 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhys-Diff: A Physics-Inspired Latent Diffusion Model for Tropical Cyclone Forecasting
Feb 28, 2026Tropical cyclone (TC) forecasting is critical for disaster warning and emergency response. Deep learning methods address computational challenges but often neglect physical relationships between TC attributes, resulting in predictions lacking physical consistency. To address this, we propose Phys-Diff, a physics-inspired latent diffusion model that disentangles latent features into task-specific components (trajectory, pressure, wind speed) and employs cross-task attention to introduce prior physics-inspired inductive biases, thereby embedding physically consistent dependencies among TC attributes. Phys-Diff integrates multimodal data including historical cyclone attributes, ERA5 reanalysis data, and FengWu forecast fields via a Transformer encoder-decoder architecture, further enhancing forecasting performance. Experiments demonstrate state-of-the-art performance on global and regional datasets.
TimeGMM: Single-Pass Probabilistic Forecasting via Adaptive Gaussian Mixture Models with Reversible Normalization
Jan 18, 2026Probabilistic time series forecasting is crucial for quantifying future uncertainty, with significant applications in fields such as energy and finance. However, existing methods often rely on computationally expensive sampling or restrictive parametric assumptions to characterize future distributions, which limits predictive performance and introduces distributional mismatch. To address these challenges, this paper presents TimeGMM, a novel probabilistic forecasting framework based on Gaussian Mixture Models (GMM) that captures complex future distributions in a single forward pass. A key component is GMM-adapted Reversible Instance Normalization (GRIN), a novel module designed to dynamically adapt to temporal-probabilistic distribution shifts. The framework integrates a dedicated Temporal Encoder (TE-Module) with a Conditional Temporal-Probabilistic Decoder (CTPD-Module) to jointly capture temporal dependencies and mixture distribution parameters. Extensive experiments demonstrate that TimeGMM consistently outperforms state-of-the-art methods, achieving maximum improvements of 22.48\% in CRPS and 21.23\% in NMAE.
Accelerating Data Generation for Nonlinear temporal PDEs via homologous perturbation in solution space
Oct 24, 2025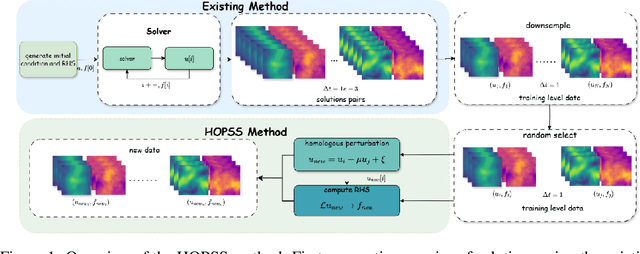
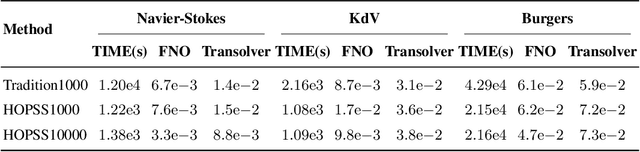
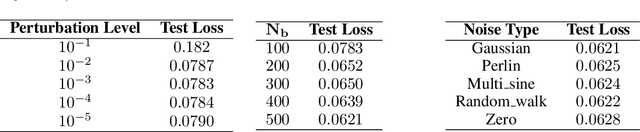
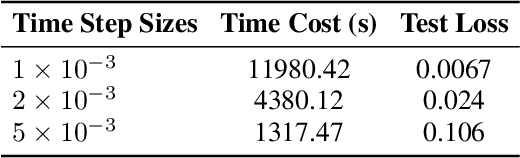
Data-driven deep learning methods like neural operators have advanced in solving nonlinear temporal partial differential equations (PDEs). However, these methods require large quantities of solution pairs\u2014the solution functions and right-hand sides (RHS) of the equations. These pairs are typically generated via traditional numerical methods, which need thousands of time steps iterations far more than the dozens required for training, creating heavy computational and temporal overheads. To address these challenges, we propose a novel data generation algorithm, called HOmologous Perturbation in Solution Space (HOPSS), which directly generates training datasets with fewer time steps rather than following the traditional approach of generating large time steps datasets. This algorithm simultaneously accelerates dataset generation and preserves the approximate precision required for model training. Specifically, we first obtain a set of base solution functions from a reliable solver, usually with thousands of time steps, and then align them in time steps with training datasets by downsampling. Subsequently, we propose a "homologous perturbation" approach: by combining two solution functions (one as the primary function, the other as a homologous perturbation term scaled by a small scalar) with random noise, we efficiently generate comparable-precision PDE data points. Finally, using these data points, we compute the variation in the original equation's RHS to form new solution pairs. Theoretical and experimental results show HOPSS lowers time complexity. For example, on the Navier-Stokes equation, it generates 10,000 samples in approximately 10% of traditional methods' time, with comparable model training performance.
Single Document Image Highlight Removal via A Large-Scale Real-World Dataset and A Location-Aware Network
Apr 19, 2025


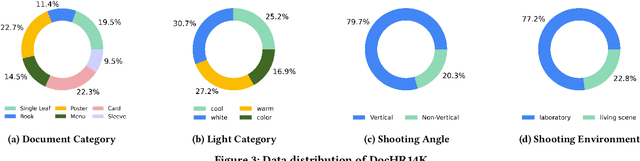
Reflective documents often suffer from specular highlights under ambient lighting, severely hindering text readability and degrading overall visual quality. Although recent deep learning methods show promise in highlight removal, they remain suboptimal for document images, primarily due to the lack of dedicated datasets and tailored architectural designs. To tackle these challenges, we present DocHR14K, a large-scale real-world dataset comprising 14,902 high-resolution image pairs across six document categories and various lighting conditions. To the best of our knowledge, this is the first high-resolution dataset for document highlight removal that captures a wide range of real-world lighting conditions. Additionally, motivated by the observation that the residual map between highlighted and clean images naturally reveals the spatial structure of highlight regions, we propose a simple yet effective Highlight Location Prior (HLP) to estimate highlight masks without human annotations. Building on this prior, we present the Location-Aware Laplacian Pyramid Highlight Removal Network (L2HRNet), which effectively removes highlights by leveraging estimated priors and incorporates diffusion module to restore details. Extensive experiments demonstrate that DocHR14K improves highlight removal under diverse lighting conditions. Our L2HRNet achieves state-of-the-art performance across three benchmark datasets, including a 5.01\% increase in PSNR and a 13.17\% reduction in RMSE on DocHR14K.
M3oE: Multi-Domain Multi-Task Mixture-of Experts Recommendation Framework
Apr 29, 2024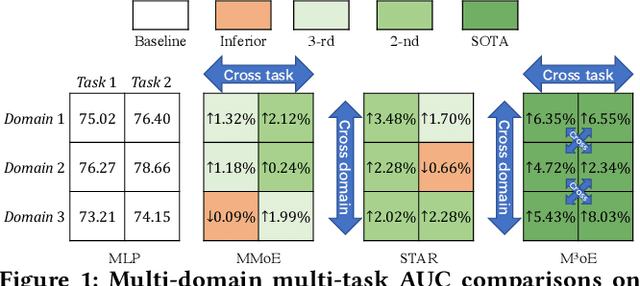
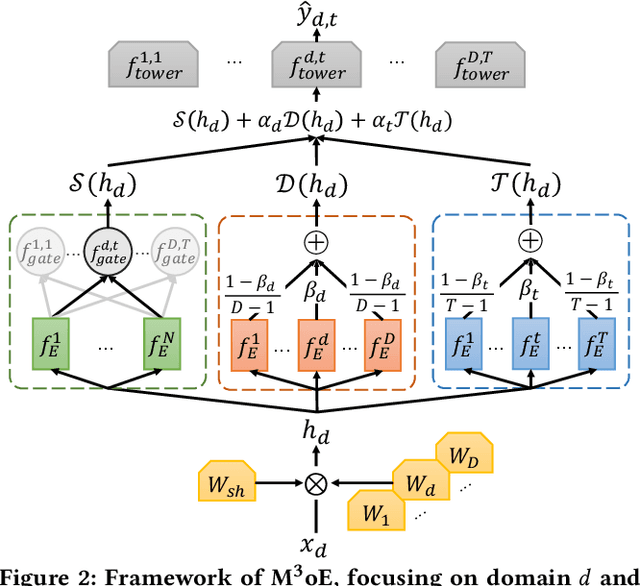
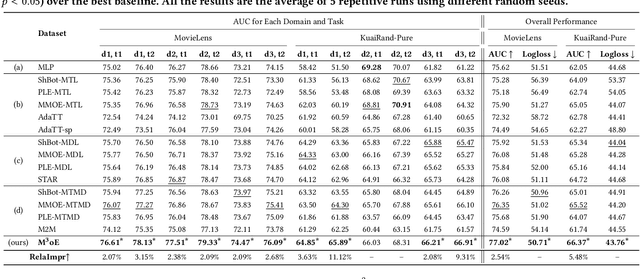
Multi-domain recommendation and multi-task recommendation have demonstrated their effectiveness in leveraging common information from different domains and objectives for comprehensive user modeling. Nonetheless, the practical recommendation usually faces multiple domains and tasks simultaneously, which cannot be well-addressed by current methods. To this end, we introduce M3oE, an adaptive multi-domain multi-task mixture-of-experts recommendation framework. M3oE integrates multi-domain information, maps knowledge across domains and tasks, and optimizes multiple objectives. We leverage three mixture-of-experts modules to learn common, domain-aspect, and task-aspect user preferences respectively to address the complex dependencies among multiple domains and tasks in a disentangled manner. Additionally, we design a two-level fusion mechanism for precise control over feature extraction and fusion across diverse domains and tasks. The framework's adaptability is further enhanced by applying AutoML technique, which allows dynamic structure optimization. To the best of the authors' knowledge, our M3oE is the first effort to solve multi-domain multi-task recommendation self-adaptively. Extensive experiments on two benchmark datasets against diverse baselines demonstrate M3oE's superior performance. The implementation code is available to ensure reproducibility.
MLPST: MLP is All You Need for Spatio-Temporal Prediction
Sep 23, 2023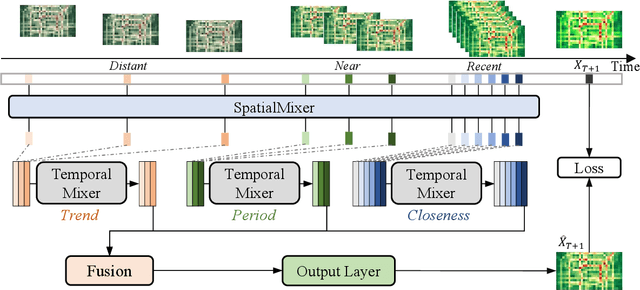
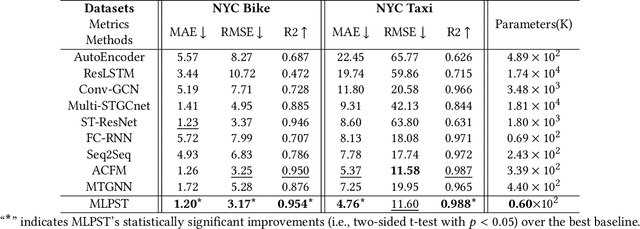
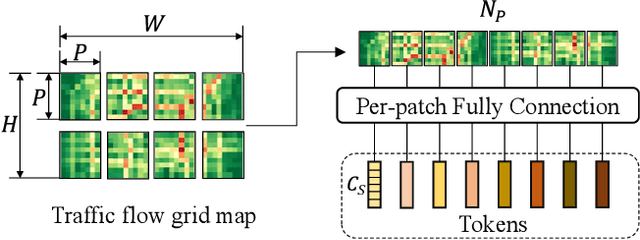
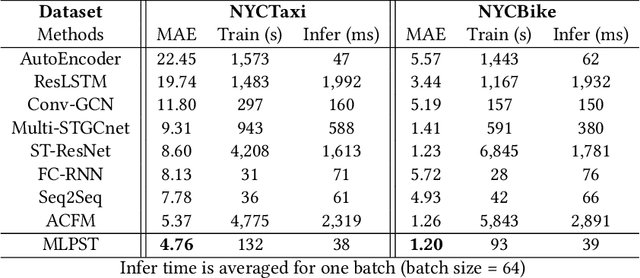
Traffic prediction is a typical spatio-temporal data mining task and has great significance to the public transportation system. Considering the demand for its grand application, we recognize key factors for an ideal spatio-temporal prediction method: efficient, lightweight, and effective. However, the current deep model-based spatio-temporal prediction solutions generally own intricate architectures with cumbersome optimization, which can hardly meet these expectations. To accomplish the above goals, we propose an intuitive and novel framework, MLPST, a pure multi-layer perceptron architecture for traffic prediction. Specifically, we first capture spatial relationships from both local and global receptive fields. Then, temporal dependencies in different intervals are comprehensively considered. Through compact and swift MLP processing, MLPST can well capture the spatial and temporal dependencies while requiring only linear computational complexity, as well as model parameters that are more than an order of magnitude lower than baselines. Extensive experiments validated the superior effectiveness and efficiency of MLPST against advanced baselines, and among models with optimal accuracy, MLPST achieves the best time and space efficiency.
Rethinking Sensors Modeling: Hierarchical Information Enhanced Traffic Forecasting
Sep 20, 2023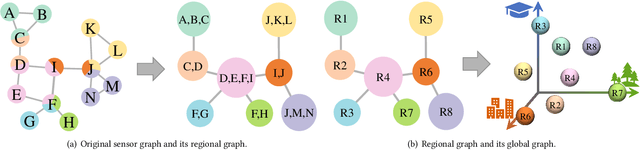

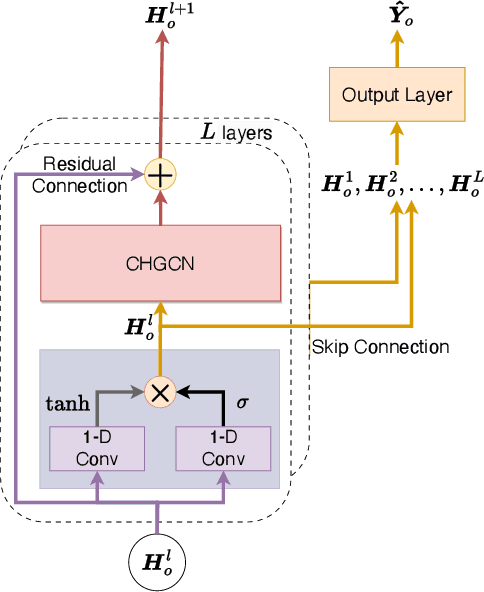
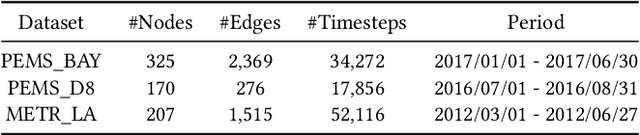
With the acceleration of urbanization, traffic forecasting has become an essential role in smart city construction. In the context of spatio-temporal prediction, the key lies in how to model the dependencies of sensors. However, existing works basically only consider the micro relationships between sensors, where the sensors are treated equally, and their macroscopic dependencies are neglected. In this paper, we argue to rethink the sensor's dependency modeling from two hierarchies: regional and global perspectives. Particularly, we merge original sensors with high intra-region correlation as a region node to preserve the inter-region dependency. Then, we generate representative and common spatio-temporal patterns as global nodes to reflect a global dependency between sensors and provide auxiliary information for spatio-temporal dependency learning. In pursuit of the generality and reality of node representations, we incorporate a Meta GCN to calibrate the regional and global nodes in the physical data space. Furthermore, we devise the cross-hierarchy graph convolution to propagate information from different hierarchies. In a nutshell, we propose a Hierarchical Information Enhanced Spatio-Temporal prediction method, HIEST, to create and utilize the regional dependency and common spatio-temporal patterns. Extensive experiments have verified the leading performance of our HIEST against state-of-the-art baselines. We publicize the code to ease reproducibility.
PromptST: Prompt-Enhanced Spatio-Temporal Multi-Attribute Prediction
Sep 18, 2023In the era of information explosion, spatio-temporal data mining serves as a critical part of urban management. Considering the various fields demanding attention, e.g., traffic state, human activity, and social event, predicting multiple spatio-temporal attributes simultaneously can alleviate regulatory pressure and foster smart city construction. However, current research can not handle the spatio-temporal multi-attribute prediction well due to the complex relationships between diverse attributes. The key challenge lies in how to address the common spatio-temporal patterns while tackling their distinctions. In this paper, we propose an effective solution for spatio-temporal multi-attribute prediction, PromptST. We devise a spatio-temporal transformer and a parameter-sharing training scheme to address the common knowledge among different spatio-temporal attributes. Then, we elaborate a spatio-temporal prompt tuning strategy to fit the specific attributes in a lightweight manner. Through the pretrain and prompt tuning phases, our PromptST is able to enhance the specific spatio-temoral characteristic capture by prompting the backbone model to fit the specific target attribute while maintaining the learned common knowledge. Extensive experiments on real-world datasets verify that our PromptST attains state-of-the-art performance. Furthermore, we also prove PromptST owns good transferability on unseen spatio-temporal attributes, which brings promising application potential in urban computing. The implementation code is available to ease reproducibility.
AutoSTL: Automated Spatio-Temporal Multi-Task Learning
Apr 16, 2023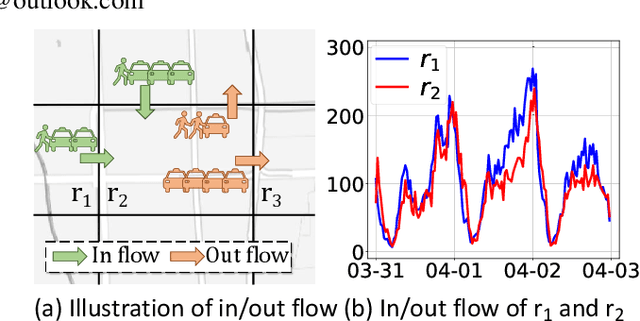
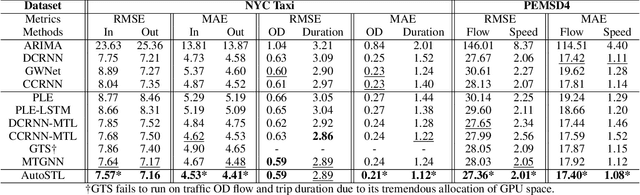
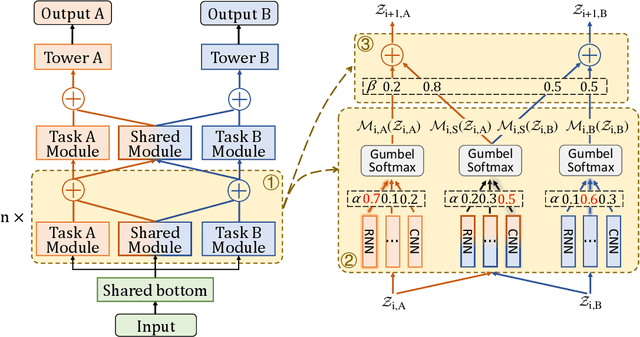
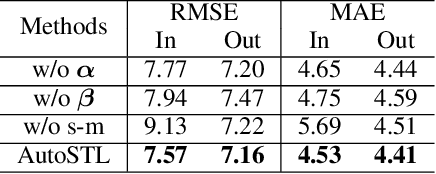
Spatio-Temporal prediction plays a critical role in smart city construction. Jointly modeling multiple spatio-temporal tasks can further promote an intelligent city life by integrating their inseparable relationship. However, existing studies fail to address this joint learning problem well, which generally solve tasks individually or a fixed task combination. The challenges lie in the tangled relation between different properties, the demand for supporting flexible combinations of tasks and the complex spatio-temporal dependency. To cope with the problems above, we propose an Automated Spatio-Temporal multi-task Learning (AutoSTL) method to handle multiple spatio-temporal tasks jointly. Firstly, we propose a scalable architecture consisting of advanced spatio-temporal operations to exploit the complicated dependency. Shared modules and feature fusion mechanism are incorporated to further capture the intrinsic relationship between tasks. Furthermore, our model automatically allocates the operations and fusion weight. Extensive experiments on benchmark datasets verified that our model achieves state-of-the-art performance. As we can know, AutoSTL is the first automated spatio-temporal multi-task learning method.
T2M-GPT: Generating Human Motion from Textual Descriptions with Discrete Representations
Jan 18, 2023



In this work, we investigate a simple and must-known conditional generative framework based on Vector Quantised-Variational AutoEncoder (VQ-VAE) and Generative Pre-trained Transformer (GPT) for human motion generation from textural descriptions. We show that a simple CNN-based VQ-VAE with commonly used training recipes (EMA and Code Reset) allows us to obtain high-quality discrete representations. For GPT, we incorporate a simple corruption strategy during the training to alleviate training-testing discrepancy. Despite its simplicity, our T2M-GPT shows better performance than competitive approaches, including recent diffusion-based approaches. For example, on HumanML3D, which is currently the largest dataset, we achieve comparable performance on the consistency between text and generated motion (R-Precision), but with FID 0.116 largely outperforming MotionDiffuse of 0.630. Additionally, we conduct analyses on HumanML3D and observe that the dataset size is a limitation of our approach. Our work suggests that VQ-VAE still remains a competitive approach for human motion generation.