 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple or Complex? Complexity-Controllable Question Generation with Soft Templates and Deep Mixture of Experts Model
Oct 13, 2021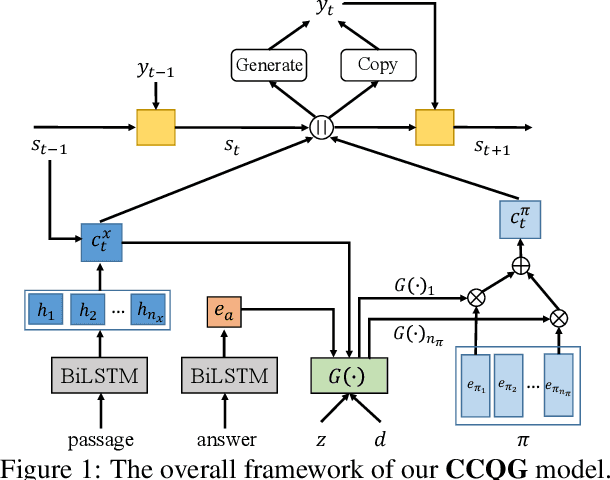
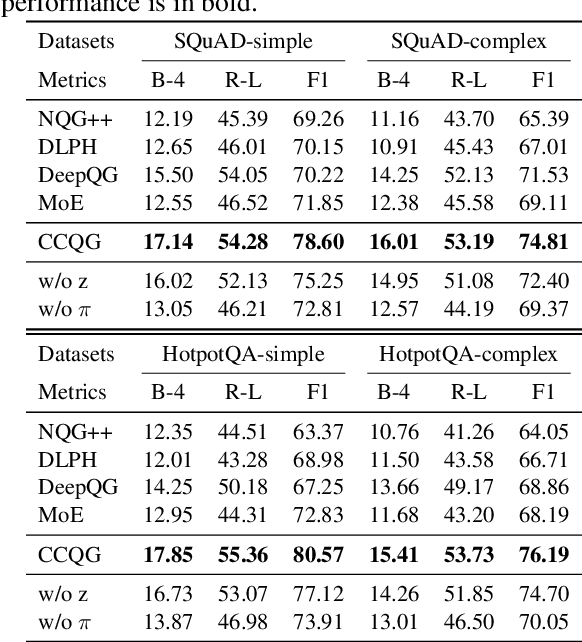
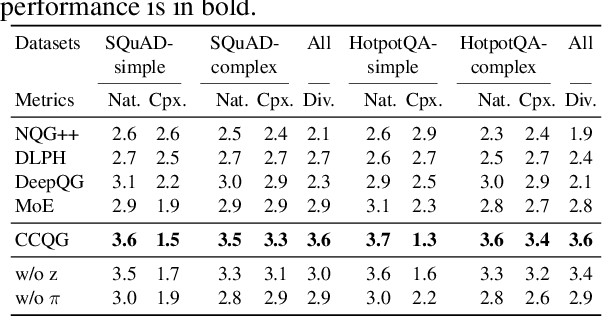
The ability to generate natural-language questions with controlled complexity levels is highly desirable as it further expands the applicability of question generation. In this paper, we propose an end-to-end neural complexity-controllable question generation model, which incorporates a mixture of experts (MoE) as the selector of soft templates to improve the accuracy of complexity control and the quality of generated questions. The soft templates capture question similarity while avoiding the expensive construction of actual templates. Our method introduces a novel, cross-domain complexity estimator to assess the complexity of a question, taking into account the passage, the question, the answer and their interactions. The experimental results on two benchmark QA datasets demonstrate that our QG model is superior to state-of-the-art methods in both automatic and manual evaluation. Moreover, our complexity estimator is significantly more accurate than the baselines in both in-domain and out-domain settings.
Knowledge-enriched, Type-constrained and Grammar-guided Question Generation over Knowledge Bases
Oct 23, 2020
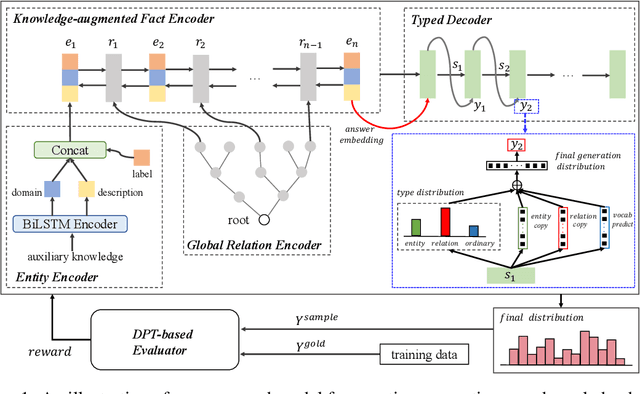
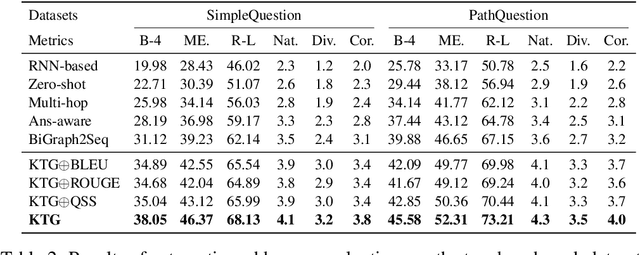
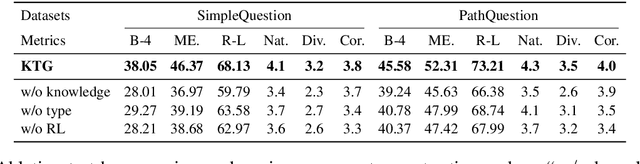
Question generation over knowledge bases (KBQG) aims at generating natural-language questions about a subgraph, i.e. a set of (connected) triples. Two main challenges still face the current crop of encoder-decoder-based methods, especially on small subgraphs: (1) low diversity and poor fluency due to the limited information contained in the subgraphs, and (2) semantic drift due to the decoder's oblivion of the semantics of the answer entity. We propose an innovative knowledge-enriched, type-constrained and grammar-guided KBQG model, named KTG, to addresses the above challenges. In our model, the encoder is equipped with auxiliary information from the KB, and the decoder is constrained with word types during QG. Specifically, entity domain and description, as well as relation hierarchy information are considered to construct question contexts, while a conditional copy mechanism is incorporated to modulate question semantics according to current word types. Besides, a novel reward function featuring grammatical similarity is designed to improve both generative richness and syntactic correctness via reinforcement learning. Extensive experiments show that our proposed model outperforms existing methods by a significant margin on two widely-used benchmark datasets SimpleQuestion and PathQuestion.
Knowledge-aware Method for Confusing Charge Prediction
Oct 07, 2020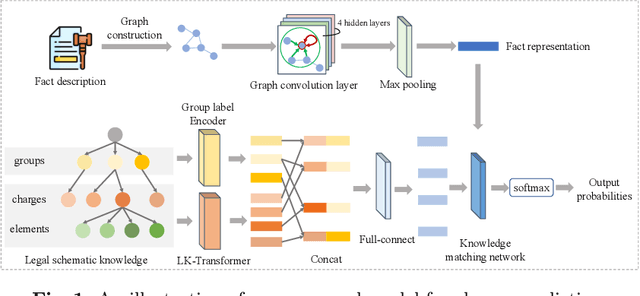
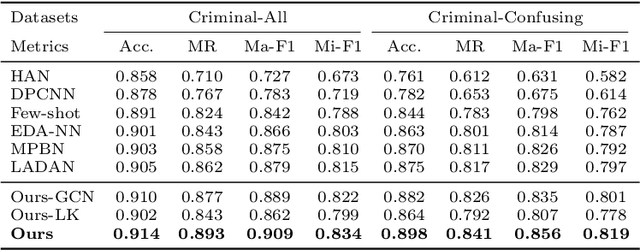
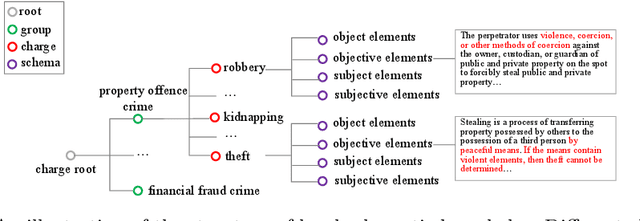

Automatic charge prediction task aims to determine the final charges based on fact descriptions of criminal cases, which is a vital application of legal assistant systems. Conventional works usually depend on fact descriptions to predict charges while ignoring the legal schematic knowledge, which makes it difficult to distinguish confusing charges. In this paper, we propose a knowledge-attentive neural network model, which introduces legal schematic knowledge about charges and exploit the knowledge hierarchical representation as the discriminative features to differentiate confusing charges. Our model takes the textual fact description as the input and learns fact representation through a graph convolutional network. A legal schematic knowledge transformer is utilized to generate crucial knowledge representations oriented to the legal schematic knowledge at both the schema and charge levels. We apply a knowledge matching network for effectively incorporating charge information into the fact to learn knowledge-aware fact representation. Finally, we use the knowledge-aware fact representation for charge prediction. We create two real-world datasets and experimental results show that our proposed model can outperform other state-of-the-art baselines on accuracy and F1 score, especially on dealing with confusing charges.