 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenAI-Net: A Generative AI Framework for Automated Biomolecular Network Design
Jan 24, 2026Biomolecular networks underpin emerging technologies in synthetic biology-from robust biomanufacturing and metabolic engineering to smart therapeutics and cell-based diagnostics-and also provide a mechanistic language for understanding complex dynamics in natural and ecological systems. Yet designing chemical reaction networks (CRNs) that implement a desired dynamical function remains largely manual: while a proposed network can be checked by simulation, the reverse problem of discovering a network from a behavioral specification is difficult, requiring substantial human insight to navigate a vast space of topologies and kinetic parameters with nonlinear and possibly stochastic dynamics. Here we introduce GenAI-Net, a generative AI framework that automates CRN design by coupling an agent that proposes reactions to simulation-based evaluation defined by a user-specified objective. GenAI-Net efficiently produces novel, topologically diverse solutions across multiple design tasks, including dose responses, complex logic gates, classifiers, oscillators, and robust perfect adaptation in deterministic and stochastic settings (including noise reduction). By turning specifications into families of circuit candidates and reusable motifs, GenAI-Net provides a general route to programmable biomolecular circuit design and accelerates the translation from desired function to implementable mechanisms.
KernelEvolve: Scaling Agentic Kernel Coding for Heterogeneous AI Accelerators at Meta
Dec 30, 2025Making deep learning recommendation model (DLRM) training and inference fast and efficient is important. However, this presents three key system challenges - model architecture diversity, kernel primitive diversity, and hardware generation and architecture heterogeneity. This paper presents KernelEvolve-an agentic kernel coding framework-to tackle heterogeneity at-scale for DLRM. KernelEvolve is designed to take kernel specifications as input and automate the process of kernel generation and optimization for recommendation model across heterogeneous hardware architectures. KernelEvolve does so by operating at multiple programming abstractions, from Triton and CuTe DSL to low-level hardware agnostic languages, spanning the full hardware-software optimization stack. The kernel optimization process is described as graph-based search with selection policy, universal operator, fitness function, and termination rule, dynamically adapts to runtime execution context through retrieval-augmented prompt synthesis. We designed, implemented, and deployed KernelEvolve to optimize a wide variety of production recommendation models across generations of NVIDIA and AMD GPUs, as well as Meta's AI accelerators. We validate KernelEvolve on the publicly-available KernelBench suite, achieving 100% pass rate on all 250 problems across three difficulty levels, and 160 PyTorch ATen operators across three heterogeneous hardware platforms, demonstrating 100% correctness. KernelEvolve reduces development time from weeks to hours and achieves substantial performance improvements over PyTorch baselines across diverse production use cases and for heterogeneous AI systems at-scale. Beyond performance efficiency improvements, KernelEvolve significantly mitigates the programmability barrier for new AI hardware by enabling automated kernel generation for in-house developed AI hardware.
Intelligent Task Scheduling for Microservices via A3C-Based Reinforcement Learning
May 01, 2025To address the challenges of high resource dynamism and intensive task concurrency in microservice systems, this paper proposes an adaptive resource scheduling method based on the A3C reinforcement learning algorithm. The scheduling problem is modeled as a Markov Decision Process, where policy and value networks are jointly optimized to enable fine-grained resource allocation under varying load conditions. The method incorporates an asynchronous multi-threaded learning mechanism, allowing multiple agents to perform parallel sampling and synchronize updates to the global network parameters. This design improves both policy convergence efficiency and model stability. In the experimental section, a real-world dataset is used to construct a scheduling scenario. The proposed method is compared with several typical approaches across multiple evaluation metrics, including task delay, scheduling success rate, resource utilization, and convergence speed. The results show that the proposed method delivers high scheduling performance and system stability in multi-task concurrent environments. It effectively alleviates the resource allocation bottlenecks faced by traditional methods under heavy load, demonstrating its practical value for intelligent scheduling in microservice systems.
Dynamical errors in machine learning forecasts
Apr 16, 2025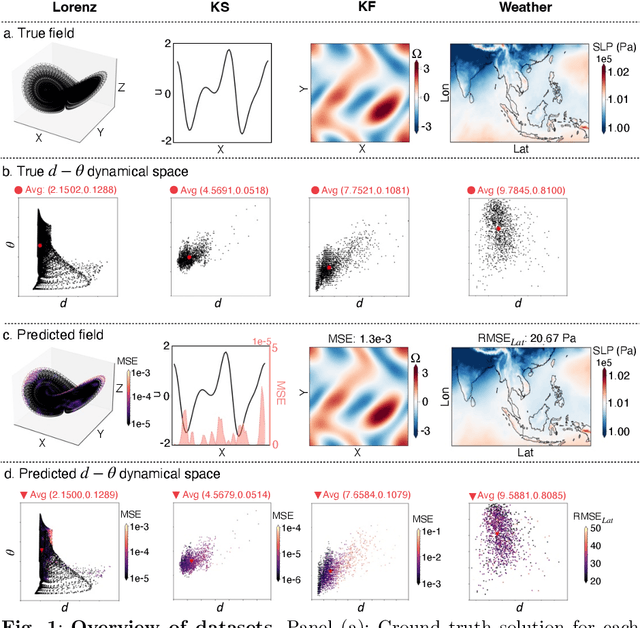
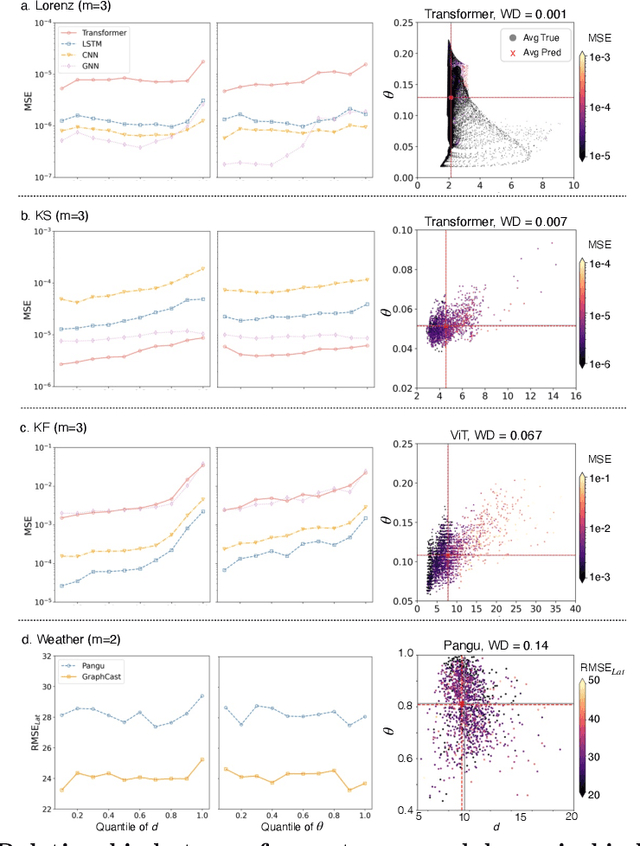
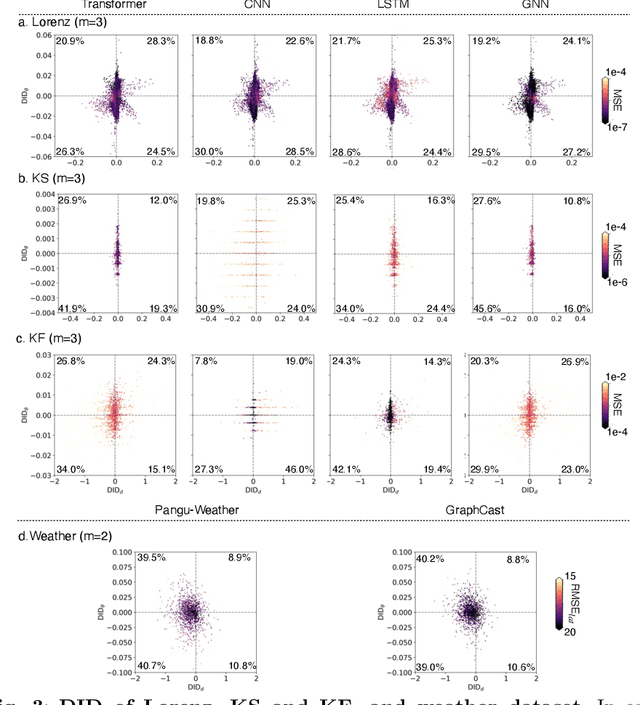
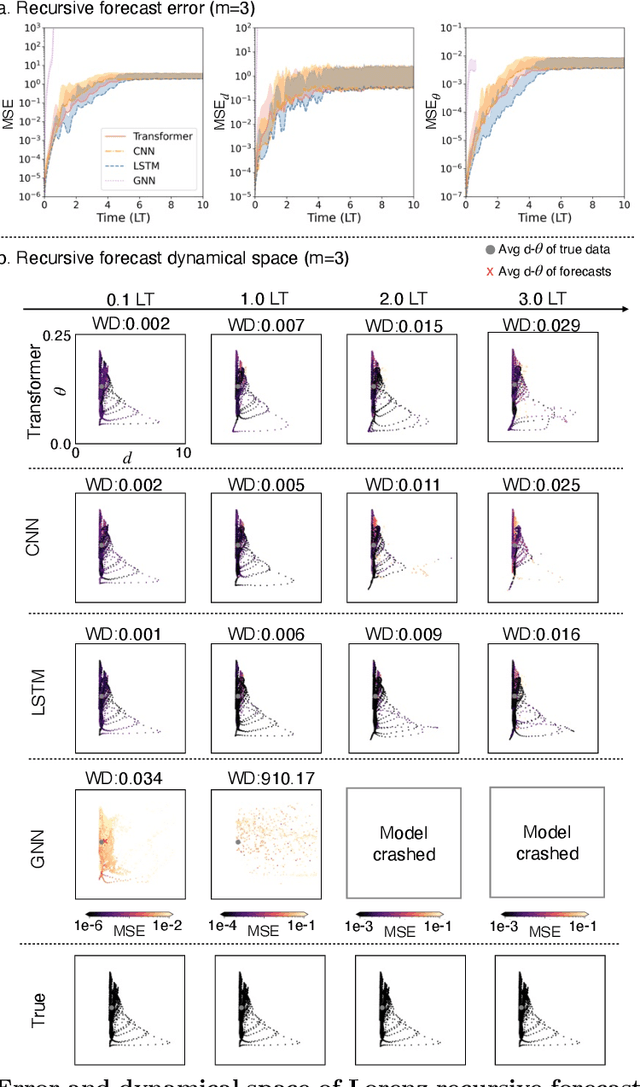
In machine learning forecasting, standard error metrics such as mean absolute error (MAE) and mean squared error (MSE) quantify discrepancies between predictions and target values. However, these metrics do not directly evaluate the physical and/or dynamical consistency of forecasts, an increasingly critical concern in scientific and engineering applications. Indeed, a fundamental yet often overlooked question is whether machine learning forecasts preserve the dynamical behavior of the underlying system. Addressing this issue is essential for assessing the fidelity of machine learning models and identifying potential failure modes, particularly in applications where maintaining correct dynamical behavior is crucial. In this work, we investigate the relationship between standard forecasting error metrics, such as MAE and MSE, and the dynamical properties of the underlying system. To achieve this goal, we use two recently developed dynamical indices: the instantaneous dimension ($d$), and the inverse persistence ($\theta$). Our results indicate that larger forecast errors -- e.g., higher MSE -- tend to occur in states with higher $d$ (higher complexity) and higher $\theta$ (lower persistence). To further assess dynamical consistency, we propose error metrics based on the dynamical indices that measure the discrepancy of the forecasted $d$ and $\theta$ versus their correct values. Leveraging these dynamical indices-based metrics, we analyze direct and recursive forecasting strategies for three canonical datasets -- Lorenz, Kuramoto-Sivashinsky equation, and Kolmogorov flow -- as well as a real-world weather forecasting task. Our findings reveal substantial distortions in dynamical properties in ML forecasts, especially for long forecast lead times or long recursive simulations, providing complementary information on ML forecast fidelity that can be used to improve ML models.
Unsupervised Detection of Fraudulent Transactions in E-commerce Using Contrastive Learning
Mar 24, 2025With the rapid development of e-commerce, e-commerce platforms are facing an increasing number of fraud threats. Effectively identifying and preventing these fraudulent activities has become a critical research problem. Traditional fraud detection methods typically rely on supervised learning, which requires large amounts of labeled data. However, such data is often difficult to obtain, and the continuous evolution of fraudulent activities further reduces the adaptability and effectiveness of traditional methods. To address this issue, this study proposes an unsupervised e-commerce fraud detection algorithm based on SimCLR. The algorithm leverages the contrastive learning framework to effectively detect fraud by learning the underlying representations of transaction data in an unlabeled setting. Experimental results on the eBay platform dataset show that the proposed algorithm outperforms traditional unsupervised methods such as K-means, Isolation Forest, and Autoencoders in terms of accuracy, precision, recall, and F1 score, demonstrating strong fraud detection capabilities. The results confirm that the SimCLR-based unsupervised fraud detection method has broad application prospects in e-commerce platform security, improving both detection accuracy and robustness. In the future, with the increasing scale and diversity of datasets, the model's performance will continue to improve, and it could be integrated with real-time monitoring systems to provide more efficient security for e-commerce platforms.
Semantic and Contextual Modeling for Malicious Comment Detection with BERT-BiLSTM
Mar 14, 2025



This study aims to develop an efficient and accurate model for detecting malicious comments, addressing the increasingly severe issue of false and harmful content on social media platforms. We propose a deep learning model that combines BERT and BiLSTM. The BERT model, through pre-training, captures deep semantic features of text, while the BiLSTM network excels at processing sequential data and can further model the contextual dependencies of text. Experimental results on the Jigsaw Unintended Bias in Toxicity Classification dataset demonstrate that the BERT+BiLSTM model achieves superior performance in malicious comment detection tasks, with a precision of 0.94, recall of 0.93, and accuracy of 0.94. This surpasses other models, including standalone BERT, TextCNN, TextRNN, and traditional machine learning algorithms using TF-IDF features. These results confirm the superiority of the BERT+BiLSTM model in handling imbalanced data and capturing deep semantic features of malicious comments, providing an effective technical means for social media content moderation and online environment purification.
Breaking the Context Bottleneck on Long Time Series Forecasting
Dec 21, 2024Long-term time-series forecasting is essential for planning and decision-making in economics, energy, and transportation, where long foresight is required. To obtain such long foresight, models must be both efficient and effective in processing long sequence. Recent advancements have enhanced the efficiency of these models; however, the challenge of effectively leveraging longer sequences persists. This is primarily due to the tendency of these models to overfit when presented with extended inputs, necessitating the use of shorter input lengths to maintain tolerable error margins. In this work, we investigate the multiscale modeling method and propose the Logsparse Decomposable Multiscaling (LDM) framework for the efficient and effective processing of long sequences. We demonstrate that by decoupling patterns at different scales in time series, we can enhance predictability by reducing non-stationarity, improve efficiency through a compact long input representation, and simplify the architecture by providing clear task assignments. Experimental results demonstrate that LDM not only outperforms all baselines in long-term forecasting benchmarks, but also reducing both training time and memory costs.
Verb Mirage: Unveiling and Assessing Verb Concept Hallucinations in Multimodal Large Language Models
Dec 06, 2024



Multimodal Large Language Models (MLLMs) have garnered significant attention recently and demonstrate outstanding capabilities in various tasks such as OCR, VQA, captioning, $\textit{etc}$. However, hallucination remains a persistent issue. While numerous methods have been proposed to mitigate hallucinations, achieving notable improvements, these methods primarily focus on mitigating hallucinations about $\textbf{object/noun-related}$ concepts. Verb concepts, crucial for understanding human actions, have been largely overlooked. In this paper, to the best of our knowledge, we are the $\textbf{first}$ to investigate the $\textbf{verb hallucination}$ phenomenon of MLLMs from various perspectives. Our findings reveal that most state-of-the-art MLLMs suffer from severe verb hallucination. To assess the effectiveness of existing mitigation methods for object concept hallucination on verb hallucination, we evaluated these methods and found that they do not effectively address verb hallucination. To address this issue, we propose a novel rich verb knowledge-based tuning method to mitigate verb hallucination. The experiment results demonstrate that our method significantly reduces hallucinations related to verbs. $\textit{Our code and data will be made publicly available}$.
Incorporating uncertainty quantification into travel mode choice modeling: a Bayesian neural network (BNN) approach and an uncertainty-guided active survey framework
Jun 16, 2024Existing deep learning approaches for travel mode choice modeling fail to inform modelers about their prediction uncertainty. Even when facing scenarios that are out of the distribution of training data, which implies high prediction uncertainty, these approaches still provide deterministic answers, potentially leading to misguidance. To address this limitation, this study introduces the concept of uncertainty from the field of explainable artificial intelligence into travel mode choice modeling. We propose a Bayesian neural network-based travel mode prediction model (BTMP) that quantifies the uncertainty of travel mode predictions, enabling the model itself to "know" and "tell" what it doesn't know. With BTMP, we further propose an uncertainty-guided active survey framework, which dynamically formulates survey questions representing travel mode choice scenarios with high prediction uncertainty. Through iterative collection of responses to these dynamically tailored survey questions, BTMP is iteratively trained to achieve the desired accuracy faster with fewer questions, thereby reducing survey costs. Experimental validation using synthetic datasets confirms the effectiveness of BTMP in quantifying prediction uncertainty. Furthermore, experiments, utilizing both synthetic and real-world data, demonstrate that the BTMP model, trained with the uncertainty-guided active survey framework, requires 20% to 50% fewer survey responses to match the performance of the model trained on randomly collected survey data. Overall, the proposed BTMP model and active survey framework innovatively incorporate uncertainty quantification into travel mode choice modeling, providing model users with essential insights into prediction reliability while optimizing data collection for deep learning model training in a cost-efficient manner.
vMFER: Von Mises-Fisher Experience Resampling Based on Uncertainty of Gradient Directions for Policy Improvement
May 14, 2024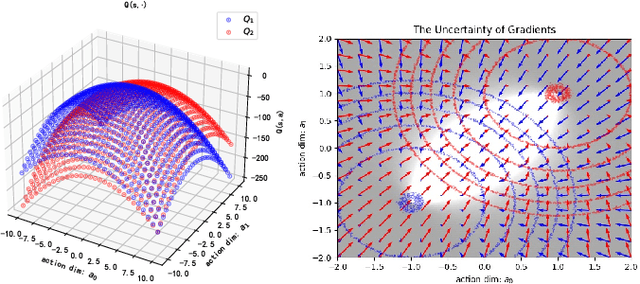

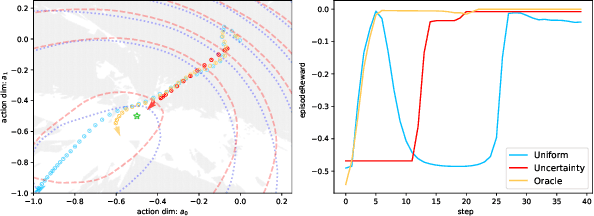
Reinforcement Learning (RL) is a widely employed technique in decision-making problems, encompassing two fundamental operations -- policy evaluation and policy improvement. Enhancing learning efficiency remains a key challenge in RL, with many efforts focused on using ensemble critics to boost policy evaluation efficiency. However, when using multiple critics, the actor in the policy improvement process can obtain different gradients. Previous studies have combined these gradients without considering their disagreements. Therefore, optimizing the policy improvement process is crucial to enhance learning efficiency. This study focuses on investigating the impact of gradient disagreements caused by ensemble critics on policy improvement. We introduce the concept of uncertainty of gradient directions as a means to measure the disagreement among gradients utilized in the policy improvement process. Through measuring the disagreement among gradients, we find that transitions with lower uncertainty of gradient directions are more reliable in the policy improvement process. Building on this analysis, we propose a method called von Mises-Fisher Experience Resampling (vMFER), which optimizes the policy improvement process by resampling transitions and assigning higher confidence to transitions with lower uncertainty of gradient directions. Our experiments demonstrate that vMFER significantly outperforms the benchmark and is particularly well-suited for ensemble structures in RL.