 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Gated Deformable Network for Breast Tumor Segmentation in MR Images
Sep 19, 2025



Accurate segmentation of breast tumors in magnetic resonance images (MRI) is essential for breast cancer diagnosis, yet existing methods face challenges in capturing irregular tumor shapes and effectively integrating local and global features. To address these limitations, we propose an uncertainty-gated deformable network to leverage the complementary information from CNN and Transformers. Specifically, we incorporates deformable feature modeling into both convolution and attention modules, enabling adaptive receptive fields for irregular tumor contours. We also design an Uncertainty-Gated Enhancing Module (U-GEM) to selectively exchange complementary features between CNN and Transformer based on pixel-wise uncertainty, enhancing both local and global representations. Additionally, a Boundary-sensitive Deep Supervision Loss is introduced to further improve tumor boundary delineation. Comprehensive experiments on two clinical breast MRI datasets demonstrate that our method achieves superior segmentation performance compared with state-of-the-art methods, highlighting its clinical potential for accurate breast tumor delineation.
Tailored Multi-Organ Segmentation with Model Adaptation and Ensemble
Apr 14, 2023



Multi-organ segmentation, which identifies and separates different organs in medical images, is a fundamental task in medical image analysis. Recently, the immense success of deep learning motivated its wide adoption in multi-organ segmentation tasks. However, due to expensive labor costs and expertise, the availability of multi-organ annotations is usually limited and hence poses a challenge in obtaining sufficient training data for deep learning-based methods. In this paper, we aim to address this issue by combining off-the-shelf single-organ segmentation models to develop a multi-organ segmentation model on the target dataset, which helps get rid of the dependence on annotated data for multi-organ segmentation. To this end, we propose a novel dual-stage method that consists of a Model Adaptation stage and a Model Ensemble stage. The first stage enhances the generalization of each off-the-shelf segmentation model on the target domain, while the second stage distills and integrates knowledge from multiple adapted single-organ segmentation models. Extensive experiments on four abdomen datasets demonstrate that our proposed method can effectively leverage off-the-shelf single-organ segmentation models to obtain a tailored model for multi-organ segmentation with high accuracy.
Unified Multi-Modal Image Synthesis for Missing Modality Imputation
Apr 11, 2023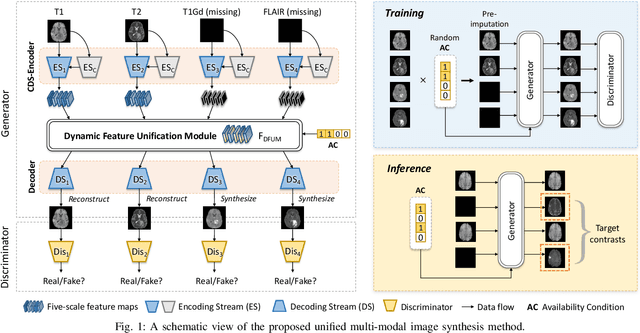


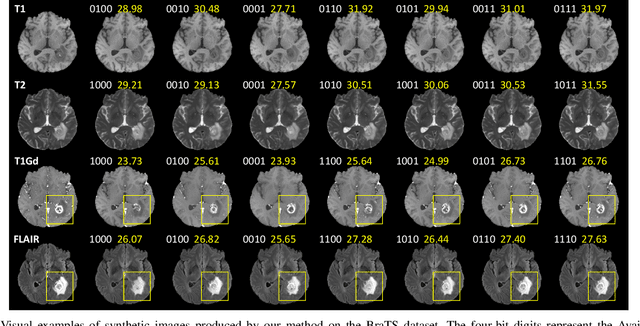
Multi-modal medical images provide complementary soft-tissue characteristics that aid in the screening and diagnosis of diseases. However, limited scanning time, image corruption and various imaging protocols often result in incomplete multi-modal images, thus limiting the usage of multi-modal data for clinical purposes. To address this issue, in this paper, we propose a novel unified multi-modal image synthesis method for missing modality imputation. Our method overall takes a generative adversarial architecture, which aims to synthesize missing modalities from any combination of available ones with a single model. To this end, we specifically design a Commonality- and Discrepancy-Sensitive Encoder for the generator to exploit both modality-invariant and specific information contained in input modalities. The incorporation of both types of information facilitates the generation of images with consistent anatomy and realistic details of the desired distribution. Besides, we propose a Dynamic Feature Unification Module to integrate information from a varying number of available modalities, which enables the network to be robust to random missing modalities. The module performs both hard integration and soft integration, ensuring the effectiveness of feature combination while avoiding information loss. Verified on two public multi-modal magnetic resonance datasets, the proposed method is effective in handling various synthesis tasks and shows superior performance compared to previous methods.
Multi-phase Liver Tumor Segmentation with Spatial Aggregation and Uncertain Region Inpainting
Aug 05, 2021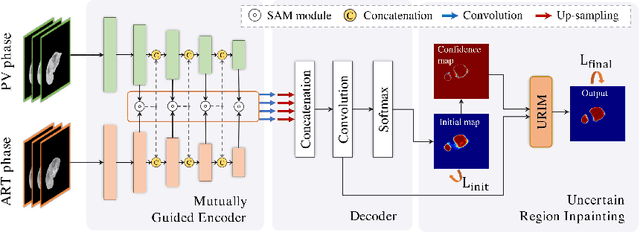
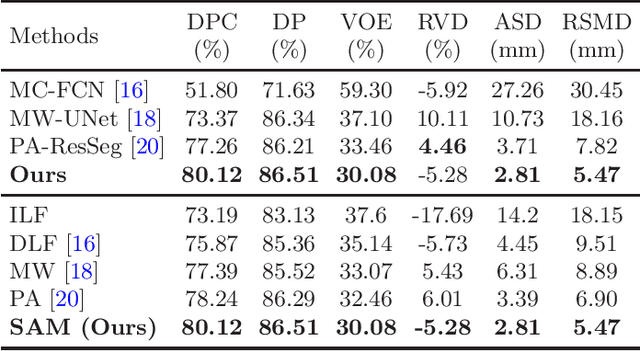
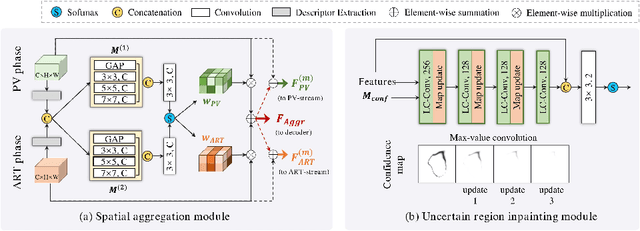
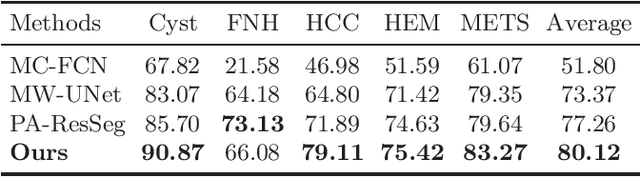
Multi-phase computed tomography (CT) images provide crucial complementary information for accurate liver tumor segmentation (LiTS). State-of-the-art multi-phase LiTS methods usually fused cross-phase features through phase-weighted summation or channel-attention based concatenation. However, these methods ignored the spatial (pixel-wise) relationships between different phases, hence leading to insufficient feature integration. In addition, the performance of existing methods remains subject to the uncertainty in segmentation, which is particularly acute in tumor boundary regions. In this work, we propose a novel LiTS method to adequately aggregate multi-phase information and refine uncertain region segmentation. To this end, we introduce a spatial aggregation module (SAM), which encourages per-pixel interactions between different phases, to make full use of cross-phase information. Moreover, we devise an uncertain region inpainting module (URIM) to refine uncertain pixels using neighboring discriminative features. Experiments on an in-house multi-phase CT dataset of focal liver lesions (MPCT-FLLs) demonstrate that our method achieves promising liver tumor segmentation and outperforms state-of-the-arts.
DuCN: Dual-children Network for Medical Diagnosis and Similar Case Recommendation towards COVID-19
Aug 03, 2021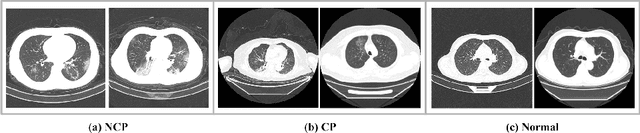

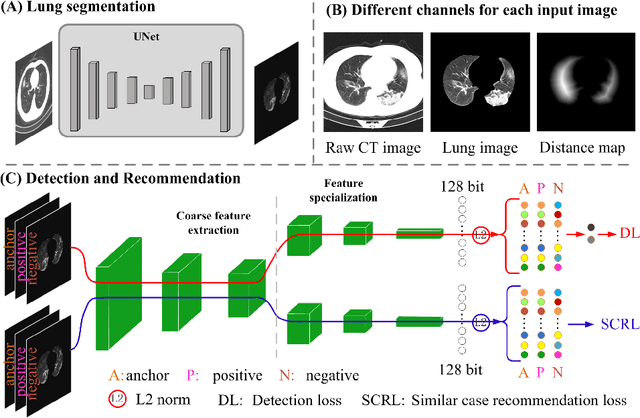

Early detection of the coronavirus disease 2019 (COVID-19) helps to treat patients timely and increase the cure rate, thus further suppressing the spread of the disease. In this study, we propose a novel deep learning based detection and similar case recommendation network to help control the epidemic. Our proposed network contains two stages: the first one is a lung region segmentation step and is used to exclude irrelevant factors, and the second is a detection and recommendation stage. Under this framework, in the second stage, we develop a dual-children network (DuCN) based on a pre-trained ResNet-18 to simultaneously realize the disease diagnosis and similar case recommendation. Besides, we employ triplet loss and intrapulmonary distance maps to assist the detection, which helps incorporate tiny differences between two images and is conducive to improving the diagnostic accuracy. For each confirmed COVID-19 case, we give similar cases to provide radiologists with diagnosis and treatment references. We conduct experiments on a large publicly available dataset (CC-CCII) and compare the proposed model with state-of-the-art COVID-19 detection methods. The results show that our proposed model achieves a promising clinical performance.
W-net: Simultaneous segmentation of multi-anatomical retinal structures using a multi-task deep neural network
Jun 11, 2020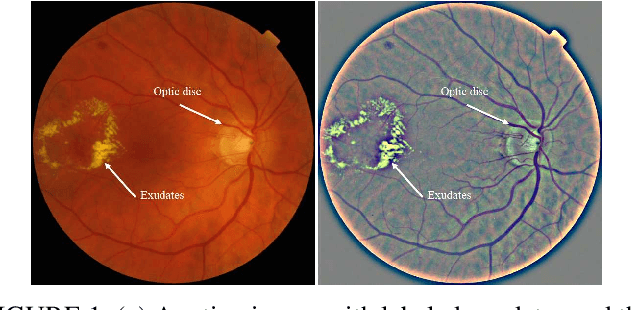
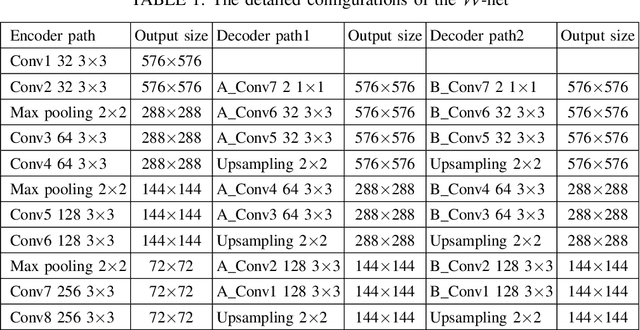
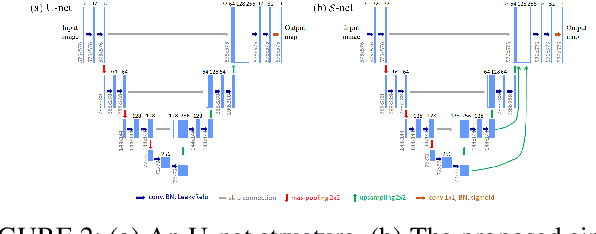

Segmentation of multiple anatomical structures is of great importance in medical image analysis. In this study, we proposed a $\mathcal{W}$-net to simultaneously segment both the optic disc (OD) and the exudates in retinal images based on the multi-task learning (MTL) scheme. We introduced a class-balanced loss and a multi-task weighted loss to alleviate the imbalanced problem and to improve the robustness and generalization property of the $\mathcal{W}$-net. We demonstrated the effectiveness of our approach by applying five-fold cross-validation experiments on two public datasets e\_ophtha\_EX and DiaRetDb1. We achieved F1-score of 94.76\% and 95.73\% for OD segmentation, and 92.80\% and 94.14\% for exudates segmentation. To further prove the generalization property of the proposed method, we applied the trained model on the DRIONS-DB dataset for OD segmentation and on the MESSIDOR dataset for exudate segmentation. Our results demonstrated that by choosing the optimal weights of each task, the MTL based $\mathcal{W}$-net outperformed separate models trained individually on each task. Code and pre-trained models will be available at: \url{https://github.com/FundusResearch/MTL_for_OD_and_exudates.git}.