 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Interactive Agent in Large FPS Game Map with Rule-enhanced Reinforcement Learning
Oct 07, 2024In the realm of competitive gaming, 3D first-person shooter (FPS) games have gained immense popularity, prompting the development of game AI systems to enhance gameplay. However, deploying game AI in practical scenarios still poses challenges, particularly in large-scale and complex FPS games. In this paper, we focus on the practical deployment of game AI in the online multiplayer competitive 3D FPS game called Arena Breakout, developed by Tencent Games. We propose a novel gaming AI system named Private Military Company Agent (PMCA), which is interactable within a large game map and engages in combat with players while utilizing tactical advantages provided by the surrounding terrain. To address the challenges of navigation and combat in modern 3D FPS games, we introduce a method that combines navigation mesh (Navmesh) and shooting-rule with deep reinforcement learning (NSRL). The integration of Navmesh enhances the agent's global navigation capabilities while shooting behavior is controlled using rule-based methods to ensure controllability. NSRL employs a DRL model to predict when to enable the navigation mesh, resulting in a diverse range of behaviors for the game AI. Customized rewards for human-like behaviors are also employed to align PMCA's behavior with that of human players.
vMFER: Von Mises-Fisher Experience Resampling Based on Uncertainty of Gradient Directions for Policy Improvement
May 14, 2024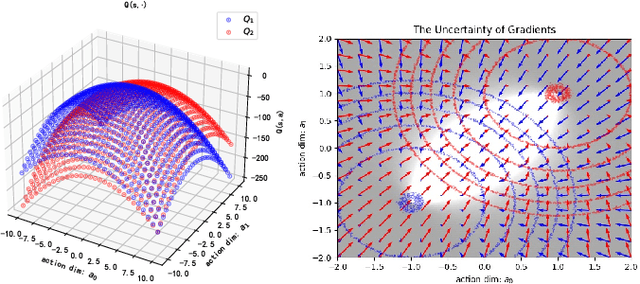

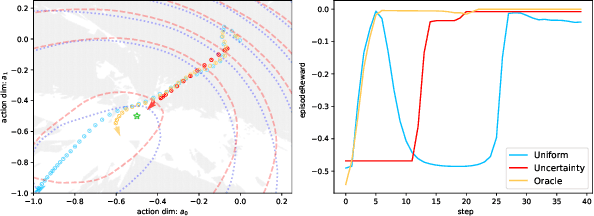
Reinforcement Learning (RL) is a widely employed technique in decision-making problems, encompassing two fundamental operations -- policy evaluation and policy improvement. Enhancing learning efficiency remains a key challenge in RL, with many efforts focused on using ensemble critics to boost policy evaluation efficiency. However, when using multiple critics, the actor in the policy improvement process can obtain different gradients. Previous studies have combined these gradients without considering their disagreements. Therefore, optimizing the policy improvement process is crucial to enhance learning efficiency. This study focuses on investigating the impact of gradient disagreements caused by ensemble critics on policy improvement. We introduce the concept of uncertainty of gradient directions as a means to measure the disagreement among gradients utilized in the policy improvement process. Through measuring the disagreement among gradients, we find that transitions with lower uncertainty of gradient directions are more reliable in the policy improvement process. Building on this analysis, we propose a method called von Mises-Fisher Experience Resampling (vMFER), which optimizes the policy improvement process by resampling transitions and assigning higher confidence to transitions with lower uncertainty of gradient directions. Our experiments demonstrate that vMFER significantly outperforms the benchmark and is particularly well-suited for ensemble structures in RL.
Homotopy Based Reinforcement Learning with Maximum Entropy for Autonomous Air Combat
Dec 01, 2021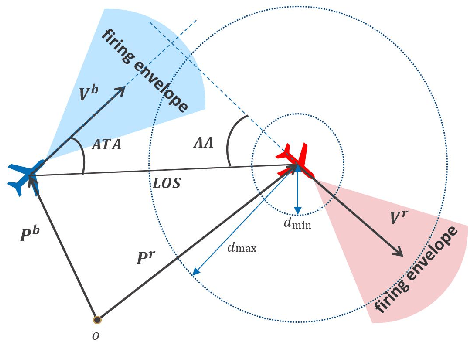
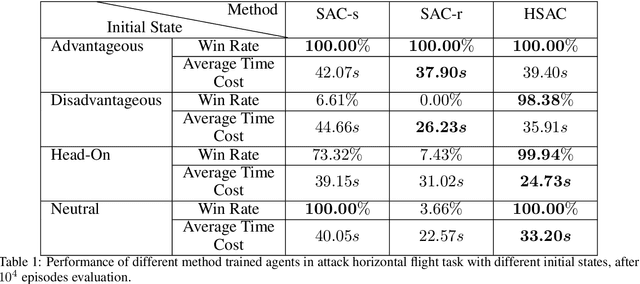

The Intelligent decision of the unmanned combat aerial vehicle (UCAV) has long been a challenging problem. The conventional search method can hardly satisfy the real-time demand during high dynamics air combat scenarios. The reinforcement learning (RL) method can significantly shorten the decision time via using neural networks. However, the sparse reward problem limits its convergence speed and the artificial prior experience reward can easily deviate its optimal convergent direction of the original task, which raises great difficulties for the RL air combat application. In this paper, we propose a homotopy-based soft actor-critic method (HSAC) which focuses on addressing these problems via following the homotopy path between the original task with sparse reward and the auxiliary task with artificial prior experience reward. The convergence and the feasibility of this method are also proved in this paper. To confirm our method feasibly, we construct a detailed 3D air combat simulation environment for the RL-based methods training firstly, and we implement our method in both the attack horizontal flight UCAV task and the self-play confrontation task. Experimental results show that our method performs better than the methods only utilizing the sparse reward or the artificial prior experience reward. The agent trained by our method can reach more than 98.3% win rate in the attack horizontal flight UCAV task and average 67.4% win rate when confronted with the agents trained by the other two methods.