: Query-Efficient Decision-Based Adversarial Attack
Apr 03, 2019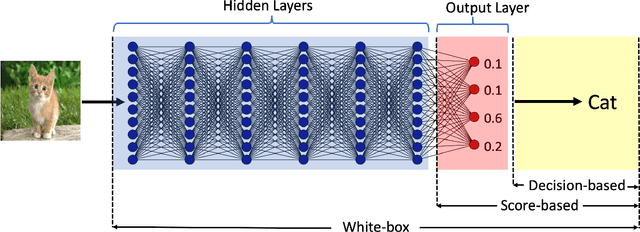
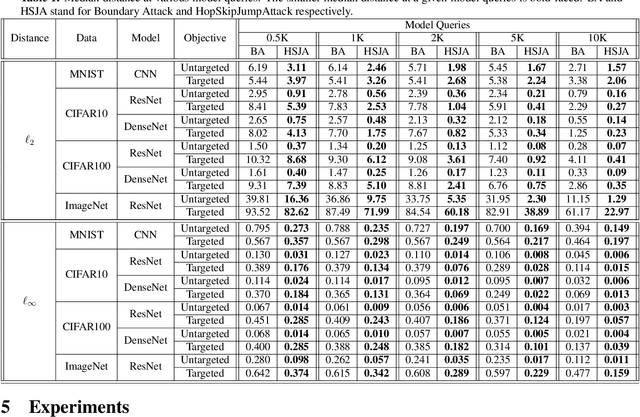
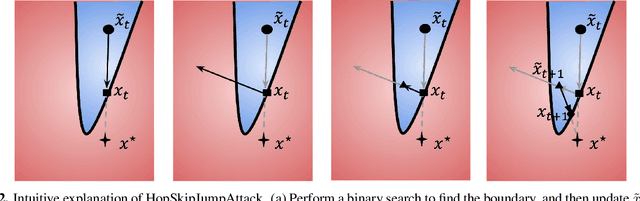
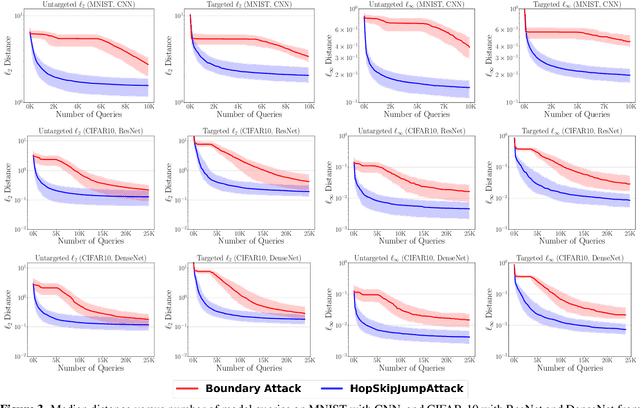
Decision-based adversarial attack studies the generation of adversarial examples that solely rely on output labels of a target model. In this paper, decision-based adversarial attack was formulated as an optimization problem. Motivated by zeroth-order optimization, we develop Boundary Attack++, a family of algorithms based on a novel estimate of gradient direction using binary information at the decision boundary. By switching between two types of projection operators, our algorithms are capable of optimizing $L_2$ and $L_\infty$ distances respectively. Experiments show Boundary Attack++ requires significantly fewer model queries than Boundary Attack. We also show our algorithm achieves superior performance compared to state-of-the-art white-box algorithms in attacking adversarially trained models on MNIST.
LS-Tree: Model Interpretation When the Data Are Linguistic
Feb 11, 2019



We study the problem of interpreting trained classification models in the setting of linguistic data sets. Leveraging a parse tree, we propose to assign least-squares based importance scores to each word of an instance by exploiting syntactic constituency structure. We establish an axiomatic characterization of these importance scores by relating them to the Banzhaf value in coalitional game theory. Based on these importance scores, we develop a principled method for detecting and quantifying interactions between words in a sentence. We demonstrate that the proposed method can aid in interpretability and diagnostics for several widely-used language models.
Kernel Feature Selection via Conditional Covariance Minimization
Oct 20, 2018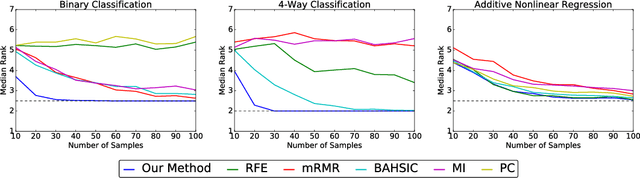

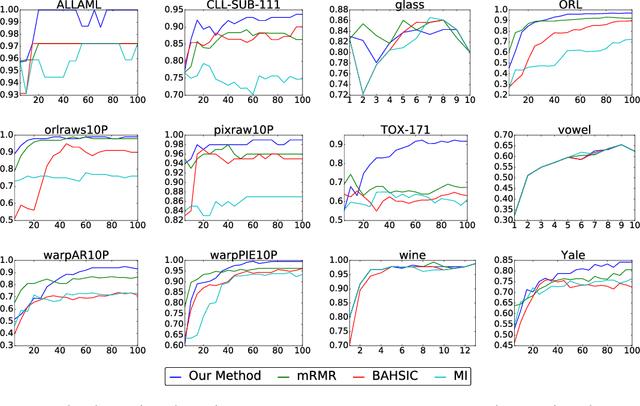
We propose a method for feature selection that employs kernel-based measures of independence to find a subset of covariates that is maximally predictive of the response. Building on past work in kernel dimension reduction, we show how to perform feature selection via a constrained optimization problem involving the trace of the conditional covariance operator. We prove various consistency results for this procedure, and also demonstrate that our method compares favorably with other state-of-the-art algorithms on a variety of synthetic and real data sets.
L-Shapley and C-Shapley: Efficient Model Interpretation for Structured Data
Aug 08, 2018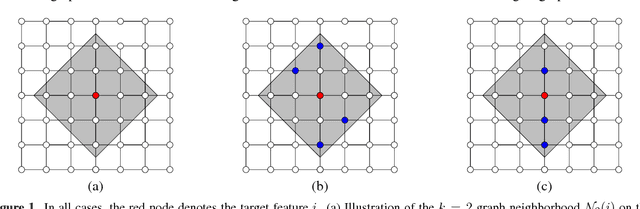



We study instancewise feature importance scoring as a method for model interpretation. Any such method yields, for each predicted instance, a vector of importance scores associated with the feature vector. Methods based on the Shapley score have been proposed as a fair way of computing feature attributions of this kind, but incur an exponential complexity in the number of features. This combinatorial explosion arises from the definition of the Shapley value and prevents these methods from being scalable to large data sets and complex models. We focus on settings in which the data have a graph structure, and the contribution of features to the target variable is well-approximated by a graph-structured factorization. In such settings, we develop two algorithms with linear complexity for instancewise feature importance scoring. We establish the relationship of our methods to the Shapley value and another closely related concept known as the Myerson value from cooperative game theory. We demonstrate on both language and image data that our algorithms compare favorably with other methods for model interpretation.
Learning to Explain: An Information-Theoretic Perspective on Model Interpretation
Jun 14, 2018



We introduce instancewise feature selection as a methodology for model interpretation. Our method is based on learning a function to extract a subset of features that are most informative for each given example. This feature selector is trained to maximize the mutual information between selected features and the response variable, where the conditional distribution of the response variable given the input is the model to be explained. We develop an efficient variational approximation to the mutual information, and show the effectiveness of our method on a variety of synthetic and real data sets using both quantitative metrics and human evaluation.
Language-Based Image Editing with Recurrent Attentive Models
Jun 10, 2018
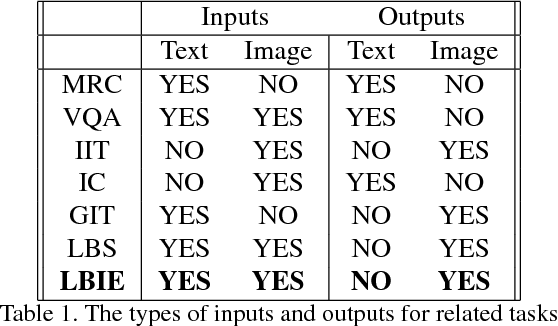


We investigate the problem of Language-Based Image Editing (LBIE). Given a source image and a natural language description, we want to generate a target image by editing the source image based on the description. We propose a generic modeling framework for two sub-tasks of LBIE: language-based image segmentation and image colorization. The framework uses recurrent attentive models to fuse image and language features. Instead of using a fixed step size, we introduce for each region of the image a termination gate to dynamically determine after each inference step whether to continue extrapolating additional information from the textual description. The effectiveness of the framework is validated on three datasets. First, we introduce a synthetic dataset, called CoSaL, to evaluate the end-to-end performance of our LBIE system. Second, we show that the framework leads to state-of-the-art performance on image segmentation on the ReferIt dataset. Third, we present the first language-based colorization result on the Oxford-102 Flowers dataset.
Greedy Attack and Gumbel Attack: Generating Adversarial Examples for Discrete Data
May 31, 2018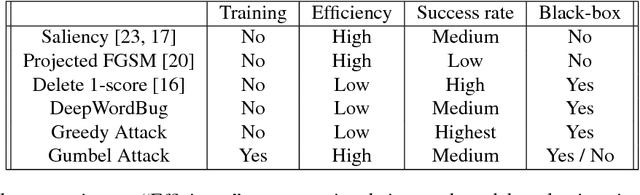

We present a probabilistic framework for studying adversarial attacks on discrete data. Based on this framework, we derive a perturbation-based method, Greedy Attack, and a scalable learning-based method, Gumbel Attack, that illustrate various tradeoffs in the design of attacks. We demonstrate the effectiveness of these methods using both quantitative metrics and human evaluation on various state-of-the-art models for text classification, including a word-based CNN, a character-based CNN and an LSTM. As as example of our results, we show that the accuracy of character-based convolutional networks drops to the level of random selection by modifying only five characters through Greedy Attack.