 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARC-Hunyuan-Video-7B: Structured Video Comprehension of Real-World Shorts
Jul 28, 2025Real-world user-generated short videos, especially those distributed on platforms such as WeChat Channel and TikTok, dominate the mobile internet. However, current large multimodal models lack essential temporally-structured, detailed, and in-depth video comprehension capabilities, which are the cornerstone of effective video search and recommendation, as well as emerging video applications. Understanding real-world shorts is actually challenging due to their complex visual elements, high information density in both visuals and audio, and fast pacing that focuses on emotional expression and viewpoint delivery. This requires advanced reasoning to effectively integrate multimodal information, including visual, audio, and text. In this work, we introduce ARC-Hunyuan-Video, a multimodal model that processes visual, audio, and textual signals from raw video inputs end-to-end for structured comprehension. The model is capable of multi-granularity timestamped video captioning and summarization, open-ended video question answering, temporal video grounding, and video reasoning. Leveraging high-quality data from an automated annotation pipeline, our compact 7B-parameter model is trained through a comprehensive regimen: pre-training, instruction fine-tuning, cold start, reinforcement learning (RL) post-training, and final instruction fine-tuning. Quantitative evaluations on our introduced benchmark ShortVid-Bench and qualitative comparisons demonstrate its strong performance in real-world video comprehension, and it supports zero-shot or fine-tuning with a few samples for diverse downstream applications. The real-world production deployment of our model has yielded tangible and measurable improvements in user engagement and satisfaction, a success supported by its remarkable efficiency, with stress tests indicating an inference time of just 10 seconds for a one-minute video on H20 GPU.
Type-enriched Hierarchical Contrastive Strategy for Fine-Grained Entity Typing
Aug 22, 2022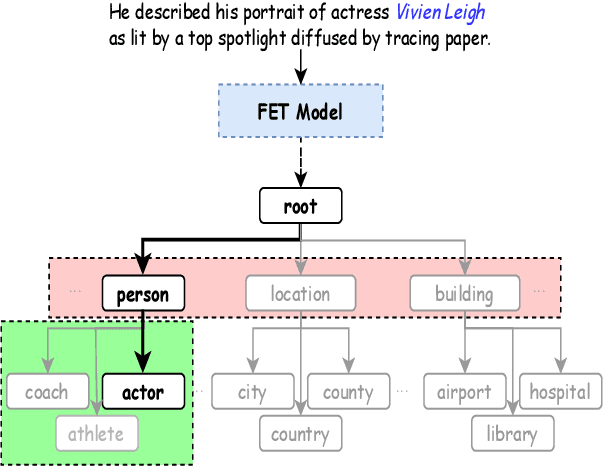
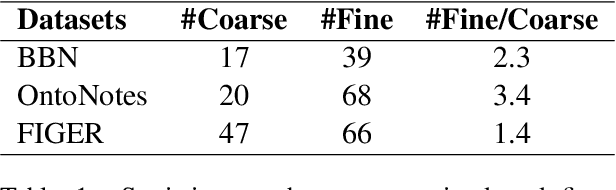
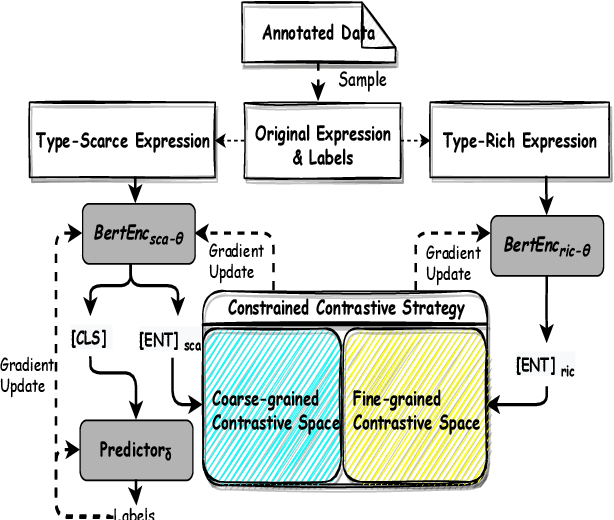
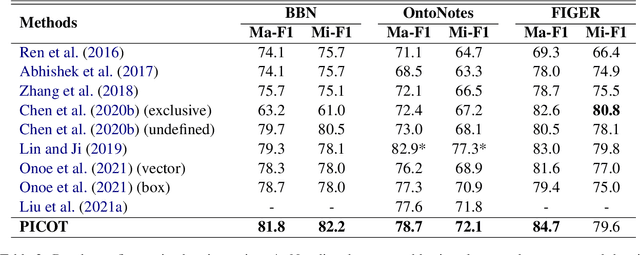
Fine-grained entity typing (FET) aims to deduce specific semantic types of the entity mentions in text. Modern methods for FET mainly focus on learning what a certain type looks like. And few works directly model the type differences, that is, let models know the extent that one type is different from others. To alleviate this problem, we propose a type-enriched hierarchical contrastive strategy for FET. Our method can directly model the differences between hierarchical types and improve the ability to distinguish multi-grained similar types. On the one hand, we embed type into entity contexts to make type information directly perceptible. On the other hand, we design a constrained contrastive strategy on the hierarchical structure to directly model the type differences, which can simultaneously perceive the distinguishability between types at different granularity. Experimental results on three benchmarks, BBN, OntoNotes, and FIGER show that our method achieves significant performance on FET by effectively modeling type differences.
UniCausal: Unified Benchmark and Model for Causal Text Mining
Aug 19, 2022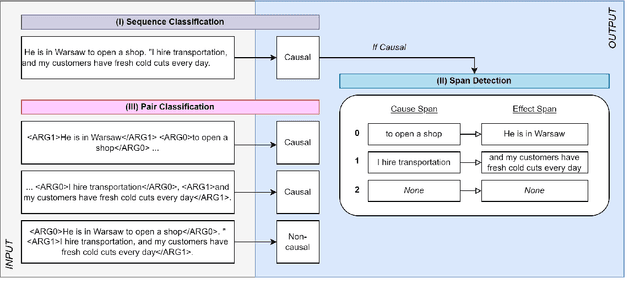

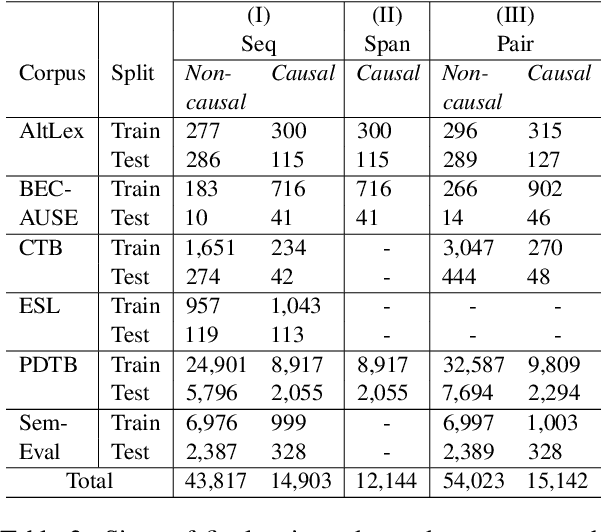
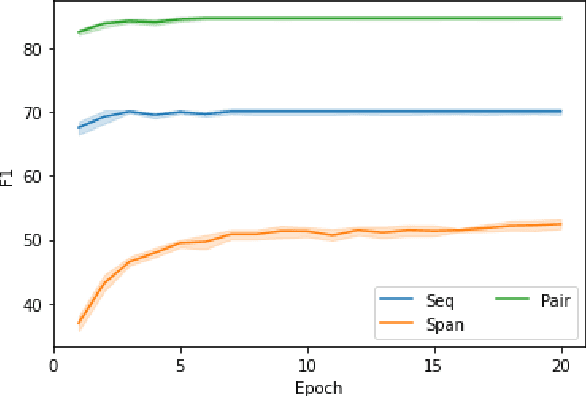
Current causal text mining datasets vary in objectives, data coverage, and annotation schemes. These inconsistent efforts prevented modeling capabilities and fair comparisons of model performance. Few datasets include cause-effect span annotations, which are needed for end-to-end causal extraction. Therefore, we proposed UniCausal, a unified benchmark for causal text mining across three tasks: Causal Sequence Classification, Cause-Effect Span Detection and Causal Pair Classification. We consolidated and aligned annotations of six high quality human-annotated corpus, resulting in a total of 58,720, 12,144 and 69,165 examples for each task respectively. Since the definition of causality can be subjective, our framework was designed to allow researchers to work on some or all datasets and tasks. As an initial benchmark, we adapted BERT pre-trained models to our task and generated baseline scores. We achieved 70.10% Binary F1 score for Sequence Classification, 52.42% Macro F1 score for Span Detection, and 84.68% Binary F1 score for Pair Classification.
Improving Event Causality Identification via Self-Supervised Representation Learning on External Causal Statement
Jun 03, 2021

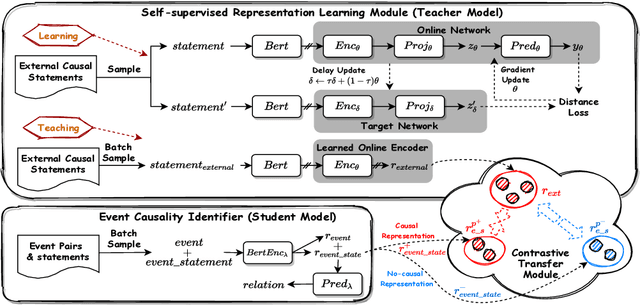
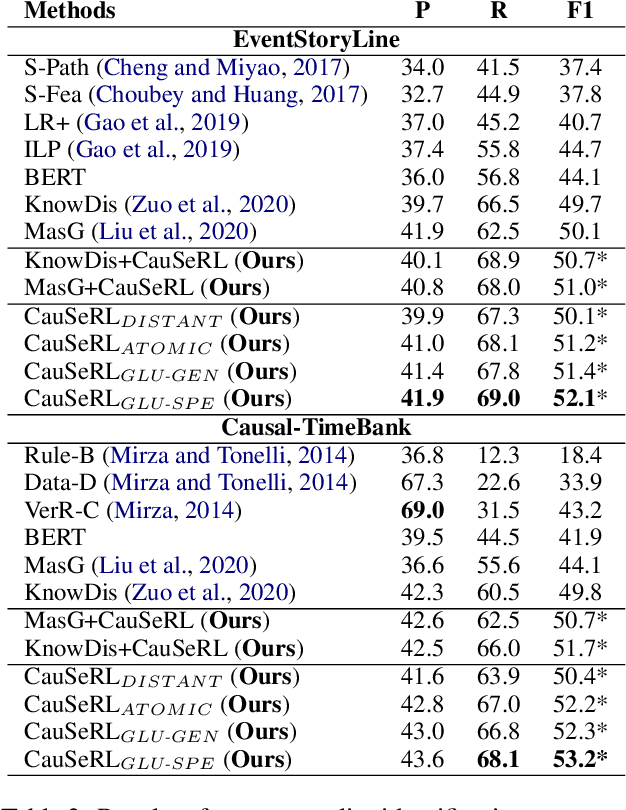
Current models for event causality identification (ECI) mainly adopt a supervised framework, which heavily rely on labeled data for training. Unfortunately, the scale of current annotated datasets is relatively limited, which cannot provide sufficient support for models to capture useful indicators from causal statements, especially for handing those new, unseen cases. To alleviate this problem, we propose a novel approach, shortly named CauSeRL, which leverages external causal statements for event causality identification. First of all, we design a self-supervised framework to learn context-specific causal patterns from external causal statements. Then, we adopt a contrastive transfer strategy to incorporate the learned context-specific causal patterns into the target ECI model. Experimental results show that our method significantly outperforms previous methods on EventStoryLine and Causal-TimeBank (+2.0 and +3.4 points on F1 value respectively).
LearnDA: Learnable Knowledge-Guided Data Augmentation for Event Causality Identification
Jun 03, 2021
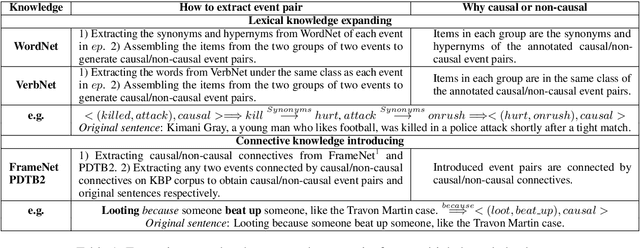
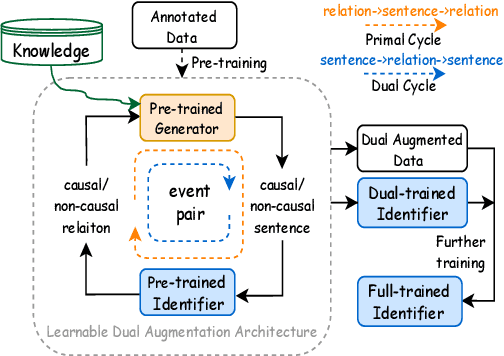
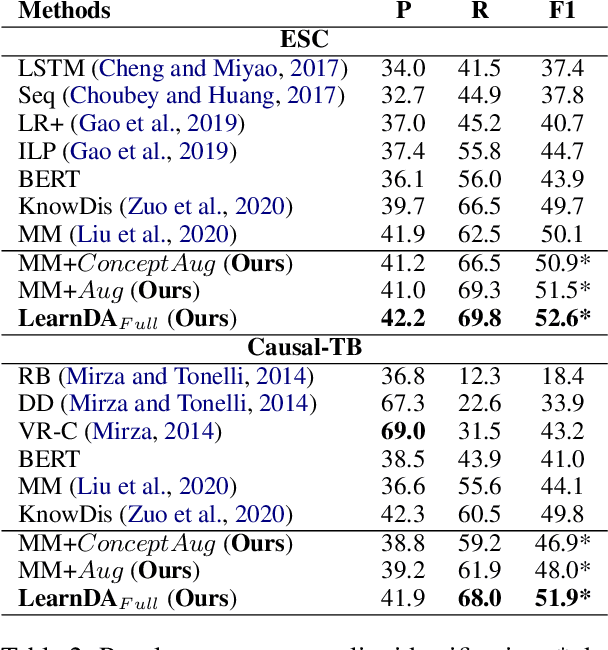
Modern models for event causality identification (ECI) are mainly based on supervised learning, which are prone to the data lacking problem. Unfortunately, the existing NLP-related augmentation methods cannot directly produce the available data required for this task. To solve the data lacking problem, we introduce a new approach to augment training data for event causality identification, by iteratively generating new examples and classifying event causality in a dual learning framework. On the one hand, our approach is knowledge-guided, which can leverage existing knowledge bases to generate well-formed new sentences. On the other hand, our approach employs a dual mechanism, which is a learnable augmentation framework and can interactively adjust the generation process to generate task-related sentences. Experimental results on two benchmarks EventStoryLine and Causal-TimeBank show that 1) our method can augment suitable task-related training data for ECI; 2) our method outperforms previous methods on EventStoryLine and Causal-TimeBank (+2.5 and +2.1 points on F1 value respectively).
KnowDis: Knowledge Enhanced Data Augmentation for Event Causality Detection via Distant Supervision
Oct 21, 2020


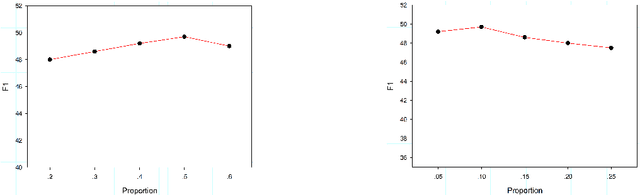
Modern models of event causality detection (ECD) are mainly based on supervised learning from small hand-labeled corpora. However, hand-labeled training data is expensive to produce, low coverage of causal expressions and limited in size, which makes supervised methods hard to detect causal relations between events. To solve this data lacking problem, we investigate a data augmentation framework for ECD, dubbed as Knowledge Enhanced Distant Data Augmentation (KnowDis). Experimental results on two benchmark datasets EventStoryLine corpus and Causal-TimeBank show that 1) KnowDis can augment available training data assisted with the lexical and causal commonsense knowledge for ECD via distant supervision, and 2) our method outperforms previous methods by a large margin assisted with automatically labeled training data.
* Accepted to COLING2020
Towards Causal Explanation Detection with Pyramid Salient-Aware Network
Sep 24, 2020

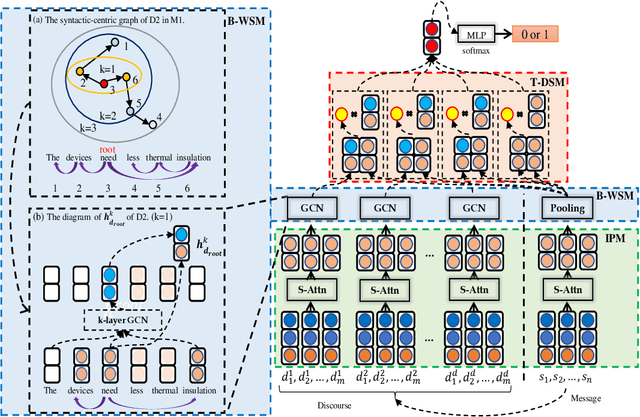
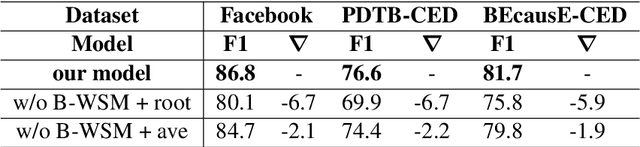
Causal explanation analysis (CEA) can assist us to understand the reasons behind daily events, which has been found very helpful for understanding the coherence of messages. In this paper, we focus on Causal Explanation Detection, an important subtask of causal explanation analysis, which determines whether a causal explanation exists in one message. We design a Pyramid Salient-Aware Network (PSAN) to detect causal explanations on messages. PSAN can assist in causal explanation detection via capturing the salient semantics of discourses contained in their keywords with a bottom graph-based word-level salient network. Furthermore, PSAN can modify the dominance of discourses via a top attention-based discourse-level salient network to enhance explanatory semantics of messages. The experiments on the commonly used dataset of CEA shows that the PSAN outperforms the state-of-the-art method by 1.8% F1 value on the Causal Explanation Detection task.
Event Coreference Resolution via a Multi-loss Neural Network without Using Argument Information
Sep 22, 2020



Event coreference resolution(ECR) is an important task in Natural Language Processing (NLP) and nearly all the existing approaches to this task rely on event argument information. However, these methods tend to suffer from error propagation from the stage of event argument extraction. Besides, not every event mention contains all arguments of an event, and argument information may confuse the model that events have arguments to detect event coreference in real text. Furthermore, the context information of an event is useful to infer the coreference between events. Thus, in order to reduce the errors propagated from event argument extraction and use context information effectively, we propose a multi-loss neural network model that does not need any argument information to do the within-document event coreference resolution task and achieve a significant performance than the state-of-the-art methods.
* Published on SCIENCE CHINA Information Sciences