 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA1: A Fully Transparent Open-Source, Adaptive and Efficient Truncated Vision-Language-Action Model
Apr 07, 2026Vision--Language--Action (VLA) models have emerged as a powerful paradigm for open-world robot manipulation, but their practical deployment is often constrained by \emph{cost}: billion-scale VLM backbones and iterative diffusion/flow-based action heads incur high latency and compute, making real-time control expensive on commodity hardware. We present A1, a fully open-source and transparent VLA framework designed for low-cost, high-throughput inference without sacrificing manipulation success; Our approach leverages pretrained VLMs that provide implicit affordance priors for action generation. We release the full training stack (training code, data/data-processing pipeline, intermediate checkpoints, and evaluation scripts) to enable end-to-end reproducibility. Beyond optimizing the VLM alone, A1 targets the full inference pipeline by introducing a budget-aware adaptive inference scheme that jointly accelerates the backbone and the \emph{action head}. Specifically, we monitor action consistency across intermediate VLM layers to trigger early termination, and propose Inter-Layer Truncated Flow Matching that warm-starts denoising across layers, enabling accurate actions with substantially fewer effective denoising iterations. Across simulation benchmarks (LIBERO, VLABench) and real robots (Franka, AgiBot), A1 achieves state-of-the-art success rates while significantly reducing inference cost (e.g., up to 72% lower per-episode latency for flow-matching inference and up to 76.6% backbone computation reduction with minor performance degradation). On RoboChallenge, A1 achieves an average success rate of 29.00%, outperforming baselines including pi0(28.33%), X-VLA (21.33%), and RDT-1B (15.00%).
PhysMoDPO: Physically-Plausible Humanoid Motion with Preference Optimization
Mar 16, 2026Recent progress in text-conditioned human motion generation has been largely driven by diffusion models trained on large-scale human motion data. Building on this progress, recent methods attempt to transfer such models for character animation and real robot control by applying a Whole-Body Controller (WBC) that converts diffusion-generated motions into executable trajectories. While WBC trajectories become compliant with physics, they may expose substantial deviations from original motion. To address this issue, we here propose PhysMoDPO, a Direct Preference Optimization framework. Unlike prior work that relies on hand-crafted physics-aware heuristics such as foot-sliding penalties, we integrate WBC into our training pipeline and optimize diffusion model such that the output of WBC becomes compliant both with physics and original text instructions. To train PhysMoDPO we deploy physics-based and task-specific rewards and use them to assign preference to synthesized trajectories. Our extensive experiments on text-to-motion and spatial control tasks demonstrate consistent improvements of PhysMoDPO in both physical realism and task-related metrics on simulated robots. Moreover, we demonstrate that PhysMoDPO results in significant improvements when applied to zero-shot motion transfer in simulation and for real-world deployment on a G1 humanoid robot.
SPECTRE: Spectral Pre-training Embeddings with Cylindrical Temporal Rotary Position Encoding for Fine-Grained sEMG-Based Movement Decoding
Dec 27, 2025Decoding fine-grained movement from non-invasive surface Electromyography (sEMG) is a challenge for prosthetic control due to signal non-stationarity and low signal-to-noise ratios. Generic self-supervised learning (SSL) frameworks often yield suboptimal results on sEMG as they attempt to reconstruct noisy raw signals and lack the inductive bias to model the cylindrical topology of electrode arrays. To overcome these limitations, we introduce SPECTRE, a domain-specific SSL framework. SPECTRE features two primary contributions: a physiologically-grounded pre-training task and a novel positional encoding. The pre-training involves masked prediction of discrete pseudo-labels from clustered Short-Time Fourier Transform (STFT) representations, compelling the model to learn robust, physiologically relevant frequency patterns. Additionally, our Cylindrical Rotary Position Embedding (CyRoPE) factorizes embeddings along linear temporal and annular spatial dimensions, explicitly modeling the forearm sensor topology to capture muscle synergies. Evaluations on multiple datasets, including challenging data from individuals with amputation, demonstrate that SPECTRE establishes a new state-of-the-art for movement decoding, significantly outperforming both supervised baselines and generic SSL approaches. Ablation studies validate the critical roles of both spectral pre-training and CyRoPE. SPECTRE provides a robust foundation for practical myoelectric interfaces capable of handling real-world sEMG complexities.
Short-time SSVEP data extension by a novel generative adversarial networks based framework
Jan 18, 2023Steady-state visual evoked potentials (SSVEPs) based brain-computer interface (BCI) has received considerable attention due to its high transfer rate and available quantity of targets. However, the performance of frequency identification methods heavily hinges on the amount of user calibration data and data length, which hinders the deployment in real-world applications. Recently, generative adversarial networks (GANs)-based data generation methods have been widely adopted to create supplementary synthetic electroencephalography (EEG) data, holds promise to address these issues. In this paper, we proposed a GAN-based end-to-end signal transformation network for data length window extension, termed as TEGAN. TEGAN transforms short-time SSVEP signals into long-time artificial SSVEP signals. By incorporating a novel U-Net generator architecture and auxiliary classifier into the network design, the TEGAN could produce conditioned features in the synthetic data. Additionally, to regularize the training process of GAN, we introduced a two-stage training strategy and the LeCam-divergence regularization term during the network implementation. The proposed TEGAN was evaluated on two public SSVEP datasets. With the assistance of TEGAN, the performance of traditional frequency recognition methods and deep learning-based methods have been significantly improved under limited calibration data. This study substantiates the feasibility of the proposed method to extend the data length for short-time SSVEP signals to develop a high-performance BCI system. The proposed GAN-based methods have the great potential of shortening the calibration time for various real-world BCI-based applications, while the novelty of our augmentation strategies shed some value light on understanding the subject-invariant properties of SSVEPs.
T2M-GPT: Generating Human Motion from Textual Descriptions with Discrete Representations
Jan 18, 2023



In this work, we investigate a simple and must-known conditional generative framework based on Vector Quantised-Variational AutoEncoder (VQ-VAE) and Generative Pre-trained Transformer (GPT) for human motion generation from textural descriptions. We show that a simple CNN-based VQ-VAE with commonly used training recipes (EMA and Code Reset) allows us to obtain high-quality discrete representations. For GPT, we incorporate a simple corruption strategy during the training to alleviate training-testing discrepancy. Despite its simplicity, our T2M-GPT shows better performance than competitive approaches, including recent diffusion-based approaches. For example, on HumanML3D, which is currently the largest dataset, we achieve comparable performance on the consistency between text and generated motion (R-Precision), but with FID 0.116 largely outperforming MotionDiffuse of 0.630. Additionally, we conduct analyses on HumanML3D and observe that the dataset size is a limitation of our approach. Our work suggests that VQ-VAE still remains a competitive approach for human motion generation.
A Transformer-based deep neural network model for SSVEP classification
Oct 09, 2022



Steady-state visual evoked potential (SSVEP) is one of the most commonly used control signal in the brain-computer interface (BCI) systems. However, the conventional spatial filtering methods for SSVEP classification highly depend on the subject-specific calibration data. The need for the methods that can alleviate the demand for the calibration data become urgent. In recent years, developing the methods that can work in inter-subject classification scenario has become a promising new direction. As the popular deep learning model nowadays, Transformer has excellent performance and has been used in EEG signal classification tasks. Therefore, in this study, we propose a deep learning model for SSVEP classification based on Transformer structure in inter-subject classification scenario, termed as SSVEPformer, which is the first application of the transformer to the classification of SSVEP. Inspired by previous studies, the model adopts the frequency spectrum of SSVEP data as input, and explores the spectral and spatial domain information for classification. Furthermore, to fully utilize the harmonic information, an extended SSVEPformer based on the filter bank technology (FB-SSVEPformer) is proposed to further improve the classification performance. Experiments were conducted using two open datasets (Dataset 1: 10 subjects, 12-class task; Dataset 2: 35 subjects, 40-class task) in the inter-subject classification scenario. The experimental results show that the proposed models could achieve better results in terms of classification accuracy and information transfer rate, compared with other baseline methods. The proposed model validates the feasibility of deep learning models based on Transformer structure for SSVEP classification task, and could serve as a potential model to alleviate the calibration procedure in the practical application of SSVEP-based BCI systems.
Cooperative Self-Training for Multi-Target Adaptive Semantic Segmentation
Oct 04, 2022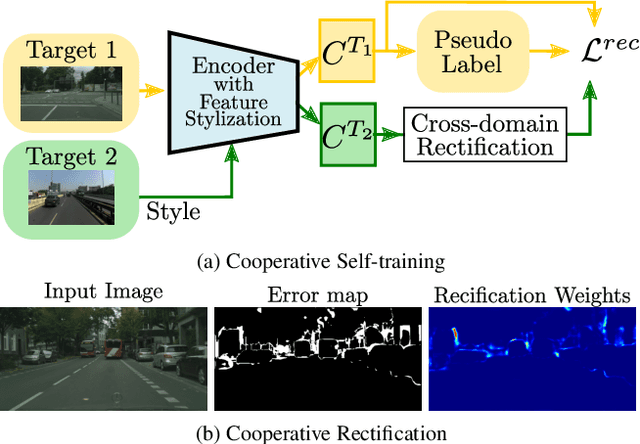

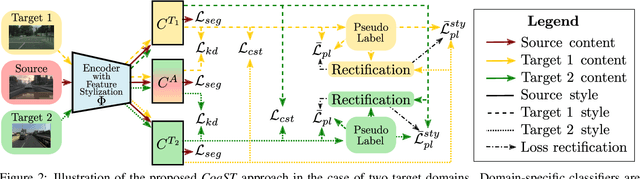

In this work we address multi-target domain adaptation (MTDA) in semantic segmentation, which consists in adapting a single model from an annotated source dataset to multiple unannotated target datasets that differ in their underlying data distributions. To address MTDA, we propose a self-training strategy that employs pseudo-labels to induce cooperation among multiple domain-specific classifiers. We employ feature stylization as an efficient way to generate image views that forms an integral part of self-training. Additionally, to prevent the network from overfitting to noisy pseudo-labels, we devise a rectification strategy that leverages the predictions from different classifiers to estimate the quality of pseudo-labels. Our extensive experiments on numerous settings, based on four different semantic segmentation datasets, validate the effectiveness of the proposed self-training strategy and show that our method outperforms state-of-the-art MTDA approaches. Code available at: https://github.com/Mael-zys/CoaST
Schizophrenia detection based on EEG using Recurrent Auto-Encoder framework
Jul 09, 2022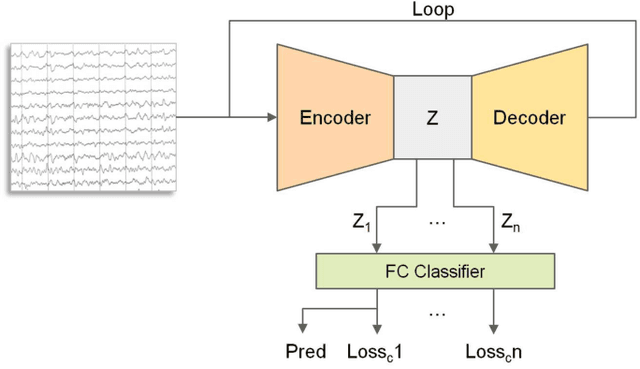
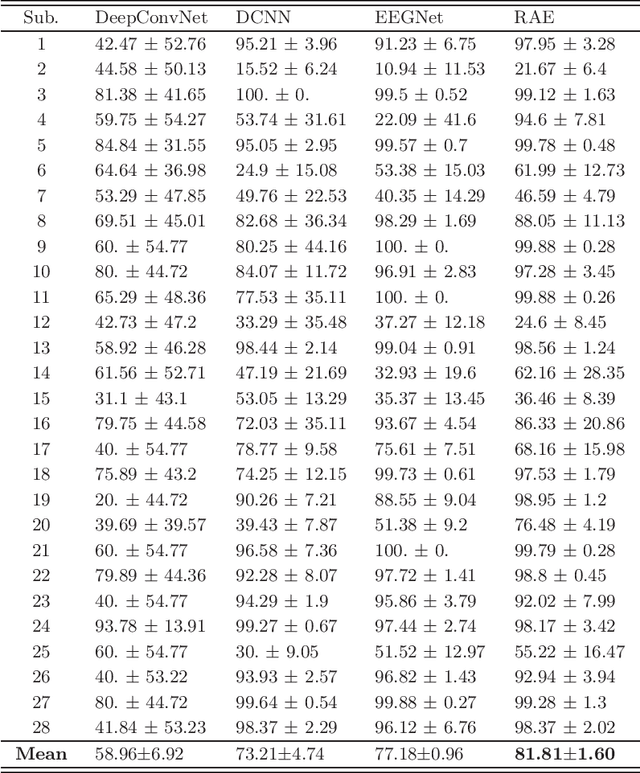
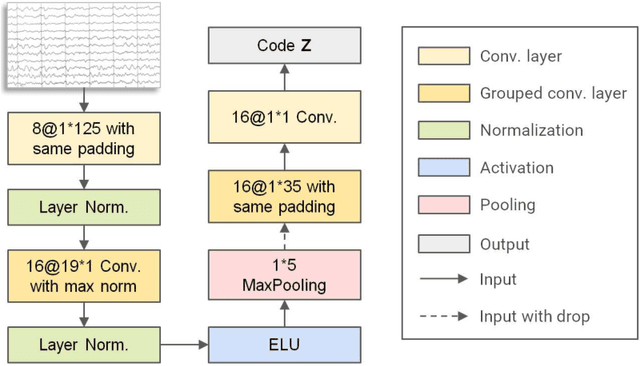
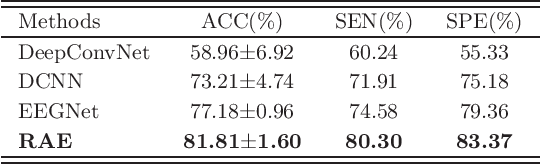
Schizophrenia (SZ) is a serious mental disorder that could seriously affect the patient's quality of life. In recent years, detection of SZ based on deep learning (DL) using electroencephalogram (EEG) has received increasing attention. In this paper, we proposed an end-to-end recurrent auto-encoder (RAE) model to detect SZ. In the RAE model, the raw data was input into one auto-encoder block, and the reconstructed data were recurrently input into the same block. The extracted code by auto-encoder block was simultaneously served as an input of a classifier block to discriminate SZ patients from healthy controls (HC). Evaluated on the dataset containing 14 SZ patients and 14 HC subjects, and the proposed method achieved an average classification accuracy of 81.81% in subject-independent experiment scenario. This study demonstrated that the structure of RAE is able to capture the differential features between SZ patients and HC subjects.
Towards a Fast Steady-State Visual Evoked Potentials Brain-Computer Interface
Feb 04, 2020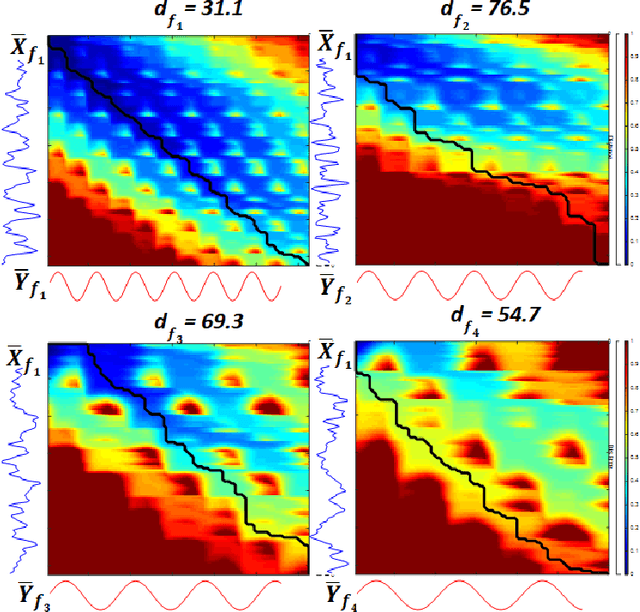
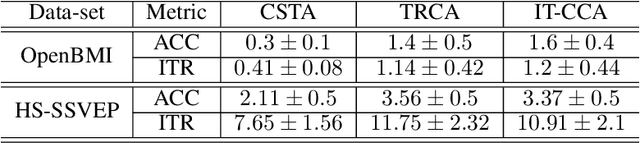
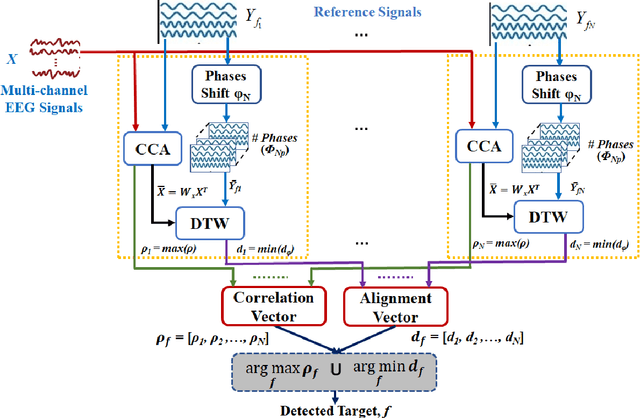
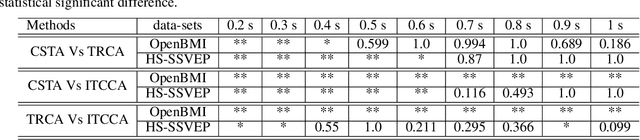
Steady-state visual evoked potentials (SSVEP) brain-computer interface (BCI) provides reliable responses leading to high accuracy and information throughput. But achieving high accuracy typically requires a relatively long time window of one second or more. Various methods were proposed to improve sub-second response accuracy through subject-specific training and calibration. Substantial performance improvements were achieved with tedious calibration and subject-specific training; resulting in the user's discomfort. So, we propose a training-free method by combining spatial-filtering and temporal alignment (CSTA) to recognize SSVEP responses in sub-second response time. CSTA exploits linear correlation and non-linear similarity between steady-state responses and stimulus templates with complementary fusion to achieve desirable performance improvements. We evaluated the performance of CSTA in terms of accuracy and Information Transfer Rate (ITR) in comparison with both training-based and training-free methods using two SSVEP data-sets. We observed that CSTA achieves the maximum mean accuracy of 97.43$\pm$2.26 % and 85.71$\pm$13.41 % with four-class and forty-class SSVEP data-sets respectively in sub-second response time in offline analysis. CSTA yields significantly higher mean performance (p<0.001) than the training-free method on both data-sets. Compared with training-based methods, CSTA shows 29.33$\pm$19.65 % higher mean accuracy with statistically significant differences in time window less than 0.5 s. In longer time windows, CSTA exhibits either better or comparable performance though not statistically significantly better than training-based methods. We show that the proposed method brings advantages of subject-independent SSVEP classification without requiring training while enabling high target recognition performance in sub-second response time.