 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Document Image Highlight Removal via A Large-Scale Real-World Dataset and A Location-Aware Network
Apr 19, 2025


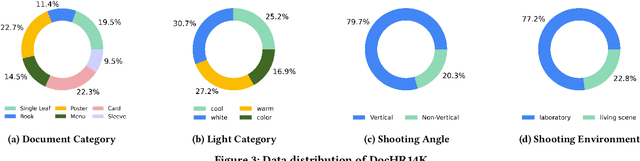
Reflective documents often suffer from specular highlights under ambient lighting, severely hindering text readability and degrading overall visual quality. Although recent deep learning methods show promise in highlight removal, they remain suboptimal for document images, primarily due to the lack of dedicated datasets and tailored architectural designs. To tackle these challenges, we present DocHR14K, a large-scale real-world dataset comprising 14,902 high-resolution image pairs across six document categories and various lighting conditions. To the best of our knowledge, this is the first high-resolution dataset for document highlight removal that captures a wide range of real-world lighting conditions. Additionally, motivated by the observation that the residual map between highlighted and clean images naturally reveals the spatial structure of highlight regions, we propose a simple yet effective Highlight Location Prior (HLP) to estimate highlight masks without human annotations. Building on this prior, we present the Location-Aware Laplacian Pyramid Highlight Removal Network (L2HRNet), which effectively removes highlights by leveraging estimated priors and incorporates diffusion module to restore details. Extensive experiments demonstrate that DocHR14K improves highlight removal under diverse lighting conditions. Our L2HRNet achieves state-of-the-art performance across three benchmark datasets, including a 5.01\% increase in PSNR and a 13.17\% reduction in RMSE on DocHR14K.
Simple or Complex? Complexity-Controllable Question Generation with Soft Templates and Deep Mixture of Experts Model
Oct 13, 2021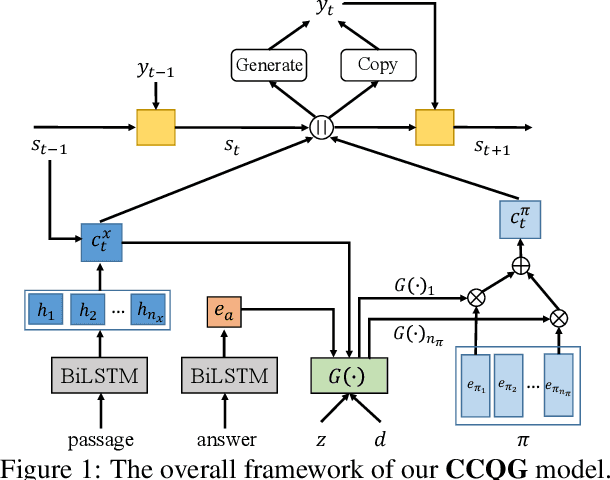
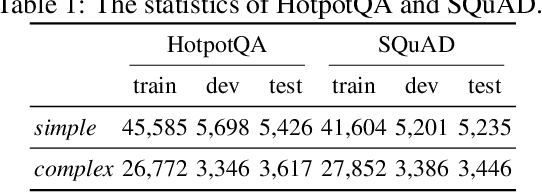
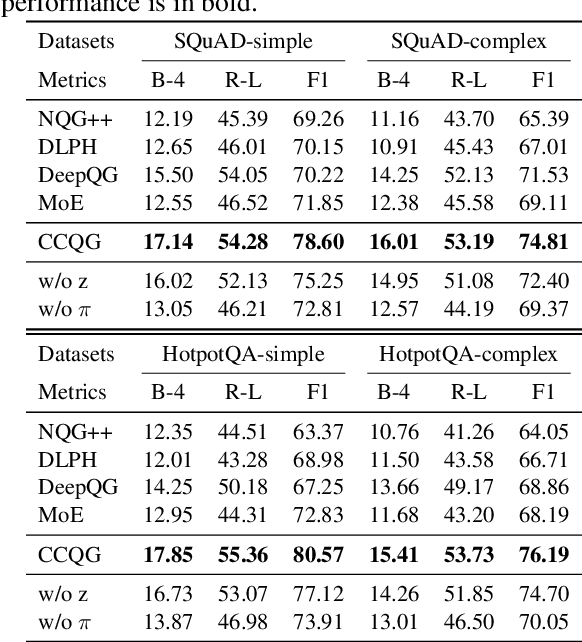
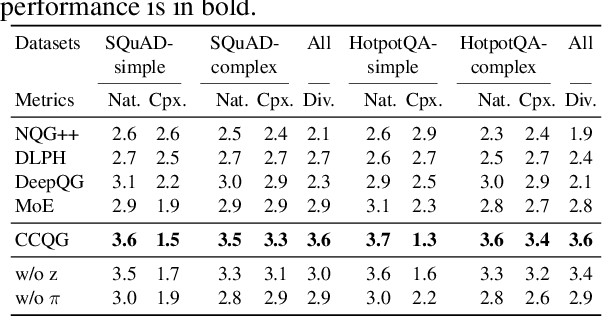
The ability to generate natural-language questions with controlled complexity levels is highly desirable as it further expands the applicability of question generation. In this paper, we propose an end-to-end neural complexity-controllable question generation model, which incorporates a mixture of experts (MoE) as the selector of soft templates to improve the accuracy of complexity control and the quality of generated questions. The soft templates capture question similarity while avoiding the expensive construction of actual templates. Our method introduces a novel, cross-domain complexity estimator to assess the complexity of a question, taking into account the passage, the question, the answer and their interactions. The experimental results on two benchmark QA datasets demonstrate that our QG model is superior to state-of-the-art methods in both automatic and manual evaluation. Moreover, our complexity estimator is significantly more accurate than the baselines in both in-domain and out-domain settings.
Generating Pertinent and Diversified Comments with Topic-aware Pointer-Generator Networks
May 09, 2020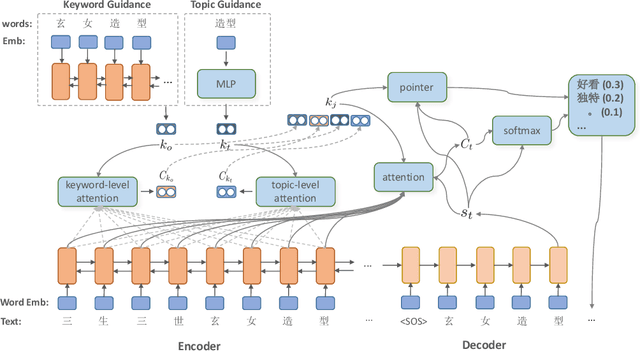

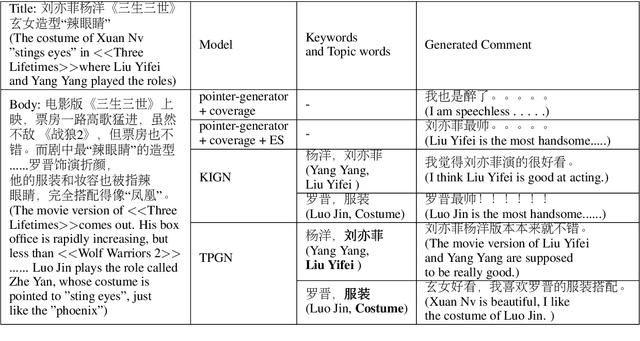
Comment generation, a new and challenging task in Natural Language Generation (NLG), attracts a lot of attention in recent years. However, comments generated by previous work tend to lack pertinence and diversity. In this paper, we propose a novel generation model based on Topic-aware Pointer-Generator Networks (TPGN), which can utilize the topic information hidden in the articles to guide the generation of pertinent and diversified comments. Firstly, we design a keyword-level and topic-level encoder attention mechanism to capture topic information in the articles. Next, we integrate the topic information into pointer-generator networks to guide comment generation. Experiments on a large scale of comment generation dataset show that our model produces the valuable comments and outperforms competitive baseline models significantly.