 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDP-SfM: Dual-Pixel Structure-from-Motion without Scale Ambiguity
May 03, 2026Multi-view 3D reconstruction, namely, structure-from-motion followed by multi-view stereo, is a fundamental component of 3D computer vision. In general, multi-view 3D reconstruction suffers from an unknown scale ambiguity unless a reference object of known size is present in the scene. In this article, we show that multi-view images captured using a dual-pixel (DP) sensor can automatically resolve the scale ambiguity, without requiring a reference object or prior calibration. Specifically, the defocus blur observed in DP images provides sufficient information to determine the absolute scale when paired with depth maps (up to scale) recovered from multi-view 3D reconstruction. Based on this observation, we develop a simple yet effective linear method to estimate the absolute scale, followed by the intensity-based optimization stage that aligns the left and right DP images by shifting them back toward each other using cross-view blur kernels. Experiments demonstrate the effectiveness of the proposed approach across diverse scenes captured with different cameras and lenses. Code and data are available at https://github.com/lilika-makabe/dp-sfm-tpami.git
High-fidelity Multi-view Normal Integration with Scale-encoded Neural Surface Representation
Mar 20, 2026Previous multi-view normal integration methods typically sample a single ray per pixel, without considering the spatial area covered by each pixel, which varies with camera intrinsics and the camera-to-object distance. Consequently, when the target object is captured at different distances, the normals at corresponding pixels may differ across views. This multi-view surface normal inconsistency results in the blurring of high-frequency details in the reconstructed surface. To address this issue, we propose a scale-encoded neural surface representation that incorporates the pixel coverage area into the neural representation. By associating each 3D point with a spatial scale and calculating its normal from a hybrid grid-based encoding, our method effectively represents multi-scale surface normals captured at varying distances. Furthermore, to enable scale-aware surface reconstruction, we introduce a mesh extraction module that assigns an optimal local scale to each vertex based on the training observations. Experimental results demonstrate that our approach consistently yields high-fidelity surface reconstruction from normals observed at varying distances, outperforming existing multi-view normal integration methods.
Near-light Photometric Stereo with Symmetric Lights
Mar 17, 2026This paper describes a linear solution method for near-light photometric stereo by exploiting symmetric light source arrangements. Unlike conventional non-convex optimization approaches, by arranging multiple sets of symmetric nearby light source pairs, our method derives a closed-form solution for surface normal and depth without requiring initialization. In addition, our method works as long as the light sources are symmetrically distributed about an arbitrary point even when the entire spatial offset is uncalibrated. Experiments showcase the accuracy of shape recovery accuracy of our method, achieving comparable results to the state-of-the-art calibrated near-light photometric stereo method while significantly reducing requirements of careful depth initialization and light calibration.
Spectral Sensitivity Estimation with an Uncalibrated Diffraction Grating
Aug 01, 2025This paper introduces a practical and accurate calibration method for camera spectral sensitivity using a diffraction grating. Accurate calibration of camera spectral sensitivity is crucial for various computer vision tasks, including color correction, illumination estimation, and material analysis. Unlike existing approaches that require specialized narrow-band filters or reference targets with known spectral reflectances, our method only requires an uncalibrated diffraction grating sheet, readily available off-the-shelf. By capturing images of the direct illumination and its diffracted pattern through the grating sheet, our method estimates both the camera spectral sensitivity and the diffraction grating parameters in a closed-form manner. Experiments on synthetic and real-world data demonstrate that our method outperforms conventional reference target-based methods, underscoring its effectiveness and practicality.
HoGS: Unified Near and Far Object Reconstruction via Homogeneous Gaussian Splatting
Mar 25, 2025



Novel view synthesis has demonstrated impressive progress recently, with 3D Gaussian splatting (3DGS) offering efficient training time and photorealistic real-time rendering. However, reliance on Cartesian coordinates limits 3DGS's performance on distant objects, which is important for reconstructing unbounded outdoor environments. We found that, despite its ultimate simplicity, using homogeneous coordinates, a concept on the projective geometry, for the 3DGS pipeline remarkably improves the rendering accuracies of distant objects. We therefore propose Homogeneous Gaussian Splatting (HoGS) incorporating homogeneous coordinates into the 3DGS framework, providing a unified representation for enhancing near and distant objects. HoGS effectively manages both expansive spatial positions and scales particularly in outdoor unbounded environments by adopting projective geometry principles. Experiments show that HoGS significantly enhances accuracy in reconstructing distant objects while maintaining high-quality rendering of nearby objects, along with fast training speed and real-time rendering capability. Our implementations are available on our project page https://kh129.github.io/hogs/.
Shadow Art Kanji: Inverse Rendering Application
Mar 15, 2025Finding a balance between artistic beauty and machine-generated imagery is always a difficult task. This project seeks to create 3D models that, when illuminated, cast shadows resembling Kanji characters. It aims to combine artistic expression with computational techniques, providing an accurate and efficient approach to visualizing these Japanese characters through shadows.
Multi-View Azimuth Stereo via Tangent Space Consistency
Mar 29, 2023We present a method for 3D reconstruction only using calibrated multi-view surface azimuth maps. Our method, multi-view azimuth stereo, is effective for textureless or specular surfaces, which are difficult for conventional multi-view stereo methods. We introduce the concept of tangent space consistency: Multi-view azimuth observations of a surface point should be lifted to the same tangent space. Leveraging this consistency, we recover the shape by optimizing a neural implicit surface representation. Our method harnesses the robust azimuth estimation capabilities of photometric stereo methods or polarization imaging while bypassing potentially complex zenith angle estimation. Experiments using azimuth maps from various sources validate the accurate shape recovery with our method, even without zenith angles.
Edge-preserving Near-light Photometric Stereo with Neural Surfaces
Jul 11, 2022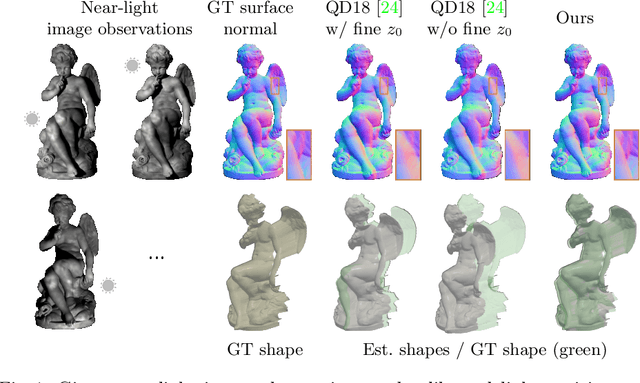
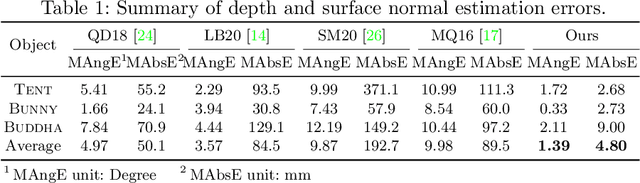
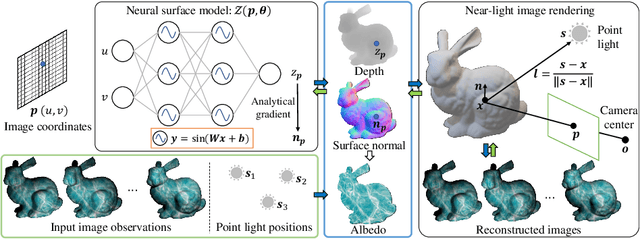
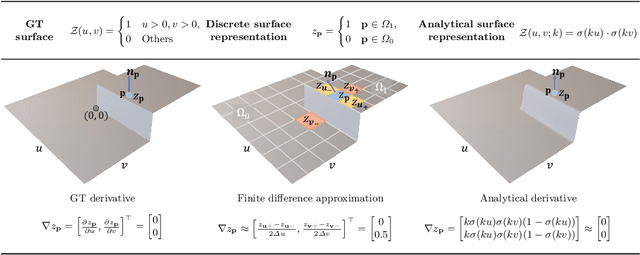
This paper presents a near-light photometric stereo method that faithfully preserves sharp depth edges in the 3D reconstruction. Unlike previous methods that rely on finite differentiation for approximating depth partial derivatives and surface normals, we introduce an analytically differentiable neural surface in near-light photometric stereo for avoiding differentiation errors at sharp depth edges, where the depth is represented as a neural function of the image coordinates. By further formulating the Lambertian albedo as a dependent variable resulting from the surface normal and depth, our method is insusceptible to inaccurate depth initialization. Experiments on both synthetic and real-world scenes demonstrate the effectiveness of our method for detailed shape recovery with edge preservation.
Lighting, Reflectance and Geometry Estimation from 360$^{\circ}$ Panoramic Stereo
Apr 20, 2021

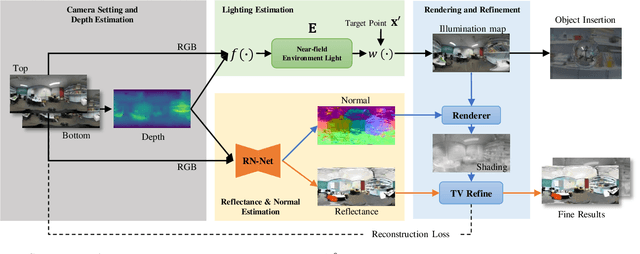
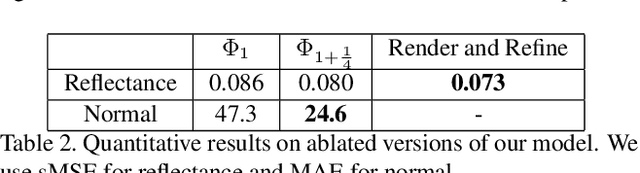
We propose a method for estimating high-definition spatially-varying lighting, reflectance, and geometry of a scene from 360$^{\circ}$ stereo images. Our model takes advantage of the 360$^{\circ}$ input to observe the entire scene with geometric detail, then jointly estimates the scene's properties with physical constraints. We first reconstruct a near-field environment light for predicting the lighting at any 3D location within the scene. Then we present a deep learning model that leverages the stereo information to infer the reflectance and surface normal. Lastly, we incorporate the physical constraints between lighting and geometry to refine the reflectance of the scene. Both quantitative and qualitative experiments show that our method, benefiting from the 360$^{\circ}$ observation of the scene, outperforms prior state-of-the-art methods and enables more augmented reality applications such as mirror-objects insertion.
Descriptor-Free Multi-View Region Matching for Instance-Wise 3D Reconstruction
Nov 27, 2020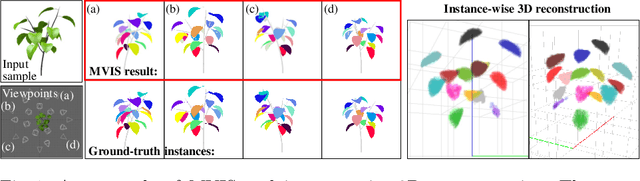


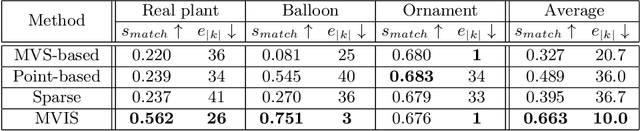
This paper proposes a multi-view extension of instance segmentation without relying on texture or shape descriptor matching. Multi-view instance segmentation becomes challenging for scenes with repetitive textures and shapes, e.g., plant leaves, due to the difficulty of multi-view matching using texture or shape descriptors. To this end, we propose a multi-view region matching method based on epipolar geometry, which does not rely on any feature descriptors. We further show that the epipolar region matching can be easily integrated into instance segmentation and effective for instance-wise 3D reconstruction. Experiments demonstrate the improved accuracy of multi-view instance matching and the 3D reconstruction compared to the baseline methods.