 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniCausal: Unified Benchmark and Model for Causal Text Mining
Paper and Code
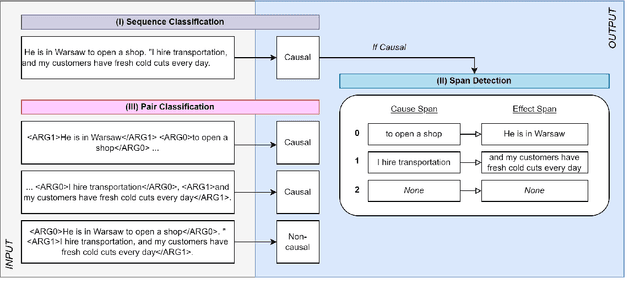

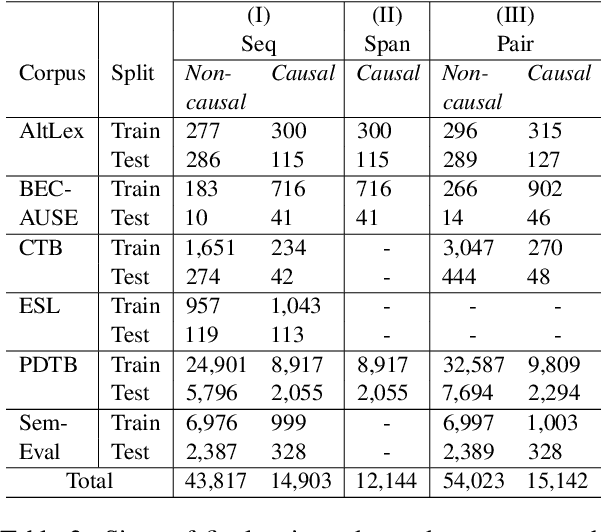
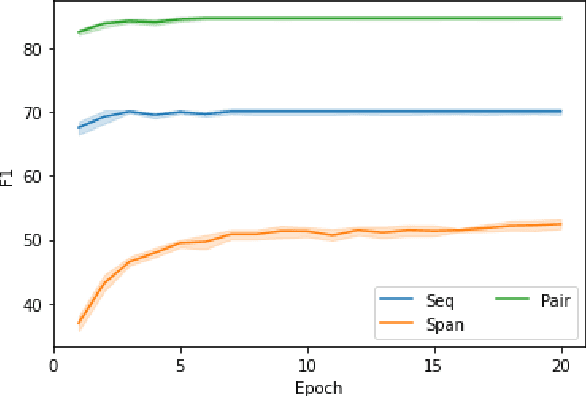
Current causal text mining datasets vary in objectives, data coverage, and annotation schemes. These inconsistent efforts prevented modeling capabilities and fair comparisons of model performance. Few datasets include cause-effect span annotations, which are needed for end-to-end causal extraction. Therefore, we proposed UniCausal, a unified benchmark for causal text mining across three tasks: Causal Sequence Classification, Cause-Effect Span Detection and Causal Pair Classification. We consolidated and aligned annotations of six high quality human-annotated corpus, resulting in a total of 58,720, 12,144 and 69,165 examples for each task respectively. Since the definition of causality can be subjective, our framework was designed to allow researchers to work on some or all datasets and tasks. As an initial benchmark, we adapted BERT pre-trained models to our task and generated baseline scores. We achieved 70.10% Binary F1 score for Sequence Classification, 52.42% Macro F1 score for Span Detection, and 84.68% Binary F1 score for Pair Classification.