 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Fine-Grained Grounded Citations for Attributed Large Language Models
Aug 08, 2024Despite the impressive performance on information-seeking tasks, large language models (LLMs) still struggle with hallucinations. Attributed LLMs, which augment generated text with in-line citations, have shown potential in mitigating hallucinations and improving verifiability. However, current approaches suffer from suboptimal citation quality due to their reliance on in-context learning. Furthermore, the practice of citing only coarse document identifiers makes it challenging for users to perform fine-grained verification. In this work, we introduce FRONT, a training framework designed to teach LLMs to generate Fine-Grained Grounded Citations. By grounding model outputs in fine-grained supporting quotes, these quotes guide the generation of grounded and consistent responses, not only improving citation quality but also facilitating fine-grained verification. Experiments on the ALCE benchmark demonstrate the efficacy of FRONT in generating superior grounded responses and highly supportive citations. With LLaMA-2-7B, the framework significantly outperforms all the baselines, achieving an average of 14.21% improvement in citation quality across all datasets, even surpassing ChatGPT.
Trends in Integration of Knowledge and Large Language Models: A Survey and Taxonomy of Methods, Benchmarks, and Applications
Nov 10, 2023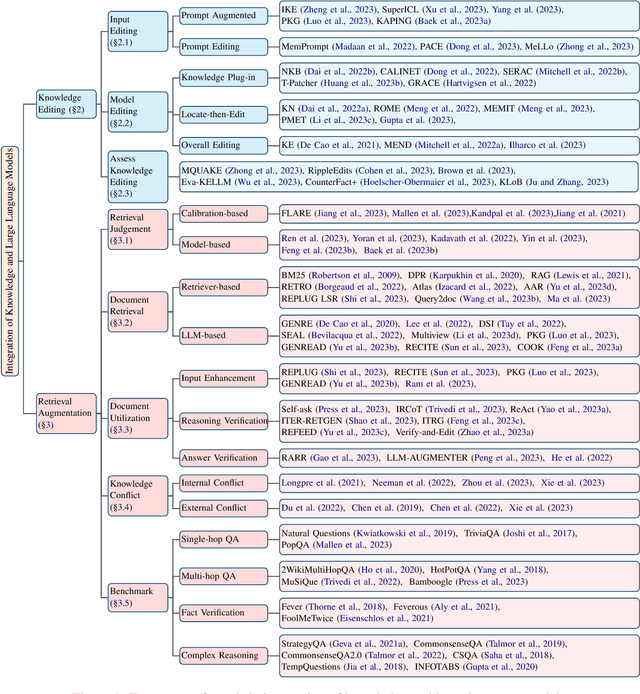
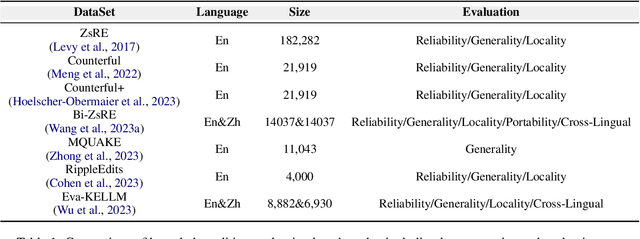
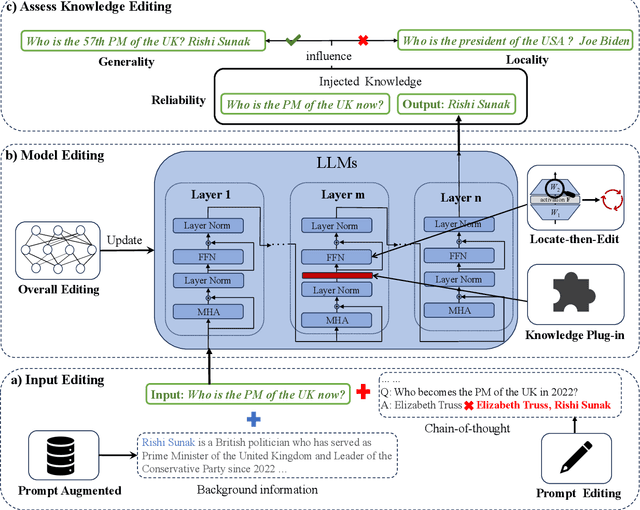
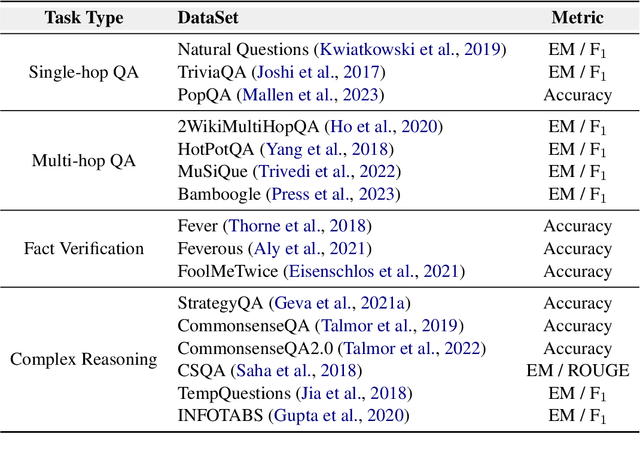
Large language models (LLMs) exhibit superior performance on various natural language tasks, but they are susceptible to issues stemming from outdated data and domain-specific limitations. In order to address these challenges, researchers have pursued two primary strategies, knowledge editing and retrieval augmentation, to enhance LLMs by incorporating external information from different aspects. Nevertheless, there is still a notable absence of a comprehensive survey. In this paper, we propose a review to discuss the trends in integration of knowledge and large language models, including taxonomy of methods, benchmarks, and applications. In addition, we conduct an in-depth analysis of different methods and point out potential research directions in the future. We hope this survey offers the community quick access and a comprehensive overview of this research area, with the intention of inspiring future research endeavors.
A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions
Nov 09, 2023The emergence of large language models (LLMs) has marked a significant breakthrough in natural language processing (NLP), leading to remarkable advancements in text understanding and generation. Nevertheless, alongside these strides, LLMs exhibit a critical tendency to produce hallucinations, resulting in content that is inconsistent with real-world facts or user inputs. This phenomenon poses substantial challenges to their practical deployment and raises concerns over the reliability of LLMs in real-world scenarios, which attracts increasing attention to detect and mitigate these hallucinations. In this survey, we aim to provide a thorough and in-depth overview of recent advances in the field of LLM hallucinations. We begin with an innovative taxonomy of LLM hallucinations, then delve into the factors contributing to hallucinations. Subsequently, we present a comprehensive overview of hallucination detection methods and benchmarks. Additionally, representative approaches designed to mitigate hallucinations are introduced accordingly. Finally, we analyze the challenges that highlight the current limitations and formulate open questions, aiming to delineate pathways for future research on hallucinations in LLMs.
A Survey of Chain of Thought Reasoning: Advances, Frontiers and Future
Sep 27, 2023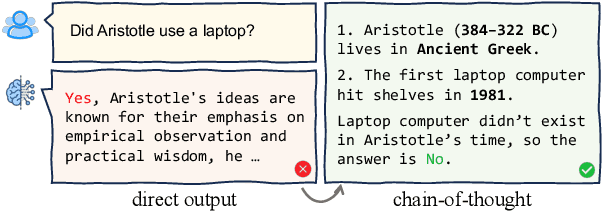
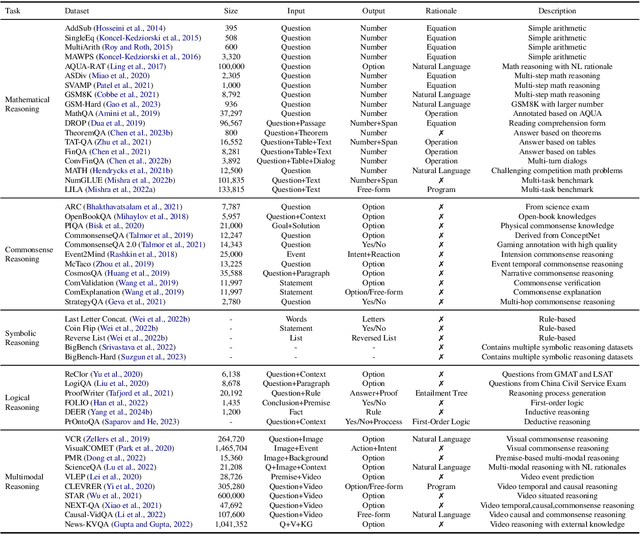
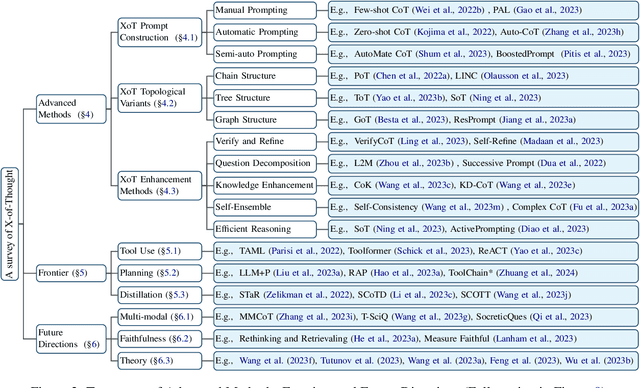
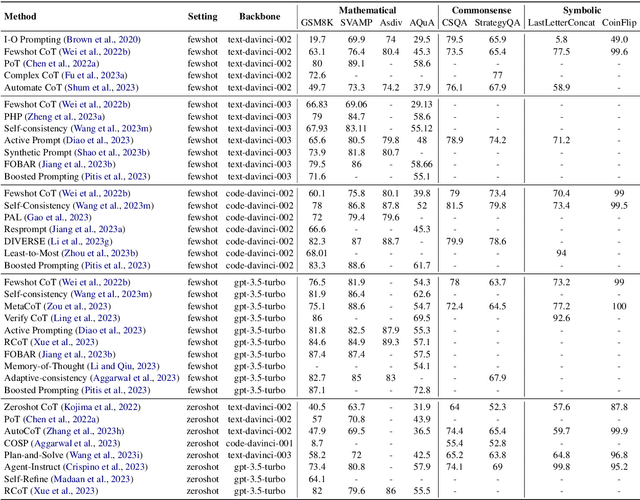
Chain-of-thought reasoning, a cognitive process fundamental to human intelligence, has garnered significant attention in the realm of artificial intelligence and natural language processing. However, there still remains a lack of a comprehensive survey for this arena. To this end, we take the first step and present a thorough survey of this research field carefully and widely. We use X-of-Thought to refer to Chain-of-Thought in a broad sense. In detail, we systematically organize the current research according to the taxonomies of methods, including XoT construction, XoT structure variants, and enhanced XoT. Additionally, we describe XoT with frontier applications, covering planning, tool use, and distillation. Furthermore, we address challenges and discuss some future directions, including faithfulness, multi-modal, and theory. We hope this survey serves as a valuable resource for researchers seeking to innovate within the domain of chain-of-thought reasoning.
HiSMatch: Historical Structure Matching based Temporal Knowledge Graph Reasoning
Oct 18, 2022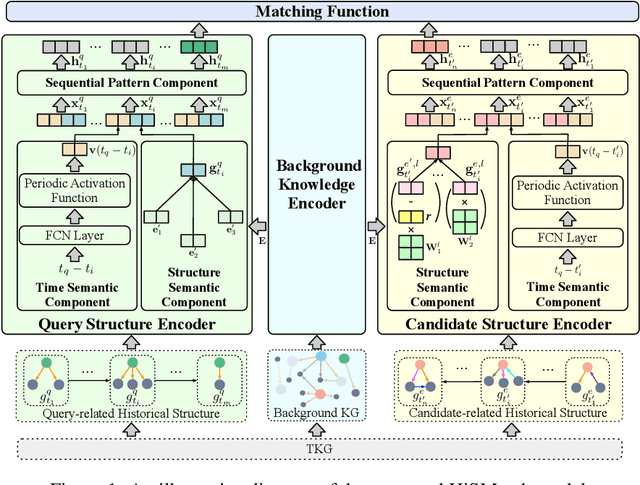
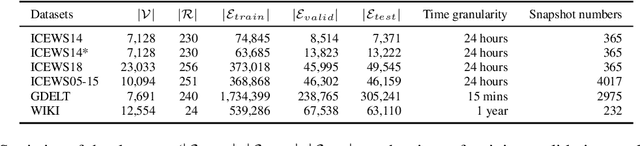
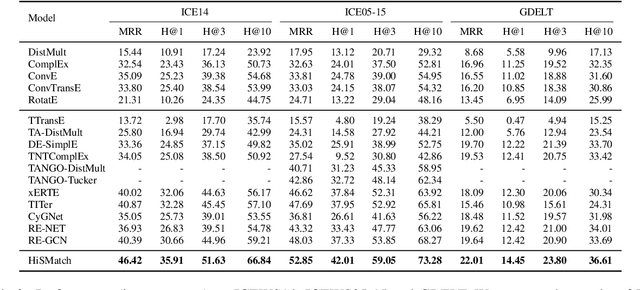
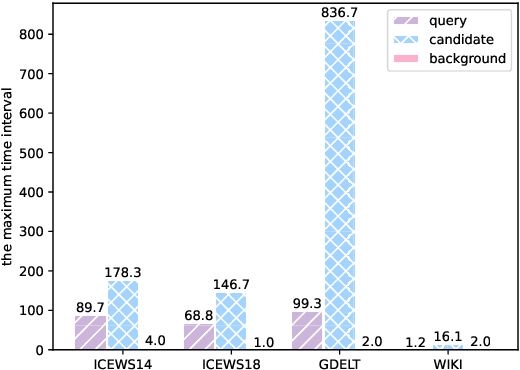
A Temporal Knowledge Graph (TKG) is a sequence of KGs with respective timestamps, which adopts quadruples in the form of (\emph{subject}, \emph{relation}, \emph{object}, \emph{timestamp}) to describe dynamic facts. TKG reasoning has facilitated many real-world applications via answering such queries as (\emph{query entity}, \emph{query relation}, \emph{?}, \emph{future timestamp}) about future. This is actually a matching task between a query and candidate entities based on their historical structures, which reflect behavioral trends of the entities at different timestamps. In addition, recent KGs provide background knowledge of all the entities, which is also helpful for the matching. Thus, in this paper, we propose the \textbf{Hi}storical \textbf{S}tructure \textbf{Match}ing (\textbf{HiSMatch}) model. It applies two structure encoders to capture the semantic information contained in the historical structures of the query and candidate entities. Besides, it adopts another encoder to integrate the background knowledge into the model. TKG reasoning experiments on six benchmark datasets demonstrate the significant improvement of the proposed HiSMatch model, with up to 5.6\% performance improvement in MRR, compared to the state-of-the-art baselines.
Mixture of Experts for Biomedical Question Answering
Apr 15, 2022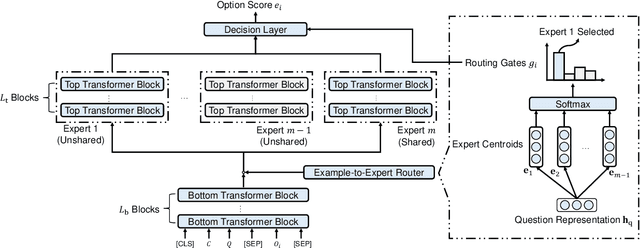
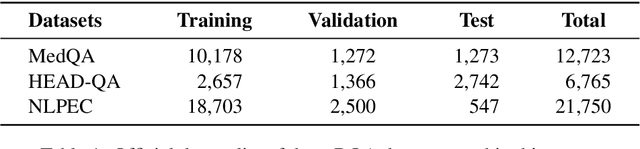

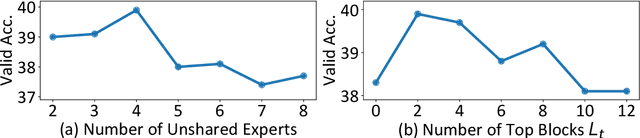
Biomedical Question Answering (BQA) has attracted increasing attention in recent years due to its promising application prospect. It is a challenging task because the biomedical questions are professional and usually vary widely. Existing question answering methods answer all questions with a homogeneous model, leading to various types of questions competing for the shared parameters, which will confuse the model decision for each single type of questions. In this paper, in order to alleviate the parameter competition problem, we propose a Mixture-of-Expert (MoE) based question answering method called MoEBQA that decouples the computation for different types of questions by sparse routing. To be specific, we split a pretrained Transformer model into bottom and top blocks. The bottom blocks are shared by all the examples, aiming to capture the general features. The top blocks are extended to an MoE version that consists of a series of independent experts, where each example is assigned to a few experts according to its underlying question type. MoEBQA automatically learns the routing strategy in an end-to-end manner so that each expert tends to deal with the question types it is expert in. We evaluate MoEBQA on three BQA datasets constructed based on real examinations. The results show that our MoE extension significantly boosts the performance of question answering models and achieves new state-of-the-art performance. In addition, we elaborately analyze our MoE modules to reveal how MoEBQA works and find that it can automatically group the questions into human-readable clusters.
Complex Evolutional Pattern Learning for Temporal Knowledge Graph Reasoning
Mar 20, 2022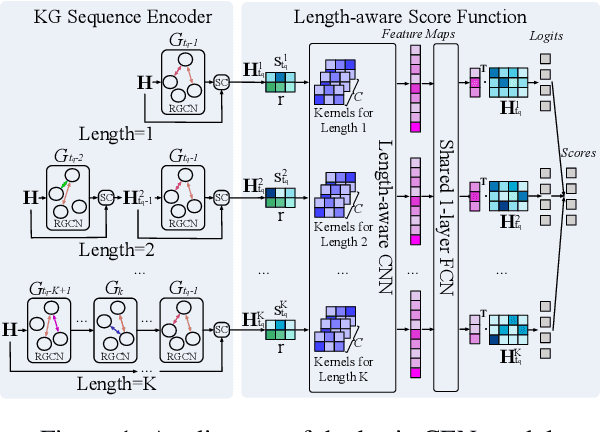
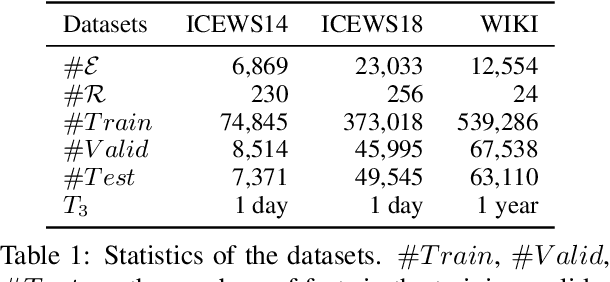
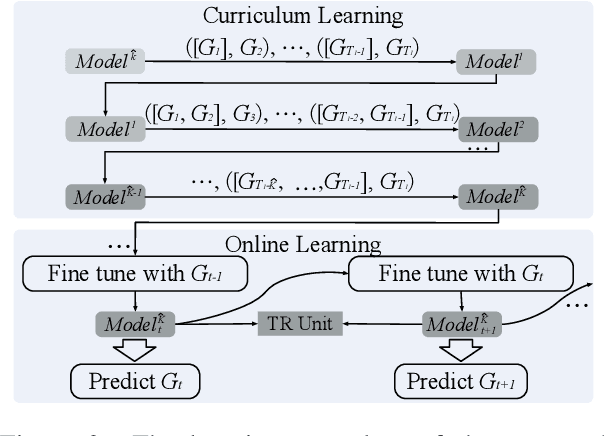
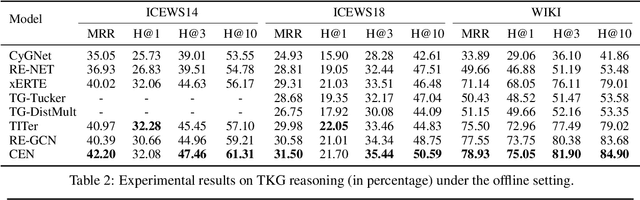
A Temporal Knowledge Graph (TKG) is a sequence of KGs corresponding to different timestamps. TKG reasoning aims to predict potential facts in the future given the historical KG sequences. One key of this task is to mine and understand evolutional patterns of facts from these sequences. The evolutional patterns are complex in two aspects, length-diversity and time-variability. Existing models for TKG reasoning focus on modeling fact sequences of a fixed length, which cannot discover complex evolutional patterns that vary in length. Furthermore, these models are all trained offline, which cannot well adapt to the changes of evolutional patterns from then on. Thus, we propose a new model, called Complex Evolutional Network (CEN), which uses a length-aware Convolutional Neural Network (CNN) to handle evolutional patterns of different lengths via an easy-to-difficult curriculum learning strategy. Besides, we propose to learn the model under the online setting so that it can adapt to the changes of evolutional patterns over time. Extensive experiments demonstrate that CEN obtains substantial performance improvement under both the traditional offline and the proposed online settings.
Improving Event Causality Identification via Self-Supervised Representation Learning on External Causal Statement
Jun 03, 2021

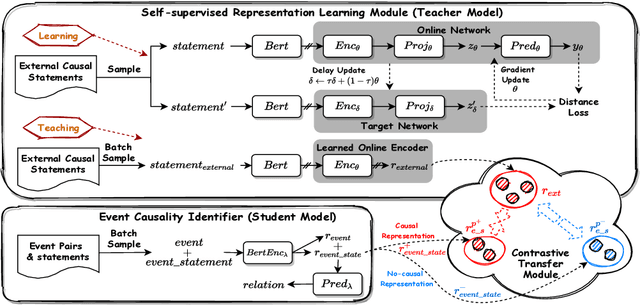
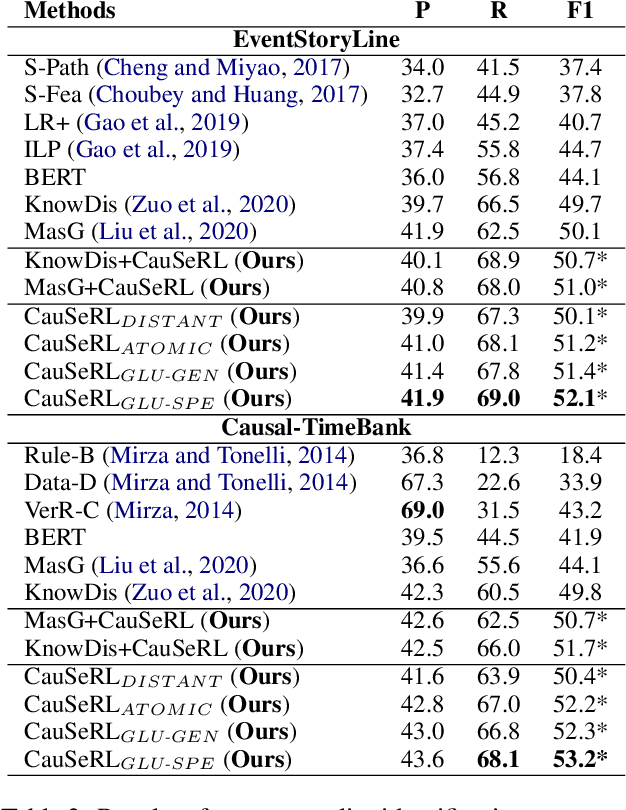
Current models for event causality identification (ECI) mainly adopt a supervised framework, which heavily rely on labeled data for training. Unfortunately, the scale of current annotated datasets is relatively limited, which cannot provide sufficient support for models to capture useful indicators from causal statements, especially for handing those new, unseen cases. To alleviate this problem, we propose a novel approach, shortly named CauSeRL, which leverages external causal statements for event causality identification. First of all, we design a self-supervised framework to learn context-specific causal patterns from external causal statements. Then, we adopt a contrastive transfer strategy to incorporate the learned context-specific causal patterns into the target ECI model. Experimental results show that our method significantly outperforms previous methods on EventStoryLine and Causal-TimeBank (+2.0 and +3.4 points on F1 value respectively).
LearnDA: Learnable Knowledge-Guided Data Augmentation for Event Causality Identification
Jun 03, 2021
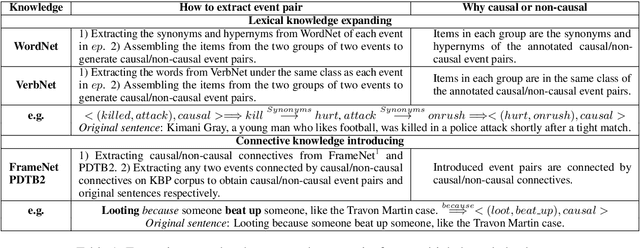
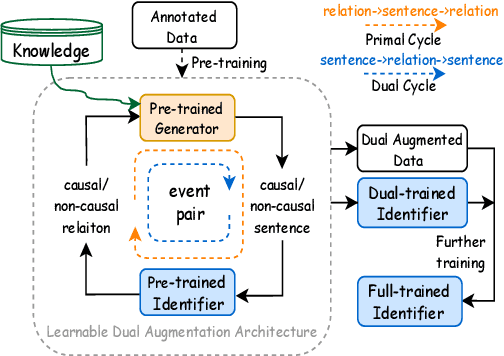
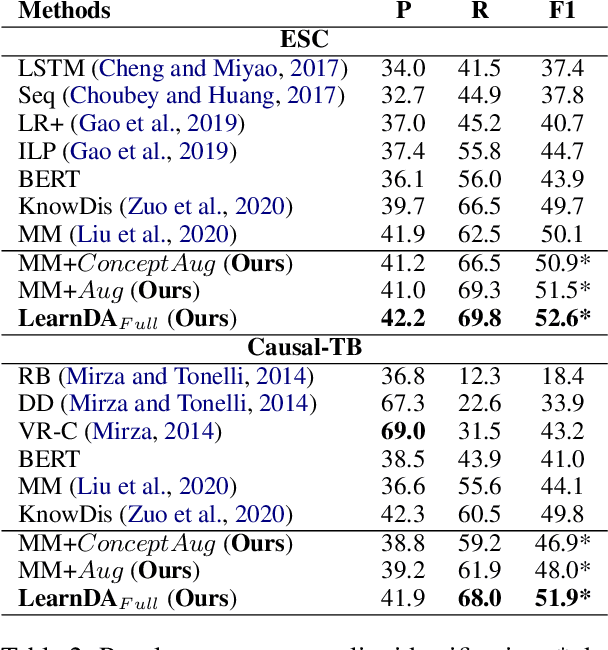
Modern models for event causality identification (ECI) are mainly based on supervised learning, which are prone to the data lacking problem. Unfortunately, the existing NLP-related augmentation methods cannot directly produce the available data required for this task. To solve the data lacking problem, we introduce a new approach to augment training data for event causality identification, by iteratively generating new examples and classifying event causality in a dual learning framework. On the one hand, our approach is knowledge-guided, which can leverage existing knowledge bases to generate well-formed new sentences. On the other hand, our approach employs a dual mechanism, which is a learnable augmentation framework and can interactively adjust the generation process to generate task-related sentences. Experimental results on two benchmarks EventStoryLine and Causal-TimeBank show that 1) our method can augment suitable task-related training data for ECI; 2) our method outperforms previous methods on EventStoryLine and Causal-TimeBank (+2.5 and +2.1 points on F1 value respectively).
Generating Pertinent and Diversified Comments with Topic-aware Pointer-Generator Networks
May 09, 2020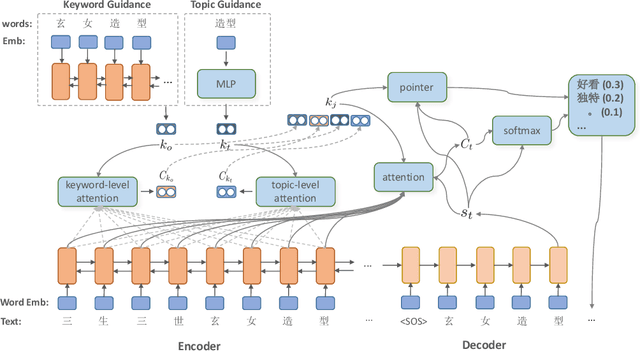

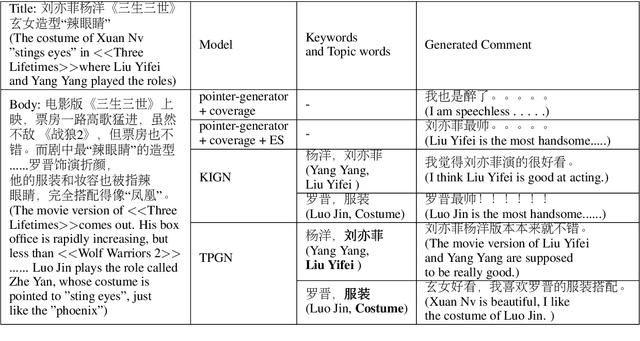
Comment generation, a new and challenging task in Natural Language Generation (NLG), attracts a lot of attention in recent years. However, comments generated by previous work tend to lack pertinence and diversity. In this paper, we propose a novel generation model based on Topic-aware Pointer-Generator Networks (TPGN), which can utilize the topic information hidden in the articles to guide the generation of pertinent and diversified comments. Firstly, we design a keyword-level and topic-level encoder attention mechanism to capture topic information in the articles. Next, we integrate the topic information into pointer-generator networks to guide comment generation. Experiments on a large scale of comment generation dataset show that our model produces the valuable comments and outperforms competitive baseline models significantly.