 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeO-Researcher: An Open Ended Deep Research Model via Multi-Agent Distillation and Agentic RL
Jan 07, 2026The performance gap between closed-source and open-source large language models (LLMs) is largely attributed to disparities in access to high-quality training data. To bridge this gap, we introduce a novel framework for the automated synthesis of sophisticated, research-grade instructional data. Our approach centers on a multi-agent workflow where collaborative AI agents simulate complex tool-integrated reasoning to generate diverse and high-fidelity data end-to-end. Leveraging this synthesized data, we develop a two-stage training strategy that integrates supervised fine-tuning with a novel reinforcement learning method, designed to maximize model alignment and capability. Extensive experiments demonstrate that our framework empowers open-source models across multiple scales, enabling them to achieve new state-of-the-art performance on the major deep research benchmark. This work provides a scalable and effective pathway for advancing open-source LLMs without relying on proprietary data or models.
Polysemous Language Gaussian Splatting via Matching-based Mask Lifting
Sep 26, 2025Lifting 2D open-vocabulary understanding into 3D Gaussian Splatting (3DGS) scenes is a critical challenge. However, mainstream methods suffer from three key flaws: (i) their reliance on costly per-scene retraining prevents plug-and-play application; (ii) their restrictive monosemous design fails to represent complex, multi-concept semantics; and (iii) their vulnerability to cross-view semantic inconsistencies corrupts the final semantic representation. To overcome these limitations, we introduce MUSplat, a training-free framework that abandons feature optimization entirely. Leveraging a pre-trained 2D segmentation model, our pipeline generates and lifts multi-granularity 2D masks into 3D, where we estimate a foreground probability for each Gaussian point to form initial object groups. We then optimize the ambiguous boundaries of these initial groups using semantic entropy and geometric opacity. Subsequently, by interpreting the object's appearance across its most representative viewpoints, a Vision-Language Model (VLM) distills robust textual features that reconciles visual inconsistencies, enabling open-vocabulary querying via semantic matching. By eliminating the costly per-scene training process, MUSplat reduces scene adaptation time from hours to mere minutes. On benchmark tasks for open-vocabulary 3D object selection and semantic segmentation, MUSplat outperforms established training-based frameworks while simultaneously addressing their monosemous limitations.
Zero-shot Hierarchical Plant Segmentation via Foundation Segmentation Models and Text-to-image Attention
Sep 11, 2025Foundation segmentation models achieve reasonable leaf instance extraction from top-view crop images without training (i.e., zero-shot). However, segmenting entire plant individuals with each consisting of multiple overlapping leaves remains challenging. This problem is referred to as a hierarchical segmentation task, typically requiring annotated training datasets, which are often species-specific and require notable human labor. To address this, we introduce ZeroPlantSeg, a zero-shot segmentation for rosette-shaped plant individuals from top-view images. We integrate a foundation segmentation model, extracting leaf instances, and a vision-language model, reasoning about plants' structures to extract plant individuals without additional training. Evaluations on datasets with multiple plant species, growth stages, and shooting environments demonstrate that our method surpasses existing zero-shot methods and achieves better cross-domain performance than supervised methods. Implementations are available at https://github.com/JunhaoXing/ZeroPlantSeg.
HoGS: Unified Near and Far Object Reconstruction via Homogeneous Gaussian Splatting
Mar 25, 2025



Novel view synthesis has demonstrated impressive progress recently, with 3D Gaussian splatting (3DGS) offering efficient training time and photorealistic real-time rendering. However, reliance on Cartesian coordinates limits 3DGS's performance on distant objects, which is important for reconstructing unbounded outdoor environments. We found that, despite its ultimate simplicity, using homogeneous coordinates, a concept on the projective geometry, for the 3DGS pipeline remarkably improves the rendering accuracies of distant objects. We therefore propose Homogeneous Gaussian Splatting (HoGS) incorporating homogeneous coordinates into the 3DGS framework, providing a unified representation for enhancing near and distant objects. HoGS effectively manages both expansive spatial positions and scales particularly in outdoor unbounded environments by adopting projective geometry principles. Experiments show that HoGS significantly enhances accuracy in reconstructing distant objects while maintaining high-quality rendering of nearby objects, along with fast training speed and real-time rendering capability. Our implementations are available on our project page https://kh129.github.io/hogs/.
Interacted Object Grounding in Spatio-Temporal Human-Object Interactions
Dec 27, 2024



Spatio-temporal Human-Object Interaction (ST-HOI) understanding aims at detecting HOIs from videos, which is crucial for activity understanding. However, existing whole-body-object interaction video benchmarks overlook the truth that open-world objects are diverse, that is, they usually provide limited and predefined object classes. Therefore, we introduce a new open-world benchmark: Grounding Interacted Objects (GIO) including 1,098 interacted objects class and 290K interacted object boxes annotation. Accordingly, an object grounding task is proposed expecting vision systems to discover interacted objects. Even though today's detectors and grounding methods have succeeded greatly, they perform unsatisfactorily in localizing diverse and rare objects in GIO. This profoundly reveals the limitations of current vision systems and poses a great challenge. Thus, we explore leveraging spatio-temporal cues to address object grounding and propose a 4D question-answering framework (4D-QA) to discover interacted objects from diverse videos. Our method demonstrates significant superiority in extensive experiments compared to current baselines. Data and code will be publicly available at https://github.com/DirtyHarryLYL/HAKE-AVA.
Homogeneous Dynamics Space for Heterogeneous Humans
Dec 09, 2024



Analyses of human motion kinematics have achieved tremendous advances. However, the production mechanism, known as human dynamics, is still undercovered. In this paper, we aim to push data-driven human dynamics understanding forward. We identify a major obstacle to this as the heterogeneity of existing human motion understanding efforts. Specifically, heterogeneity exists in not only the diverse kinematics representations and hierarchical dynamics representations but also in the data from different domains, namely biomechanics and reinforcement learning. With an in-depth analysis of the existing heterogeneity, we propose to emphasize the beneath homogeneity: all of them represent the homogeneous fact of human motion, though from different perspectives. Given this, we propose Homogeneous Dynamics Space (HDyS) as a fundamental space for human dynamics by aggregating heterogeneous data and training a homogeneous latent space with inspiration from the inverse-forward dynamics procedure. Leveraging the heterogeneous representations and datasets, HDyS achieves decent mapping between human kinematics and dynamics. We demonstrate the feasibility of HDyS with extensive experiments and applications. The project page is https://foruck.github.io/HDyS.
Verb Mirage: Unveiling and Assessing Verb Concept Hallucinations in Multimodal Large Language Models
Dec 06, 2024



Multimodal Large Language Models (MLLMs) have garnered significant attention recently and demonstrate outstanding capabilities in various tasks such as OCR, VQA, captioning, $\textit{etc}$. However, hallucination remains a persistent issue. While numerous methods have been proposed to mitigate hallucinations, achieving notable improvements, these methods primarily focus on mitigating hallucinations about $\textbf{object/noun-related}$ concepts. Verb concepts, crucial for understanding human actions, have been largely overlooked. In this paper, to the best of our knowledge, we are the $\textbf{first}$ to investigate the $\textbf{verb hallucination}$ phenomenon of MLLMs from various perspectives. Our findings reveal that most state-of-the-art MLLMs suffer from severe verb hallucination. To assess the effectiveness of existing mitigation methods for object concept hallucination on verb hallucination, we evaluated these methods and found that they do not effectively address verb hallucination. To address this issue, we propose a novel rich verb knowledge-based tuning method to mitigate verb hallucination. The experiment results demonstrate that our method significantly reduces hallucinations related to verbs. $\textit{Our code and data will be made publicly available}$.
TreeFormer: Single-view Plant Skeleton Estimation via Tree-constrained Graph Generation
Nov 25, 2024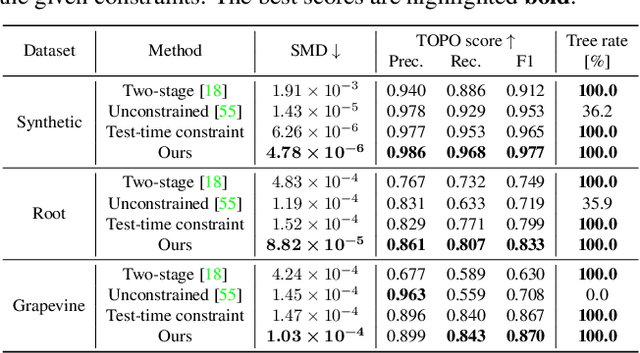
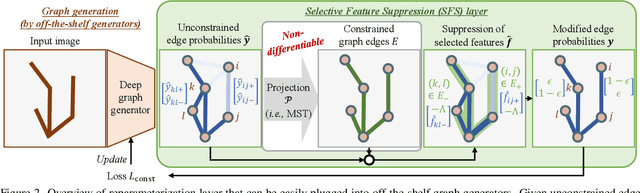
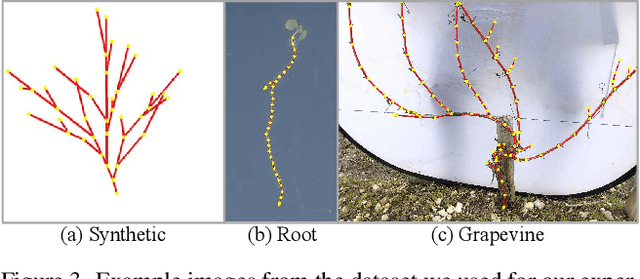
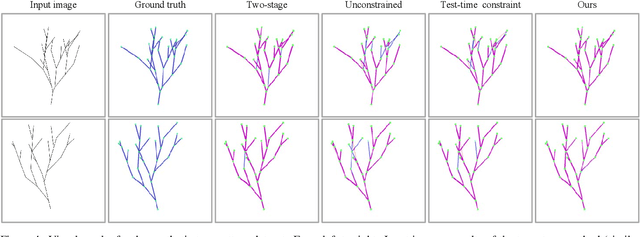
Accurate estimation of plant skeletal structure (e.g., branching structure) from images is essential for smart agriculture and plant science. Unlike human skeletons with fixed topology, plant skeleton estimation presents a unique challenge, i.e., estimating arbitrary tree graphs from images. While recent graph generation methods successfully infer thin structures from images, it is challenging to constrain the output graph strictly to a tree structure. To this problem, we present TreeFormer, a plant skeleton estimator via tree-constrained graph generation. Our approach combines learning-based graph generation with traditional graph algorithms to impose the constraints during the training loop. Specifically, our method projects an unconstrained graph onto a minimum spanning tree (MST) during the training loop and incorporates this prior knowledge into the gradient descent optimization by suppressing unwanted feature values. Experiments show that our method accurately estimates target plant skeletal structures for multiple domains: Synthetic tree patterns, real botanical roots, and grapevine branches. Our implementations are available at https://github.com/huntorochi/TreeFormer/.
ImDy: Human Inverse Dynamics from Imitated Observations
Oct 23, 2024



Inverse dynamics (ID), which aims at reproducing the driven torques from human kinematic observations, has been a critical tool for gait analysis. However, it is hindered from wider application to general motion due to its limited scalability. Conventional optimization-based ID requires expensive laboratory setups, restricting its availability. To alleviate this problem, we propose to exploit the recently progressive human motion imitation algorithms to learn human inverse dynamics in a data-driven manner. The key insight is that the human ID knowledge is implicitly possessed by motion imitators, though not directly applicable. In light of this, we devise an efficient data collection pipeline with state-of-the-art motion imitation algorithms and physics simulators, resulting in a large-scale human inverse dynamics benchmark as Imitated Dynamics (ImDy). ImDy contains over 150 hours of motion with joint torque and full-body ground reaction force data. With ImDy, we train a data-driven human inverse dynamics solver ImDyS(olver) in a fully supervised manner, which conducts ID and ground reaction force estimation simultaneously. Experiments on ImDy and real-world data demonstrate the impressive competency of ImDyS in human inverse dynamics and ground reaction force estimation. Moreover, the potential of ImDy(-S) as a fundamental motion analysis tool is exhibited with downstream applications. The project page is https://foruck.github.io/ImDy/.
Primitive-based 3D Human-Object Interaction Modelling and Programming
Dec 17, 2023



Embedding Human and Articulated Object Interaction (HAOI) in 3D is an important direction for a deeper human activity understanding. Different from previous works that use parametric and CAD models to represent humans and objects, in this work, we propose a novel 3D geometric primitive-based language to encode both humans and objects. Given our new paradigm, humans and objects are all compositions of primitives instead of heterogeneous entities. Thus, mutual information learning may be achieved between the limited 3D data of humans and different object categories. Moreover, considering the simplicity of the expression and the richness of the information it contains, we choose the superquadric as the primitive representation. To explore an effective embedding of HAOI for the machine, we build a new benchmark on 3D HAOI consisting of primitives together with their images and propose a task requiring machines to recover 3D HAOI using primitives from images. Moreover, we propose a baseline of single-view 3D reconstruction on HAOI. We believe this primitive-based 3D HAOI representation would pave the way for 3D HAOI studies. Our code and data are available at https://mvig-rhos.com/p3haoi.